 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslation Memory Retrieval Methods
May 21, 2015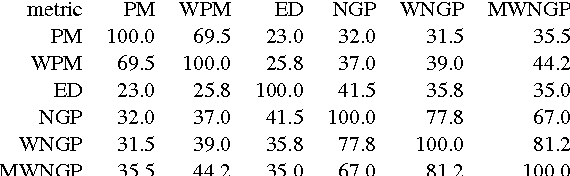
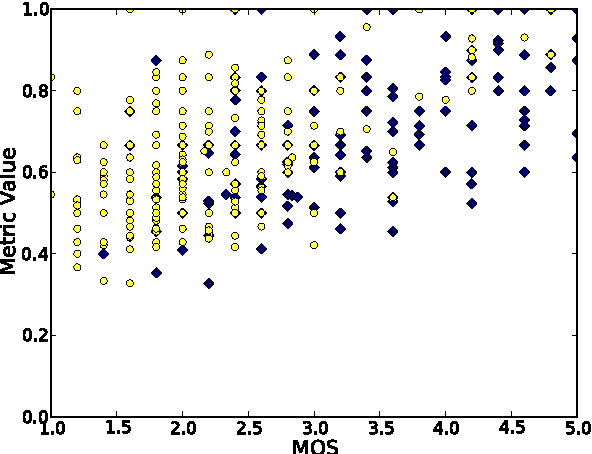
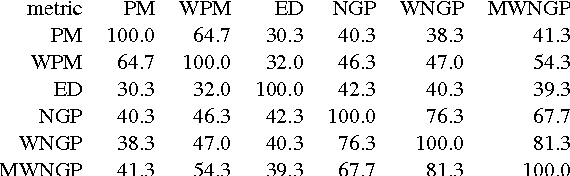
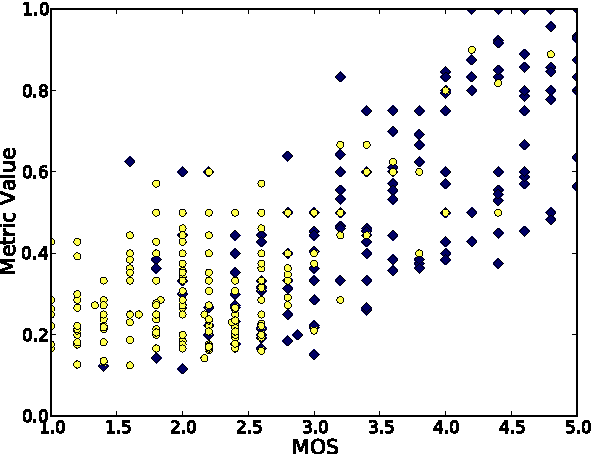
Translation Memory (TM) systems are one of the most widely used translation technologies. An important part of TM systems is the matching algorithm that determines what translations get retrieved from the bank of available translations to assist the human translator. Although detailed accounts of the matching algorithms used in commercial systems can't be found in the literature, it is widely believed that edit distance algorithms are used. This paper investigates and evaluates the use of several matching algorithms, including the edit distance algorithm that is believed to be at the heart of most modern commercial TM systems. This paper presents results showing how well various matching algorithms correlate with human judgments of helpfulness (collected via crowdsourcing with Amazon's Mechanical Turk). A new algorithm based on weighted n-gram precision that can be adjusted for translator length preferences consistently returns translations judged to be most helpful by translators for multiple domains and language pairs.
* 9 pages, 6 tables, 3 figures; appeared in Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, April 2014
Analysis of Stopping Active Learning based on Stabilizing Predictions
Apr 23, 2015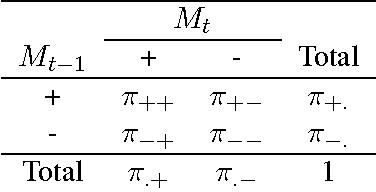
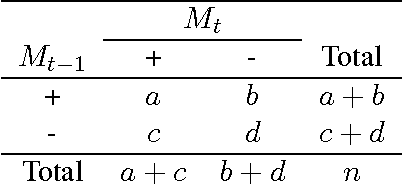
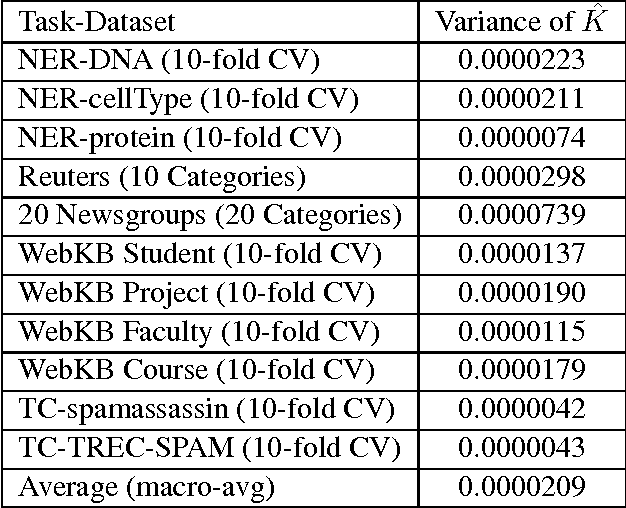
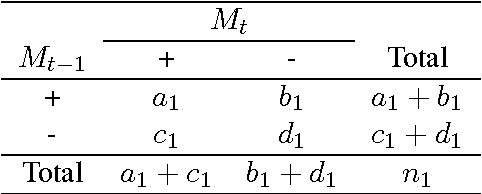
Within the natural language processing (NLP) community, active learning has been widely investigated and applied in order to alleviate the annotation bottleneck faced by developers of new NLP systems and technologies. This paper presents the first theoretical analysis of stopping active learning based on stabilizing predictions (SP). The analysis has revealed three elements that are central to the success of the SP method: (1) bounds on Cohen's Kappa agreement between successively trained models impose bounds on differences in F-measure performance of the models; (2) since the stop set does not have to be labeled, it can be made large in practice, helping to guarantee that the results transfer to previously unseen streams of examples at test/application time; and (3) good (low variance) sample estimates of Kappa between successive models can be obtained. Proofs of relationships between the level of Kappa agreement and the difference in performance between consecutive models are presented. Specifically, if the Kappa agreement between two models exceeds a threshold T (where $T>0$), then the difference in F-measure performance between those models is bounded above by $\frac{4(1-T)}{T}$ in all cases. If precision of the positive conjunction of the models is assumed to be $p$, then the bound can be tightened to $\frac{4(1-T)}{(p+1)T}$.
* 10 pages, 8 tables; appeared in Proceedings of the Seventeenth Conference on Computational Natural Language Learning, August 2013
Statistical modality tagging from rule-based annotations and crowdsourcing
Mar 04, 2015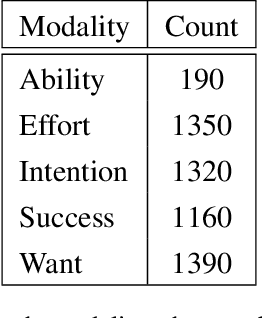
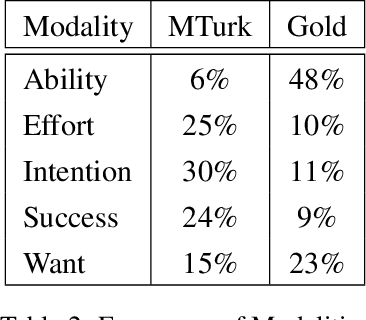
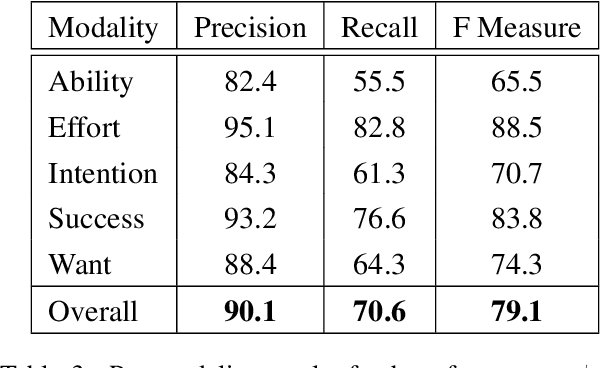
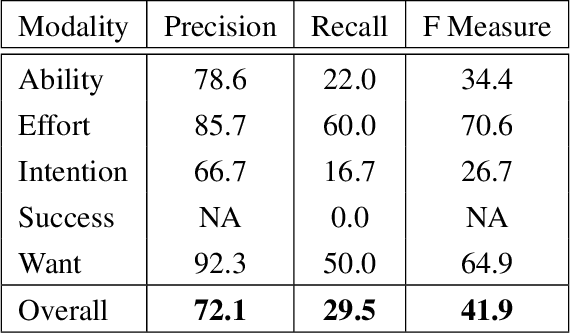
We explore training an automatic modality tagger. Modality is the attitude that a speaker might have toward an event or state. One of the main hurdles for training a linguistic tagger is gathering training data. This is particularly problematic for training a tagger for modality because modality triggers are sparse for the overwhelming majority of sentences. We investigate an approach to automatically training a modality tagger where we first gathered sentences based on a high-recall simple rule-based modality tagger and then provided these sentences to Mechanical Turk annotators for further annotation. We used the resulting set of training data to train a precise modality tagger using a multi-class SVM that delivers good performance.
* 8 pages, 6 tables; appeared in Proceedings of the Workshop on Extra-Propositional Aspects of Meaning in Computational Linguistics, July 2012; In Proceedings of the Workshop on Extra-Propositional Aspects of Meaning in Computational Linguistics, pages 57-64, Jeju, Republic of Korea, July 2012. Association for Computational Linguistics
Use of Modality and Negation in Semantically-Informed Syntactic MT
Feb 05, 2015This paper describes the resource- and system-building efforts of an eight-week Johns Hopkins University Human Language Technology Center of Excellence Summer Camp for Applied Language Exploration (SCALE-2009) on Semantically-Informed Machine Translation (SIMT). We describe a new modality/negation (MN) annotation scheme, the creation of a (publicly available) MN lexicon, and two automated MN taggers that we built using the annotation scheme and lexicon. Our annotation scheme isolates three components of modality and negation: a trigger (a word that conveys modality or negation), a target (an action associated with modality or negation) and a holder (an experiencer of modality). We describe how our MN lexicon was semi-automatically produced and we demonstrate that a structure-based MN tagger results in precision around 86% (depending on genre) for tagging of a standard LDC data set. We apply our MN annotation scheme to statistical machine translation using a syntactic framework that supports the inclusion of semantic annotations. Syntactic tags enriched with semantic annotations are assigned to parse trees in the target-language training texts through a process of tree grafting. While the focus of our work is modality and negation, the tree grafting procedure is general and supports other types of semantic information. We exploit this capability by including named entities, produced by a pre-existing tagger, in addition to the MN elements produced by the taggers described in this paper. The resulting system significantly outperformed a linguistically naive baseline model (Hiero), and reached the highest scores yet reported on the NIST 2009 Urdu-English test set. This finding supports the hypothesis that both syntactic and semantic information can improve translation quality.
* 28 pages, 13 figures, 2 tables; appeared in Computational Linguistics, 38(2):411-438, 2012
Annotating Cognates and Etymological Origin in Turkic Languages
Jan 13, 2015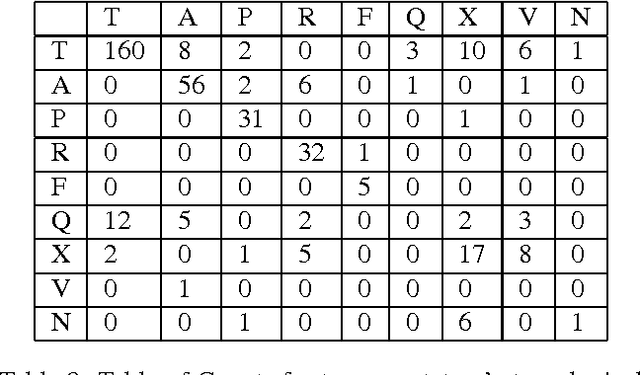
Turkic languages exhibit extensive and diverse etymological relationships among lexical items. These relationships make the Turkic languages promising for exploring automated translation lexicon induction by leveraging cognate and other etymological information. However, due to the extent and diversity of the types of relationships between words, it is not clear how to annotate such information. In this paper, we present a methodology for annotating cognates and etymological origin in Turkic languages. Our method strives to balance the amount of research effort the annotator expends with the utility of the annotations for supporting research on improving automated translation lexicon induction.
* 5 pages, 8 tables; appeared in Proceedings of the First Workshop on Language Resources and Technologies for Turkic Languages at the Eighth International Conference on Language Resources and Evaluation (LREC'12), pages 47-51, Istanbul, Turkey, May 2012. European Language Resources Association
Rapid Adaptation of POS Tagging for Domain Specific Uses
Oct 31, 2014Part-of-speech (POS) tagging is a fundamental component for performing natural language tasks such as parsing, information extraction, and question answering. When POS taggers are trained in one domain and applied in significantly different domains, their performance can degrade dramatically. We present a methodology for rapid adaptation of POS taggers to new domains. Our technique is unsupervised in that a manually annotated corpus for the new domain is not necessary. We use suffix information gathered from large amounts of raw text as well as orthographic information to increase the lexical coverage. We present an experiment in the Biological domain where our POS tagger achieves results comparable to POS taggers specifically trained to this domain.
* 2 pages, 2 tables; appeared in Proceedings of the HLT-NAACL BioNLP Workshop on Linking Natural Language and Biology, June 2006
A random forest system combination approach for error detection in digital dictionaries
Oct 30, 2014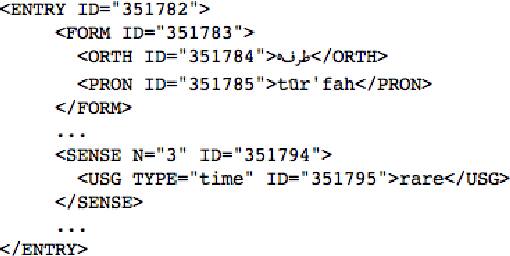
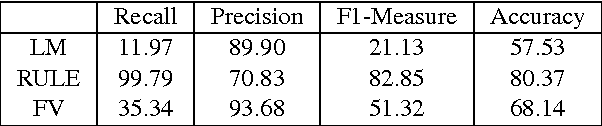
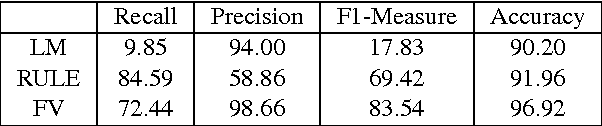
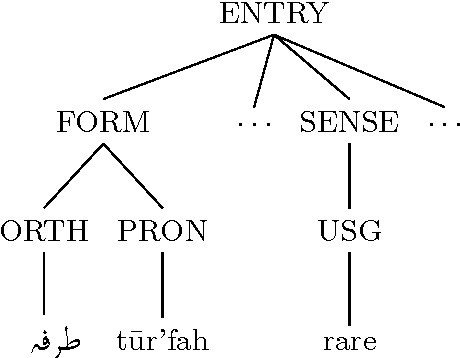
When digitizing a print bilingual dictionary, whether via optical character recognition or manual entry, it is inevitable that errors are introduced into the electronic version that is created. We investigate automating the process of detecting errors in an XML representation of a digitized print dictionary using a hybrid approach that combines rule-based, feature-based, and language model-based methods. We investigate combining methods and show that using random forests is a promising approach. We find that in isolation, unsupervised methods rival the performance of supervised methods. Random forests typically require training data so we investigate how we can apply random forests to combine individual base methods that are themselves unsupervised without requiring large amounts of training data. Experiments reveal empirically that a relatively small amount of data is sufficient and can potentially be further reduced through specific selection criteria.
* 9 pages, 7 figures, 10 tables; appeared in Proceedings of the Workshop on Innovative Hybrid Approaches to the Processing of Textual Data, April 2012
Detecting Structural Irregularity in Electronic Dictionaries Using Language Modeling
Oct 29, 2014


Dictionaries are often developed using tools that save to Extensible Markup Language (XML)-based standards. These standards often allow high-level repeating elements to represent lexical entries, and utilize descendants of these repeating elements to represent the structure within each lexical entry, in the form of an XML tree. In many cases, dictionaries are published that have errors and inconsistencies that are expensive to find manually. This paper discusses a method for dictionary writers to quickly audit structural regularity across entries in a dictionary by using statistical language modeling. The approach learns the patterns of XML nodes that could occur within an XML tree, and then calculates the probability of each XML tree in the dictionary against these patterns to look for entries that diverge from the norm.
* 6 pages, 2 figures, 11 tables; appeared in Proceedings of Electronic Lexicography in the 21st Century (eLex), November 2011
Correcting Errors in Digital Lexicographic Resources Using a Dictionary Manipulation Language
Oct 28, 2014
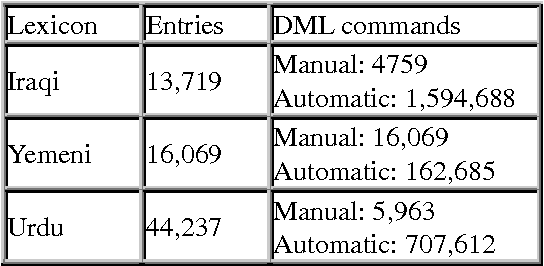

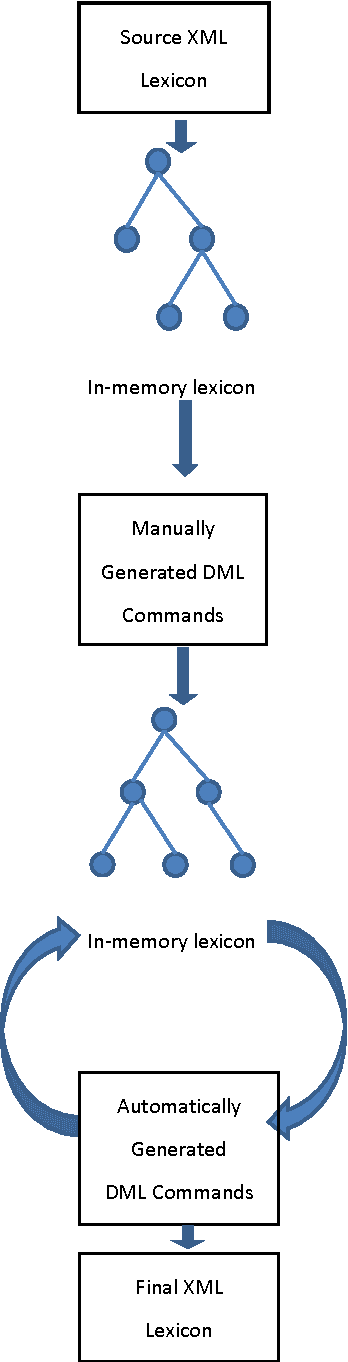
We describe a paradigm for combining manual and automatic error correction of noisy structured lexicographic data. Modifications to the structure and underlying text of the lexicographic data are expressed in a simple, interpreted programming language. Dictionary Manipulation Language (DML) commands identify nodes by unique identifiers, and manipulations are performed using simple commands such as create, move, set text, etc. Corrected lexicons are produced by applying sequences of DML commands to the source version of the lexicon. DML commands can be written manually to repair one-off errors or generated automatically to correct recurring problems. We discuss advantages of the paradigm for the task of editing digital bilingual dictionaries.
* 5 pages, 3 figures, 1 table; appeared in Proceedings of Electronic Lexicography in the 21st Century (eLex), November 2011
Bucking the Trend: Large-Scale Cost-Focused Active Learning for Statistical Machine Translation
Oct 21, 2014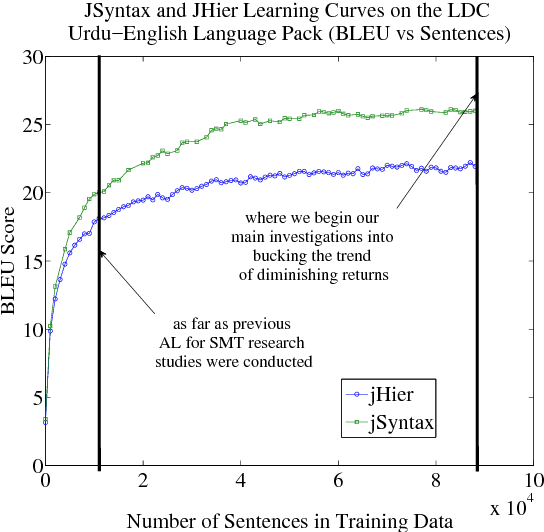
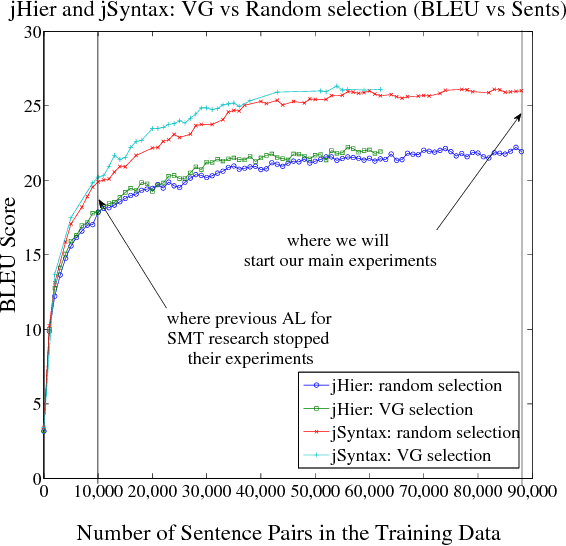
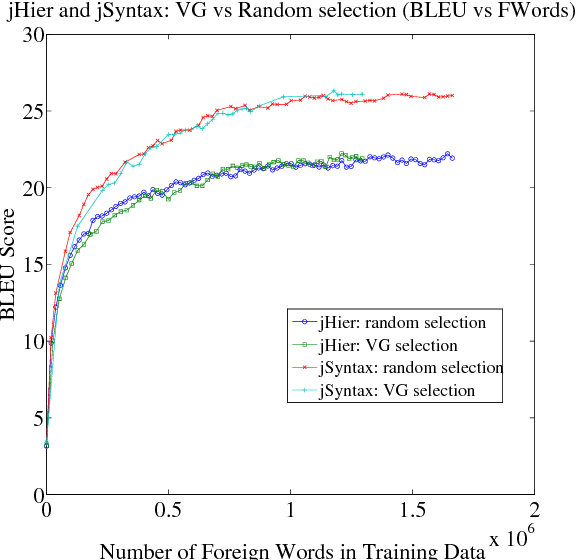
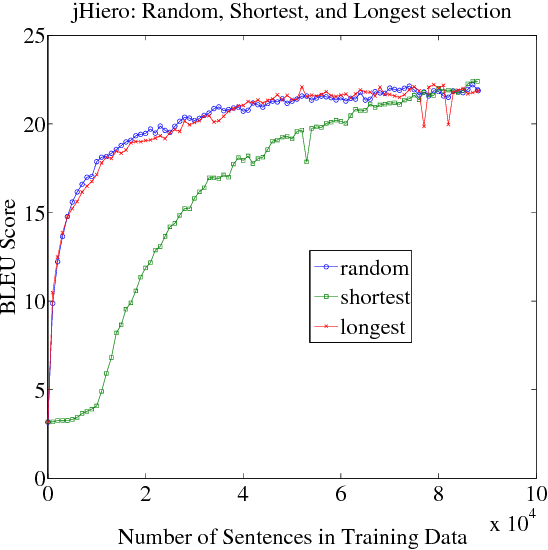
We explore how to improve machine translation systems by adding more translation data in situations where we already have substantial resources. The main challenge is how to buck the trend of diminishing returns that is commonly encountered. We present an active learning-style data solicitation algorithm to meet this challenge. We test it, gathering annotations via Amazon Mechanical Turk, and find that we get an order of magnitude increase in performance rates of improvement.
* 11 pages, 14 figures; appeared in Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, July 2010