 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost Volume Pyramid Based Depth Inference for Multi-View Stereo
Dec 18, 2019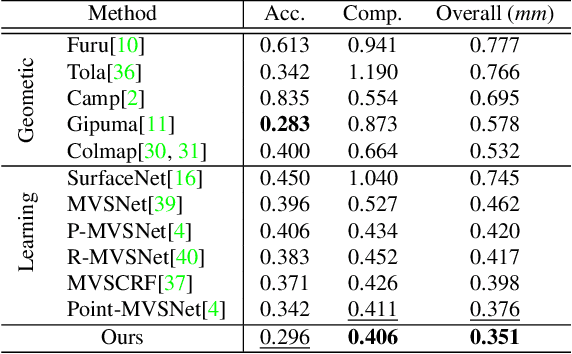
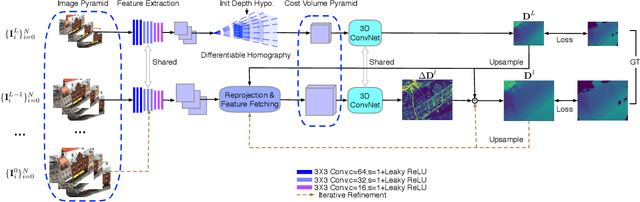
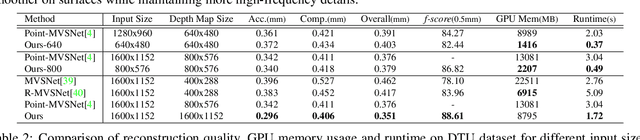
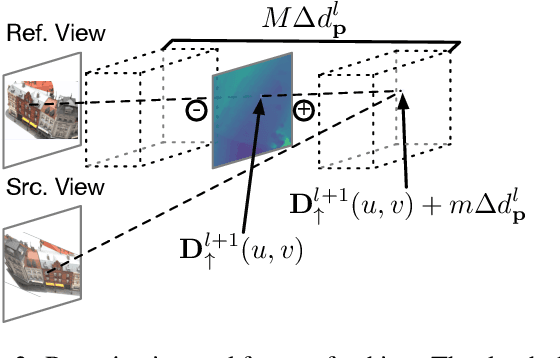
We propose a cost volume based neural network for depth inference from multi-view images. We demonstrate that building a cost volume pyramid in a coarse-to-fine manner instead of constructing a cost volume at a fixed resolution leads to a compact, lightweight network and allows us inferring high resolution depth maps to achieve better reconstruction results. To this end, a cost volume based on uniform sampling of fronto-parallel planes across entire depth range is first built at the coarsest resolution of an image. Given current depth estimate, new cost volumes are constructed iteratively on the pixelwise depth residual to perform depth map refinement. While sharing similar insight with Point-MVSNet as predicting and refining depth iteratively, we show that working on cost volume pyramid can lead to a more compact, yet efficient network structure compared with the Point-MVSNet on 3D points. We further provide detailed analyses of relation between (residual) depth sampling and image resolution, which serves as a principle for building compact cost volume pyramid. Experimental results on benchmark datasets show that our model can perform 6x faster and has similar performance as state-of-the-art methods.
Joint Stereo Video Deblurring, Scene Flow Estimation and Moving Object Segmentation
Oct 06, 2019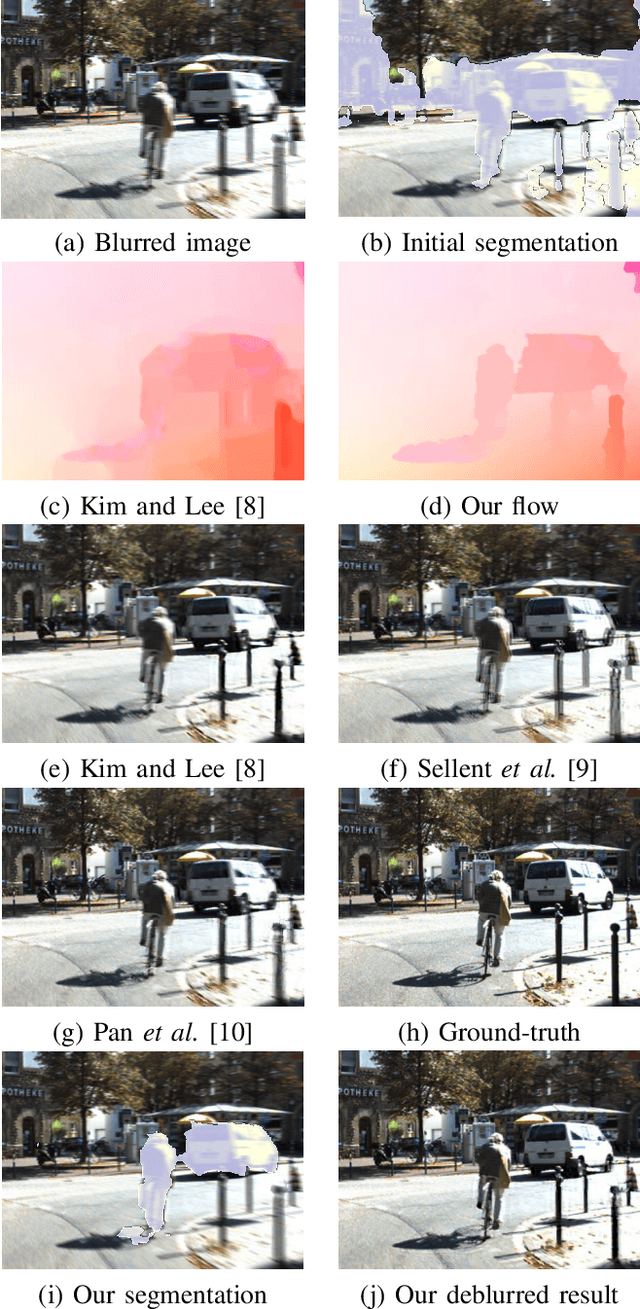
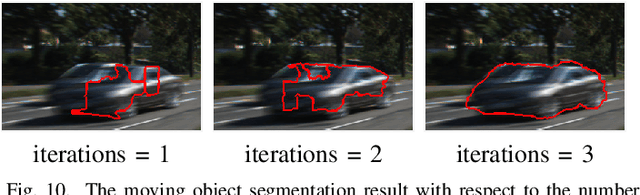


Stereo videos for the dynamic scenes often show unpleasant blurred effects due to the camera motion and the multiple moving objects with large depth variations. Given consecutive blurred stereo video frames, we aim to recover the latent clean images, estimate the 3D scene flow and segment the multiple moving objects. These three tasks have been previously addressed separately, which fail to exploit the internal connections among these tasks and cannot achieve optimality. In this paper, we propose to jointly solve these three tasks in a unified framework by exploiting their intrinsic connections. To this end, we represent the dynamic scenes with the piece-wise planar model, which exploits the local structure of the scene and expresses various dynamic scenes. Under our model, these three tasks are naturally connected and expressed as the parameter estimation of 3D scene structure and camera motion (structure and motion for the dynamic scenes). By exploiting the blur model constraint, the moving objects and the 3D scene structure, we reach an energy minimization formulation for joint deblurring, scene flow and segmentation. We evaluate our approach extensively on both synthetic datasets and publicly available real datasets with fast-moving objects, camera motion, uncontrolled lighting conditions and shadows. Experimental results demonstrate that our method can achieve significant improvement in stereo video deblurring, scene flow estimation and moving object segmentation, over state-of-the-art methods.
Learning Trajectory Dependencies for Human Motion Prediction
Aug 16, 2019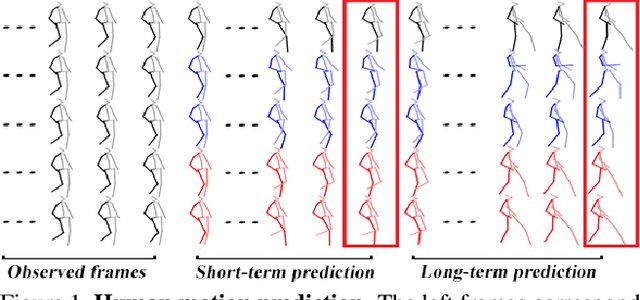
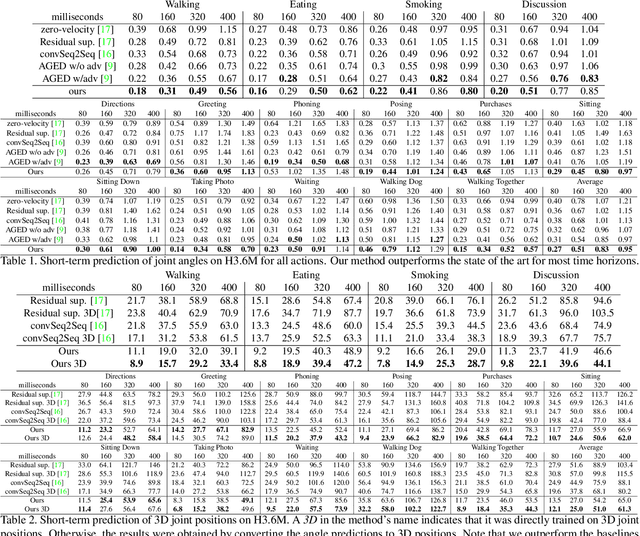

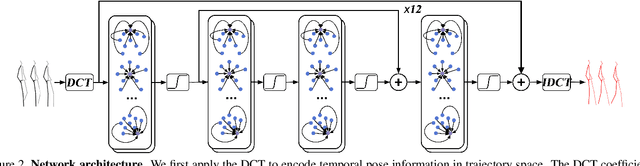
Human motion prediction, i.e., forecasting future body poses given observed pose sequence, has typically been tackled with recurrent neural networks (RNNs). However, as evidenced by prior work, the resulted RNN models suffer from prediction errors accumulation, leading to undesired discontinuities in motion prediction. In this paper, we propose a simple feed-forward deep network for motion prediction, which takes into account both temporal smoothness and spatial dependencies among human body joints. In this context, we then propose to encode temporal information by working in trajectory space, instead of the traditionally-used pose space. This alleviates us from manually defining the range of temporal dependencies (or temporal convolutional filter size, as done in previous work). Moreover, spatial dependency of human pose is encoded by treating a human pose as a generic graph (rather than a human skeletal kinematic tree) formed by links between every pair of body joints. Instead of using a pre-defined graph structure, we design a new graph convolutional network to learn graph connectivity automatically. This allows the network to capture long range dependencies beyond that of human kinematic tree. We evaluate our approach on several standard benchmark datasets for motion prediction, including Human3.6M, the CMU motion capture dataset and 3DPW. Our experiments clearly demonstrate that the proposed approach achieves state of the art performance, and is applicable to both angle-based and position-based pose representations. The code is available at https://github.com/wei-mao-2019/LearnTrajDep
Bringing Blurry Alive at High Frame-Rate with an Event Camera
Mar 12, 2019
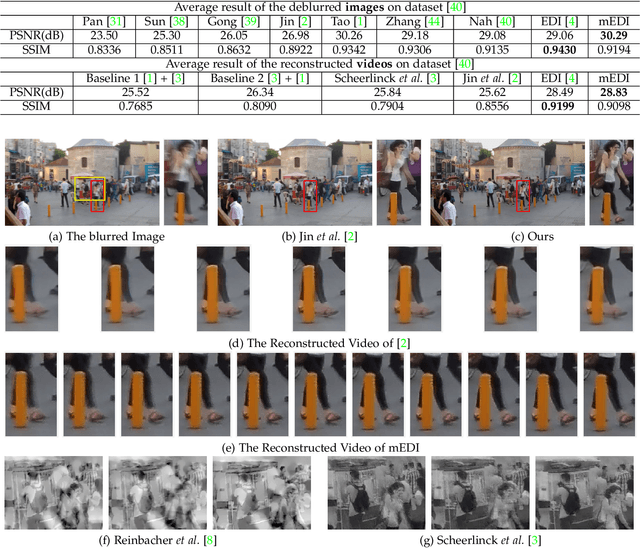
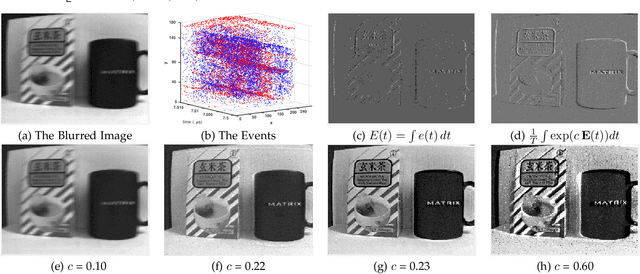

Event-based cameras can measure intensity changes (called `{\it events}') with microsecond accuracy under high-speed motion and challenging lighting conditions. With the active pixel sensor (APS), the event camera allows simultaneous output of the intensity frames. However, the output images are captured at a relatively low frame-rate and often suffer from motion blur. A blurry image can be regarded as the integral of a sequence of latent images, while the events indicate the changes between the latent images. Therefore, we are able to model the blur-generation process by associating event data to a latent image. Based on the abundant event data and the low frame-rate easily blurred images, we propose a simple and effective approach to reconstruct a high-quality and high frame-rate shape video. Starting with a single blurry frame and its event data, we propose the \textbf{Event-based Double Integral (EDI)} model. Then, we extend it to \textbf{ multiple Event-based Double Integral (mEDI)} model to get more smooth and convincing results based on multiple images and their events. We also provide an efficient solver to minimize the proposed energy model. By optimizing the energy model, we achieve significant improvements in removing general blurs and reconstructing high temporal resolution video. The video generation is based on solving a simple non-convex optimization problem in a single scalar variable. Experimental results on both synthetic and real images demonstrate the superiority of our mEDI model and optimization method in comparison to the state-of-the-art.
Single Image Deblurring and Camera Motion Estimation with Depth Map
Mar 01, 2019
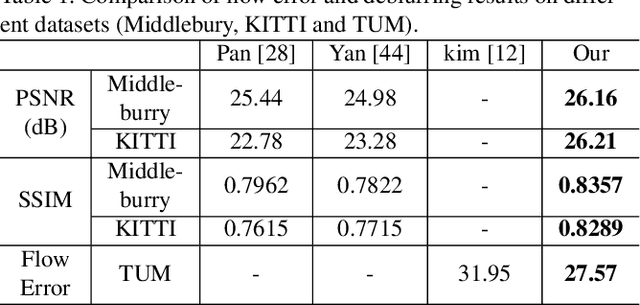
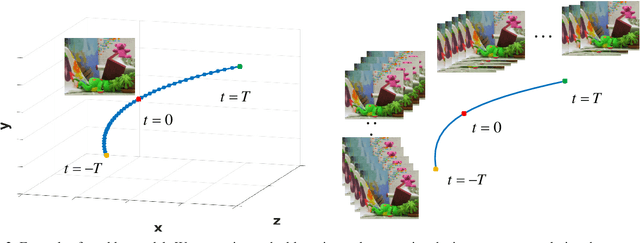

Camera shake during exposure is a major problem in hand-held photography, as it causes image blur that destroys details in the captured images.~In the real world, such blur is mainly caused by both the camera motion and the complex scene structure.~While considerable existing approaches have been proposed based on various assumptions regarding the scene structure or the camera motion, few existing methods could handle the real 6 DoF camera motion.~In this paper, we propose to jointly estimate the 6 DoF camera motion and remove the non-uniform blur caused by camera motion by exploiting their underlying geometric relationships, with a single blurry image and its depth map (either direct depth measurements, or a learned depth map) as input.~We formulate our joint deblurring and 6 DoF camera motion estimation as an energy minimization problem which is solved in an alternative manner. Our model enables the recovery of the 6 DoF camera motion and the latent clean image, which could also achieve the goal of generating a sharp sequence from a single blurry image. Experiments on challenging real-world and synthetic datasets demonstrate that image blur from camera shake can be well addressed within our proposed framework.
Bringing a Blurry Frame Alive at High Frame-Rate with an Event Camera
Nov 27, 2018
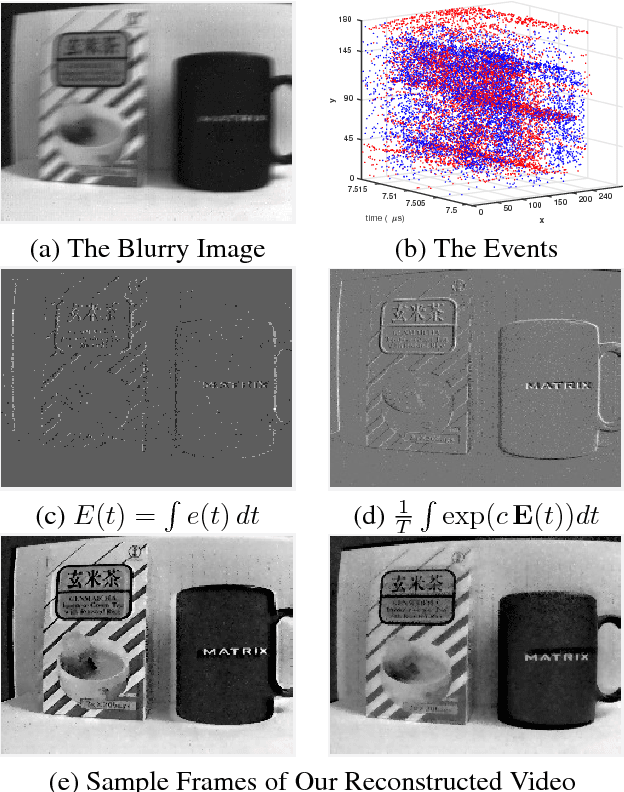

Event-based cameras can measure intensity changes (called `{\it events}') with microsecond accuracy under high-speed motion and challenging lighting conditions. With the active pixel sensor (APS), the event camera allows simultaneous output of the intensity frames. However, the output images are captured at a relatively low frame-rate and often suffer from motion blur. A blurry image can be regarded as the integral of a sequence of latent images, while the events indicate the changes between the latent images. Therefore, we are able to model the blur-generation process by associating event data to a latent image. In this paper, we propose a simple and effective approach, the \textbf{Event-based Double Integral (EDI)} model, to reconstruct a high frame-rate, sharp video from a single blurry frame and its event data. The video generation is based on solving a simple non-convex optimization problem in a single scalar variable. Experimental results on both synthetic and real images demonstrate the superiority of our EDI model and optimization method in comparison to the state-of-the-art.
Phase-only Image Based Kernel Estimation for Single-image Blind Deblurring
Nov 27, 2018
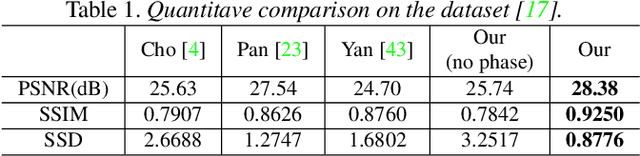


The image blurring process is generally modelled as the convolution of a blur kernel with a latent image. Therefore, the estimation of the blur kernel is essentially important for blind image deblurring. Unlike existing approaches which focus on approaching the problem by enforcing various priors on the blur kernel and the latent image, we are aiming at obtaining a high quality blur kernel directly by studying the problem in the frequency domain. We show that the auto-correlation of the absolute phase-only image can provide faithful information about the motion (e.g. the motion direction and magnitude, we call it the motion pattern in this paper.) that caused the blur, leading to a new and efficient blur kernel estimation approach. The blur kernel is then refined and the sharp image is estimated by solving an optimization problem by enforcing a regularization on the blur kernel and the latent image. We further extend our approach to handle non-uniform blur, which involves spatially varying blur kernels. Our approach is evaluated extensively on synthetic and real data and shows good results compared to the state-of-the-art deblurring approaches.
Geometry-aware Deep Network for Single-Image Novel View Synthesis
Apr 17, 2018
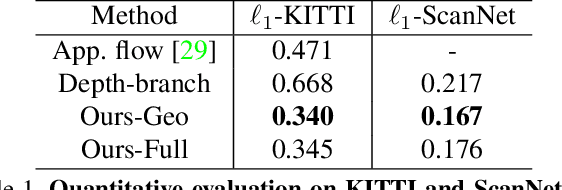
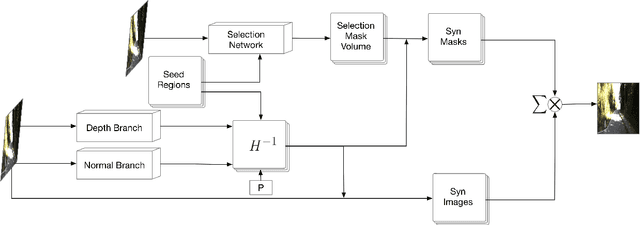
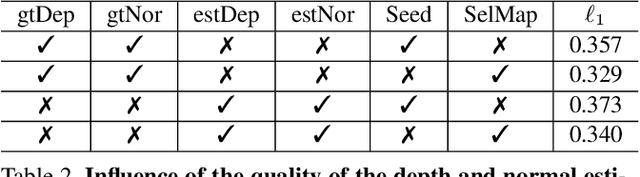
This paper tackles the problem of novel view synthesis from a single image. In particular, we target real-world scenes with rich geometric structure, a challenging task due to the large appearance variations of such scenes and the lack of simple 3D models to represent them. Modern, learning-based approaches mostly focus on appearance to synthesize novel views and thus tend to generate predictions that are inconsistent with the underlying scene structure. By contrast, in this paper, we propose to exploit the 3D geometry of the scene to synthesize a novel view. Specifically, we approximate a real-world scene by a fixed number of planes, and learn to predict a set of homographies and their corresponding region masks to transform the input image into a novel view. To this end, we develop a new region-aware geometric transform network that performs these multiple tasks in a common framework. Our results on the outdoor KITTI and the indoor ScanNet datasets demonstrate the effectiveness of our network in generating high quality synthetic views that respect the scene geometry, thus outperforming the state-of-the-art methods.
Depth Map Completion by Jointly Exploiting Blurry Color Images and Sparse Depth Maps
Nov 27, 2017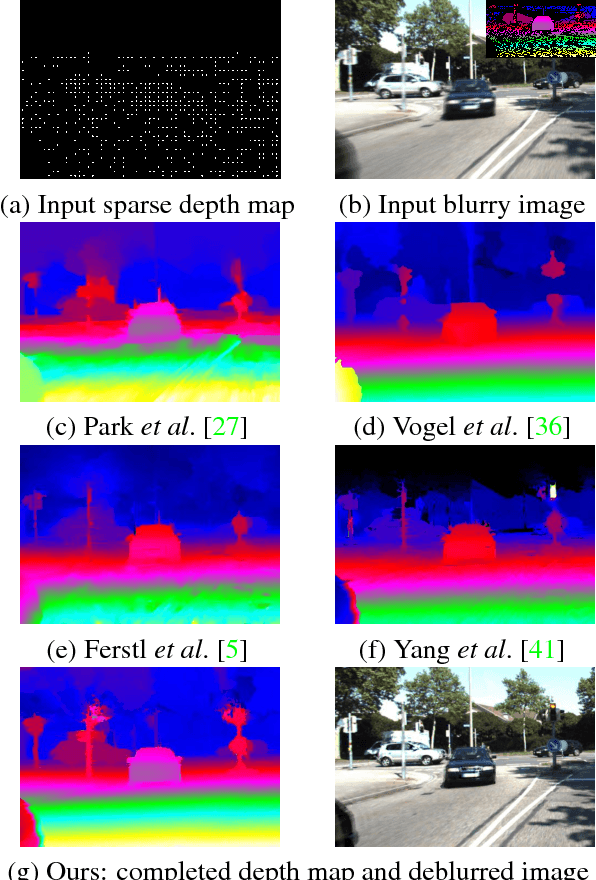

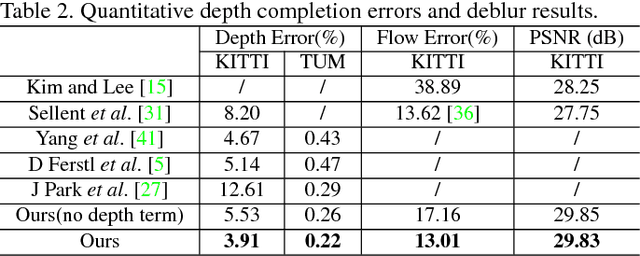

We aim at predicting a complete and high-resolution depth map from incomplete, sparse and noisy depth measurements. Existing methods handle this problem either by exploiting various regularizations on the depth maps directly or resorting to learning based methods. When the corresponding color images are available, the correlation between the depth maps and the color images are used to improve the completion performance, assuming the color images are clean and sharp. However, in real world dynamic scenes, color images are often blurry due to the camera motion and the moving objects in the scene. In this paper, we propose to tackle the problem of depth map completion by jointly exploiting the blurry color image sequences and the sparse depth map measurements, and present an energy minimization based formulation to simultaneously complete the depth maps, estimate the scene flow and deblur the color images. Our experimental evaluations on both outdoor and indoor scenarios demonstrate the state-of-the-art performance of our approach.
Simultaneous Stereo Video Deblurring and Scene Flow Estimation
Apr 11, 2017
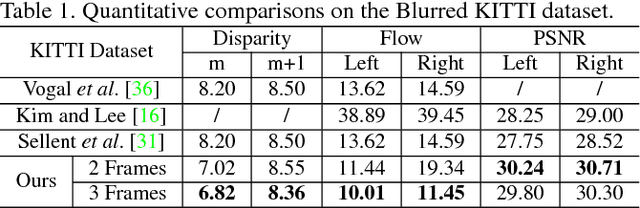

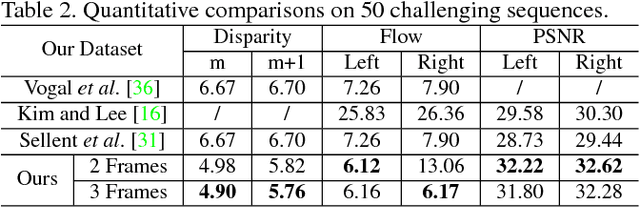
Videos for outdoor scene often show unpleasant blur effects due to the large relative motion between the camera and the dynamic objects and large depth variations. Existing works typically focus monocular video deblurring. In this paper, we propose a novel approach to deblurring from stereo videos. In particular, we exploit the piece-wise planar assumption about the scene and leverage the scene flow information to deblur the image. Unlike the existing approach [31] which used a pre-computed scene flow, we propose a single framework to jointly estimate the scene flow and deblur the image, where the motion cues from scene flow estimation and blur information could reinforce each other, and produce superior results than the conventional scene flow estimation or stereo deblurring methods. We evaluate our method extensively on two available datasets and achieve significant improvement in flow estimation and removing the blur effect over the state-of-the-art methods.