 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Coding Agents Can Reproduce Social Science Findings
Jun 09, 2026Recent anecdotal evidence suggests that AI coding agents can reproduce published findings when provided with original data and code; yet systematic evaluation across social sciences remains limited. Existing evaluation benchmarks are insufficient, either small or conflate agent performance with problems in the reproduction materials themselves, such as code that fails to execute correctly. Here we introduce SocSci-Repro-Bench, a benchmark of 221 tasks spanning four disciplines and 13 substantive domains, constructed from studies whose results are either fully reproducible with available materials or demonstrably non-reproducible due to missing data, allowing us to isolate agents' reproduction capacity. Evaluating two frontier coding agents, Claude Code and Codex, we find that both can reproduce a large share of social science findings, with Claude Code substantially outperforming Codex. These reproduction rates considerably exceed those previously reported for general-purpose LLM-based agents on comparable reproducibility benchmarks. Both agents also perform strongly on a reasoning task requiring identification of underlying research questions, and additional analyses suggest that results are not primarily driven by memorization. Providing the original paper PDF alongside replication materials modestly improves performance but introduces bias on tasks where reproduction is impossible. We also show that agents can be nudged toward confirmatory specification search through subtle prompt framing. Together, these findings suggest that at least some frontier coding agents can serve as reliable executors of computational workflows while underscoring the need for careful benchmarking and prompt design as AI systems assume larger roles in scientific production.
AI Coding Agents in Social Science: Methodologically Diverse, Empirically Consistent, Interpretively Vulnerable
Jun 09, 2026The deployment of LLM-based agents in scientific analysis raises opposing concerns: that agents may reduce methodological diversity, or that they may amplify the analytic flexibility through which researchers reach motivated conclusions. We argue these worries target two empirically separable layers: a design layer of methodological choices, and a verdict layer in which a decision rule maps estimates to a substantive claim. We test both by running 20 independent executions of Claude Code and Codex on a prominent immigration and social-policy against a many-analysts human baseline. At the design layer, Codex matches human methodological diversity and Claude Code produces nearly three times as many specifications; both agents' effect estimates remain broadly aligned with the human consensus, and no agent model exactly matches any human model. A prompt-induced anti-immigration researcher prior reorganizes each agent's methodological decisions but, unlike for biased human analysts in the same data, does not shift aggregate estimates or final verdicts; nor do agents reroute along the methodological axes humans use to bias their estimates. At the verdict layer, an explicit confirmatory prompt flips Claude Code's verdicts from 10% to 90% support while leaving its coefficient distribution essentially unchanged, operating through rule omission rather than rule softening. AI agents can rival or exceed human methodological diversity at the design layer while remaining vulnerable at the verdict layer. In our setting, the locus of AI bias is not estimation but interpretation.
Unsupervised Elicitation of Moral Values from Language Models
Jan 25, 2026As AI systems become pervasive, grounding their behavior in human values is critical. Prior work suggests that language models (LMs) exhibit limited inherent moral reasoning, leading to calls for explicit moral teaching. However, constructing ground truth data for moral evaluation is difficult given plural frameworks and pervasive biases. We investigate unsupervised elicitation as an alternative, asking whether pretrained (base) LMs possess intrinsic moral reasoning capability that can be surfaced without human supervision. Using the Internal Coherence Maximization (ICM) algorithm across three benchmark datasets and four LMs, we test whether ICM can reliably label moral judgments, generalize across moral frameworks, and mitigate social bias. Results show that ICM outperforms all pre-trained and chatbot baselines on the Norm Bank and ETHICS benchmarks, while fine-tuning on ICM labels performs on par with or surpasses those of human labels. Across theoretically motivated moral frameworks, ICM yields its largest relative gains on Justice and Commonsense morality. Furthermore, although chatbot LMs exhibit social bias failure rates comparable to their pretrained ones, ICM reduces such errors by more than half, with the largest improvements in race, socioeconomic status, and politics. These findings suggest that pretrained LMs possess latent moral reasoning capacities that can be elicited through unsupervised methods like ICM, providing a scalable path for AI alignment.
Web-Browsing LLMs Can Access Social Media Profiles and Infer User Demographics
Jul 16, 2025Large language models (LLMs) have traditionally relied on static training data, limiting their knowledge to fixed snapshots. Recent advancements, however, have equipped LLMs with web browsing capabilities, enabling real time information retrieval and multi step reasoning over live web content. While prior studies have demonstrated LLMs ability to access and analyze websites, their capacity to directly retrieve and analyze social media data remains unexplored. Here, we evaluate whether web browsing LLMs can infer demographic attributes of social media users given only their usernames. Using a synthetic dataset of 48 X (Twitter) accounts and a survey dataset of 1,384 international participants, we show that these models can access social media content and predict user demographics with reasonable accuracy. Analysis of the synthetic dataset further reveals how LLMs parse and interpret social media profiles, which may introduce gender and political biases against accounts with minimal activity. While this capability holds promise for computational social science in the post API era, it also raises risks of misuse particularly in information operations and targeted advertising underscoring the need for safeguards. We recommend that LLM providers restrict this capability in public facing applications, while preserving controlled access for verified research purposes.
Open-Source Large Language Models Outperform Crowd Workers and Approach ChatGPT in Text-Annotation Tasks
Jul 05, 2023This study examines the performance of open-source Large Language Models (LLMs) in text annotation tasks and compares it with proprietary models like ChatGPT and human-based services such as MTurk. While prior research demonstrated the high performance of ChatGPT across numerous NLP tasks, open-source LLMs like HugginChat and FLAN are gaining attention for their cost-effectiveness, transparency, reproducibility, and superior data protection. We assess these models using both zero-shot and few-shot approaches and different temperature parameters across a range of text annotation tasks. Our findings show that while ChatGPT achieves the best performance in most tasks, open-source LLMs not only outperform MTurk but also demonstrate competitive potential against ChatGPT in specific tasks.
ChatGPT Outperforms Crowd-Workers for Text-Annotation Tasks
Mar 27, 2023
Many NLP applications require manual data annotations for a variety of tasks, notably to train classifiers or evaluate the performance of unsupervised models. Depending on the size and degree of complexity, the tasks may be conducted by crowd-workers on platforms such as MTurk as well as trained annotators, such as research assistants. Using a sample of 2,382 tweets, we demonstrate that ChatGPT outperforms crowd-workers for several annotation tasks, including relevance, stance, topics, and frames detection. Specifically, the zero-shot accuracy of ChatGPT exceeds that of crowd-workers for four out of five tasks, while ChatGPT's intercoder agreement exceeds that of both crowd-workers and trained annotators for all tasks. Moreover, the per-annotation cost of ChatGPT is less than $0.003 -- about twenty times cheaper than MTurk. These results show the potential of large language models to drastically increase the efficiency of text classification.
Psychological and Personality Profiles of Political Extremists
Apr 01, 2017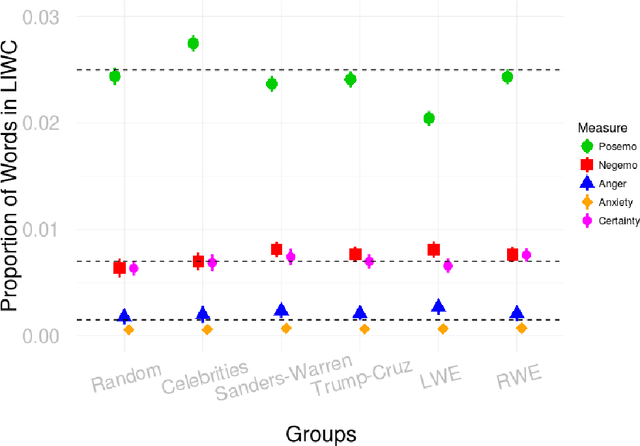
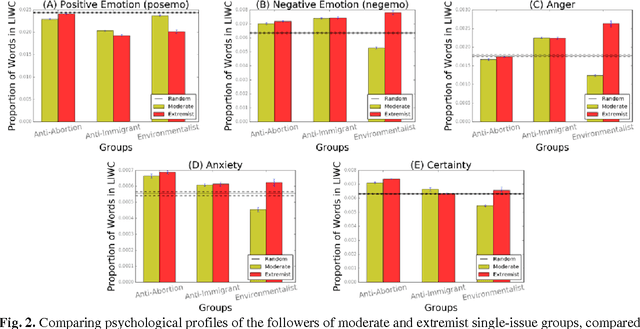
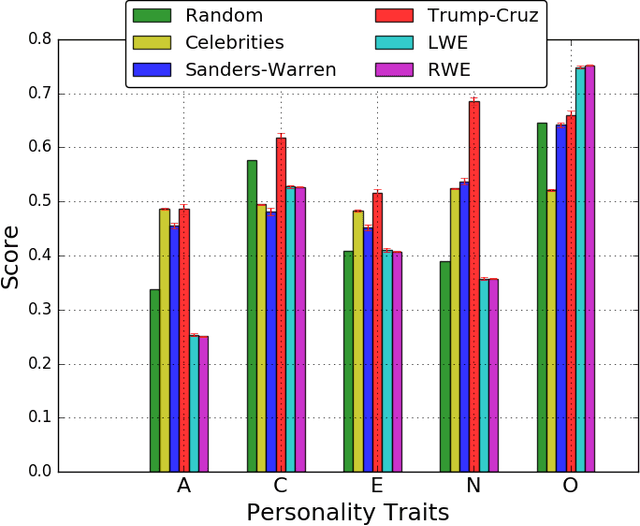
Global recruitment into radical Islamic movements has spurred renewed interest in the appeal of political extremism. Is the appeal a rational response to material conditions or is it the expression of psychological and personality disorders associated with aggressive behavior, intolerance, conspiratorial imagination, and paranoia? Empirical answers using surveys have been limited by lack of access to extremist groups, while field studies have lacked psychological measures and failed to compare extremists with contrast groups. We revisit the debate over the appeal of extremism in the U.S. context by comparing publicly available Twitter messages written by over 355,000 political extremist followers with messages written by non-extremist U.S. users. Analysis of text-based psychological indicators supports the moral foundation theory which identifies emotion as a critical factor in determining political orientation of individuals. Extremist followers also differ from others in four of the Big Five personality traits.