 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2D-Curri-DPO: Two-Dimensional Curriculum Learning for Direct Preference Optimization
Apr 10, 2025



Aligning large language models with human preferences is crucial for their safe deployment. While Direct Preference Optimization (DPO) offers an efficient alternative to reinforcement learning from human feedback, traditional DPO methods are limited by their reliance on single preference pairs. Recent work like Curriculum-DPO integrates multiple pairs using a one-dimensional difficulty curriculum based on pairwise distinguishability (PD), but overlooks the complexity of the input prompt itself. To address this, we propose 2D-Curri-DPO, a novel framework employing a two-dimensional curriculum that jointly models Prompt Complexity (PC) and Pairwise Distinguishability. This framework introduces dual difficulty metrics to quantify prompt semantic complexity and response preference clarity, defines a curriculum strategy space encompassing multiple selectable strategies for task adaptation, and incorporates a KL-divergence-based adaptive mechanism for dynamic reference model updates to enhance training stability. Comprehensive experiments demonstrate that 2D-Curri-DPO significantly outperforms standard DPO and prior curriculum methods across multiple benchmarks, including MT-Bench, Vicuna Bench, and WizardLM. Our approach achieves state-of-the-art performance on challenging test sets like UltraFeedback. Ablation studies confirm the benefits of the 2D structure and adaptive mechanisms, while analysis provides guidance for strategy selection. These findings demonstrate that effective alignment requires modeling both prompt complexity and pairwise distinguishability, establishing adaptive, multi-dimensional curriculum learning as a powerful and interpretable new paradigm for preference-based language model optimization.
Dynamically evolving segment anything model with continuous learning for medical image segmentation
Mar 08, 2025



Medical image segmentation is essential for clinical diagnosis, surgical planning, and treatment monitoring. Traditional approaches typically strive to tackle all medical image segmentation scenarios via one-time learning. However, in practical applications, the diversity of scenarios and tasks in medical image segmentation continues to expand, necessitating models that can dynamically evolve to meet the demands of various segmentation tasks. Here, we introduce EvoSAM, a dynamically evolving medical image segmentation model that continuously accumulates new knowledge from an ever-expanding array of scenarios and tasks, enhancing its segmentation capabilities. Extensive evaluations on surgical image blood vessel segmentation and multi-site prostate MRI segmentation demonstrate that EvoSAM not only improves segmentation accuracy but also mitigates catastrophic forgetting. Further experiments conducted by surgical clinicians on blood vessel segmentation confirm that EvoSAM enhances segmentation efficiency based on user prompts, highlighting its potential as a promising tool for clinical applications.
TMLC-Net: Transferable Meta Label Correction for Noisy Label Learning
Feb 11, 2025The prevalence of noisy labels in real-world datasets poses a significant impediment to the effective deployment of deep learning models. While meta-learning strategies have emerged as a promising approach for addressing this challenge, existing methods often suffer from limited transferability and task-specific designs. This paper introduces TMLC-Net, a novel Transferable Meta-Learner for Correcting Noisy Labels, designed to overcome these limitations. TMLC-Net learns a general-purpose label correction strategy that can be readily applied across diverse datasets and model architectures without requiring extensive retraining or fine-tuning. Our approach integrates three core components: (1) Normalized Noise Perception, which captures and normalizes training dynamics to handle distribution shifts; (2) Time-Series Encoding, which models the temporal evolution of sample statistics using a recurrent neural network; and (3) Subclass Decoding, which predicts a corrected label distribution based on the learned representations. We conduct extensive experiments on benchmark datasets with various noise types and levels, demonstrating that TMLC-Net consistently outperforms state-of-the-art methods in terms of both accuracy and robustness to label noise. Furthermore, we analyze the transferability of TMLC-Net, showcasing its adaptability to new datasets and noise conditions, and establishing its potential as a broadly applicable solution for robust deep learning in noisy environments.
Is Data Valuation Learnable and Interpretable?
Jun 03, 2024Measuring the value of individual samples is critical for many data-driven tasks, e.g., the training of a deep learning model. Recent literature witnesses the substantial efforts in developing data valuation methods. The primary data valuation methodology is based on the Shapley value from game theory, and various methods are proposed along this path. {Even though Shapley value-based valuation has solid theoretical basis, it is entirely an experiment-based approach and no valuation model has been constructed so far.} In addition, current data valuation methods ignore the interpretability of the output values, despite an interptable data valuation method is of great helpful for applications such as data pricing. This study aims to answer an important question: is data valuation learnable and interpretable? A learned valuation model have several desirable merits such as fixed number of parameters and knowledge reusability. An intrepretable data valuation model can explain why a sample is valuable or invaluable. To this end, two new data value modeling frameworks are proposed, in which a multi-layer perception~(MLP) and a new regression tree are utilized as specific base models for model training and interpretability, respectively. Extensive experiments are conducted on benchmark datasets. {The experimental results provide a positive answer for the question.} Our study opens up a new technical path for the assessing of data values. Large data valuation models can be built across many different data-driven tasks, which can promote the widespread application of data valuation.
Class-Level Logit Perturbation
Sep 26, 2022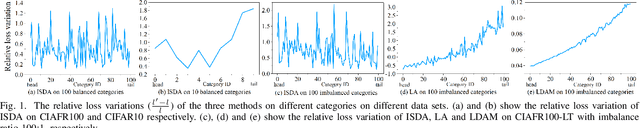

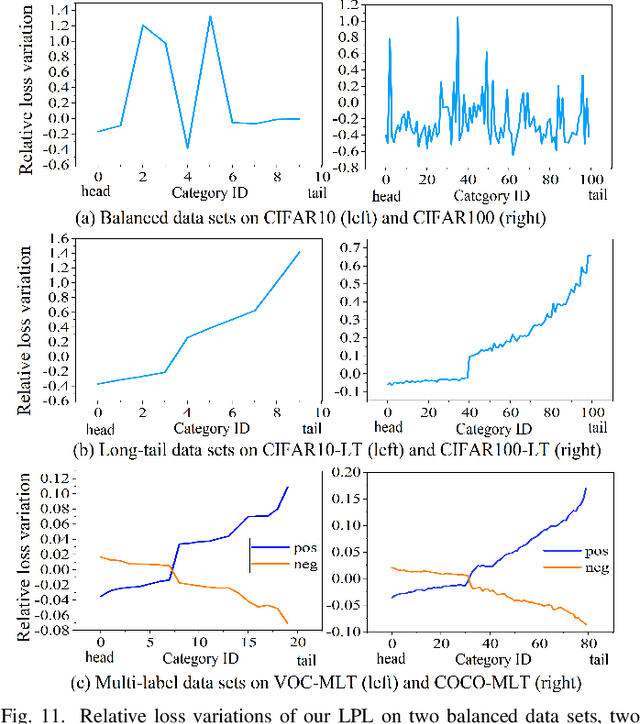
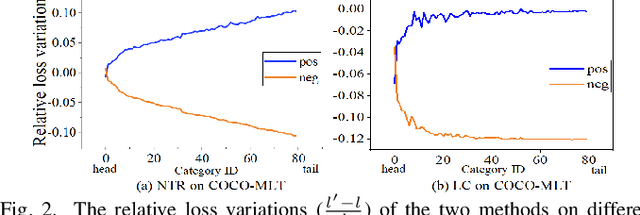
Features, logits, and labels are the three primary data when a sample passes through a deep neural network. Feature perturbation and label perturbation receive increasing attention in recent years. They have been proven to be useful in various deep learning approaches. For example, (adversarial) feature perturbation can improve the robustness or even generalization capability of learned models. However, limited studies have explicitly explored for the perturbation of logit vectors. This work discusses several existing methods related to class-level logit perturbation. A unified viewpoint between positive/negative data augmentation and loss variations incurred by logit perturbation is established. A theoretical analysis is provided to illuminate why class-level logit perturbation is useful. Accordingly, new methodologies are proposed to explicitly learn to perturb logits for both single-label and multi-label classification tasks. Extensive experiments on benchmark image classification data sets and their long-tail versions indicated the competitive performance of our learning method. As it only perturbs on logit, it can be used as a plug-in to fuse with any existing classification algorithms. All the codes are available at https://github.com/limengyang1992/lpl.
Compensation Learning
Jul 26, 2021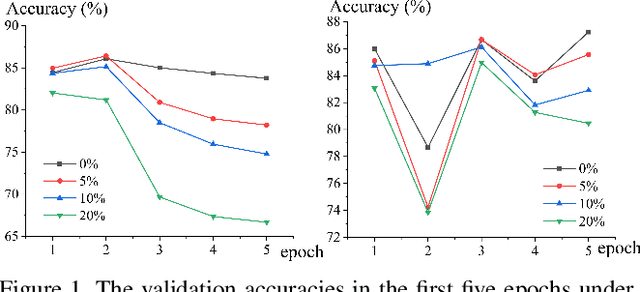
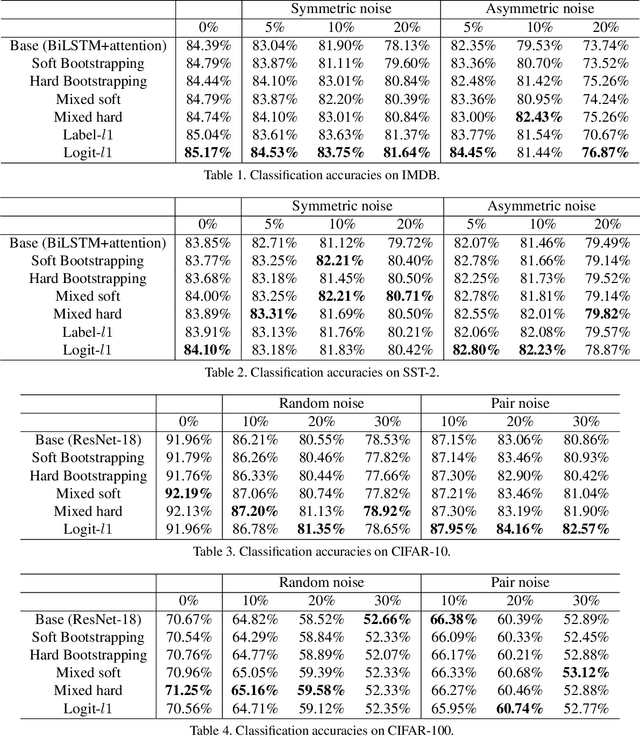
Weighting strategy prevails in machine learning. For example, a common approach in robust machine learning is to exert lower weights on samples which are likely to be noisy or hard. This study reveals another undiscovered strategy, namely, compensating, that has also been widely used in machine learning. Learning with compensating is called compensation learning and a systematic taxonomy is constructed for it in this study. In our taxonomy, compensation learning is divided on the basis of the compensation targets, inference manners, and granularity levels. Many existing learning algorithms including some classical ones can be seen as a special case of compensation learning or partially leveraging compensating. Furthermore, a family of new learning algorithms can be obtained by plugging the compensation learning into existing learning algorithms. Specifically, three concrete new learning algorithms are proposed for robust machine learning. Extensive experiments on text sentiment analysis, image classification, and graph classification verify the effectiveness of the three new algorithms. Compensation learning can also be used in various learning scenarios, such as imbalance learning, clustering, regression, and so on.
$ρ$-hot Lexicon Embedding-based Two-level LSTM for Sentiment Analysis
Mar 21, 2018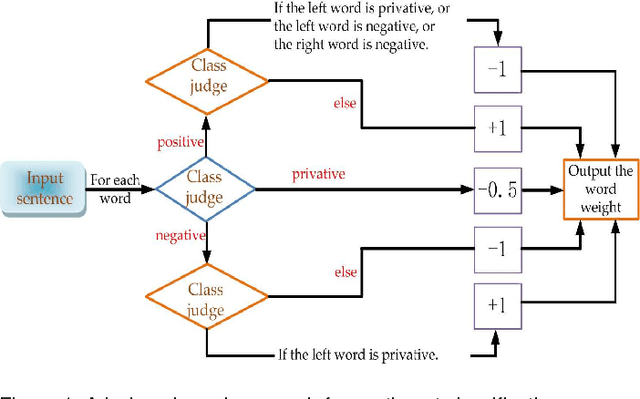
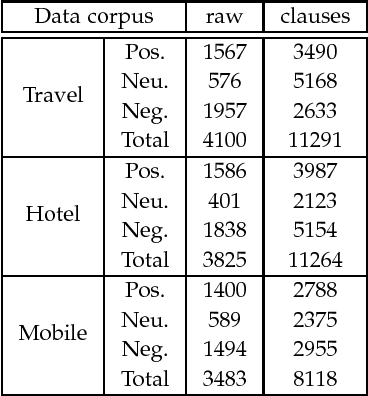
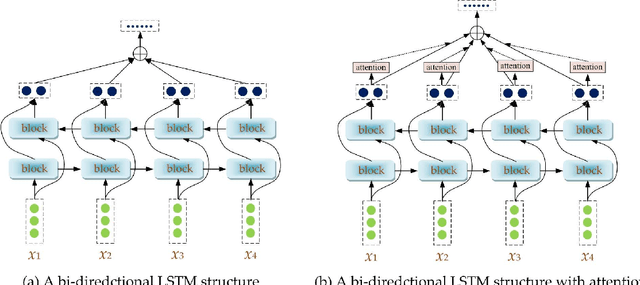
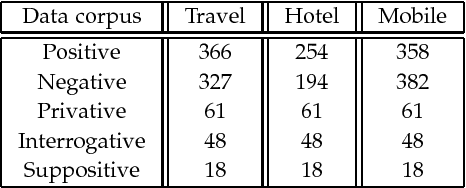
Sentiment analysis is a key component in various text mining applications. Numerous sentiment classification techniques, including conventional and deep learning-based methods, have been proposed in the literature. In most existing methods, a high-quality training set is assumed to be given. Nevertheless, constructing a high-quality training set that consists of highly accurate labels is challenging in real applications. This difficulty stems from the fact that text samples usually contain complex sentiment representations, and their annotation is subjective. We address this challenge in this study by leveraging a new labeling strategy and utilizing a two-level long short-term memory network to construct a sentiment classifier. Lexical cues are useful for sentiment analysis, and they have been utilized in conventional studies. For example, polar and privative words play important roles in sentiment analysis. A new encoding strategy, that is, $\rho$-hot encoding, is proposed to alleviate the drawbacks of one-hot encoding and thus effectively incorporate useful lexical cues. We compile three Chinese data sets on the basis of our label strategy and proposed methodology. Experiments on the three data sets demonstrate that the proposed method outperforms state-of-the-art algorithms.