 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart Buildings Energy Consumption Forecasting using Adaptive Evolutionary Ensemble Learning Models
Jun 13, 2025



Smart buildings are gaining popularity because they can enhance energy efficiency, lower costs, improve security, and provide a more comfortable and convenient environment for building occupants. A considerable portion of the global energy supply is consumed in the building sector and plays a pivotal role in future decarbonization pathways. To manage energy consumption and improve energy efficiency in smart buildings, developing reliable and accurate energy demand forecasting is crucial and meaningful. However, extending an effective predictive model for the total energy use of appliances at the building level is challenging because of temporal oscillations and complex linear and non-linear patterns. This paper proposes three hybrid ensemble predictive models, incorporating Bagging, Stacking, and Voting mechanisms combined with a fast and effective evolutionary hyper-parameters tuner. The performance of the proposed energy forecasting model was evaluated using a hybrid dataset comprising meteorological parameters, appliance energy use, temperature, humidity, and lighting energy consumption from various sections of a building, collected by 18 sensors located in Stambroek, Mons, Belgium. To provide a comparative framework and investigate the efficiency of the proposed predictive model, 15 popular machine learning (ML) models, including two classic ML models, three NNs, a Decision Tree (DT), a Random Forest (RF), two Deep Learning (DL) and six Ensemble models, were compared. The prediction results indicate that the adaptive evolutionary bagging model surpassed other predictive models in both accuracy and learning error. Notably, it achieved accuracy gains of 12.6%, 13.7%, 12.9%, 27.04%, and 17.4% compared to Extreme Gradient Boosting (XGB), Categorical Boosting (CatBoost), GBM, LGBM, and Random Forest (RF).
LT4SG@SMM4H24: Tweets Classification for Digital Epidemiology of Childhood Health Outcomes Using Pre-Trained Language Models
Jun 11, 2024This paper presents our approaches for the SMM4H24 Shared Task 5 on the binary classification of English tweets reporting children's medical disorders. Our first approach involves fine-tuning a single RoBERTa-large model, while the second approach entails ensembling the results of three fine-tuned BERTweet-large models. We demonstrate that although both approaches exhibit identical performance on validation data, the BERTweet-large ensemble excels on test data. Our best-performing system achieves an F1-score of 0.938 on test data, outperforming the benchmark classifier by 1.18%.
Hybrid Inception Architecture with Residual Connection: Fine-tuned Inception-ResNet Deep Learning Model for Lung Inflammation Diagnosis from Chest Radiographs
Oct 05, 2023



Diagnosing lung inflammation, particularly pneumonia, is of paramount importance for effectively treating and managing the disease. Pneumonia is a common respiratory infection caused by bacteria, viruses, or fungi and can indiscriminately affect people of all ages. As highlighted by the World Health Organization (WHO), this prevalent disease tragically accounts for a substantial 15% of global mortality in children under five years of age. This article presents a comparative study of the Inception-ResNet deep learning model's performance in diagnosing pneumonia from chest radiographs. The study leverages Mendeleys chest X-ray images dataset, which contains 5856 2D images, including both Viral and Bacterial Pneumonia X-ray images. The Inception-ResNet model is compared with seven other state-of-the-art convolutional neural networks (CNNs), and the experimental results demonstrate the Inception-ResNet model's superiority in extracting essential features and saving computation runtime. Furthermore, we examine the impact of transfer learning with fine-tuning in improving the performance of deep convolutional models. This study provides valuable insights into using deep learning models for pneumonia diagnosis and highlights the potential of the Inception-ResNet model in this field. In classification accuracy, Inception-ResNet-V2 showed superior performance compared to other models, including ResNet152V2, MobileNet-V3 (Large and Small), EfficientNetV2 (Large and Small), InceptionV3, and NASNet-Mobile, with substantial margins. It outperformed them by 2.6%, 6.5%, 7.1%, 13%, 16.1%, 3.9%, and 1.6%, respectively, demonstrating its significant advantage in accurate classification.
EmoMent: An Emotion Annotated Mental Health Corpus from two South Asian Countries
Aug 17, 2022

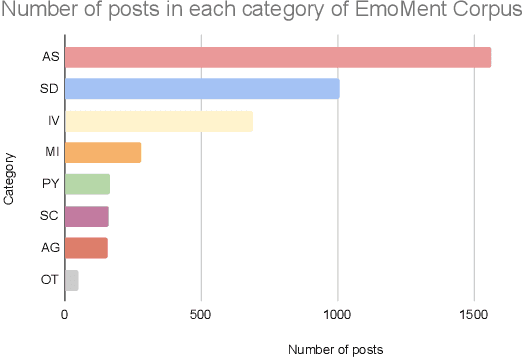

People often utilise online media (e.g., Facebook, Reddit) as a platform to express their psychological distress and seek support. State-of-the-art NLP techniques demonstrate strong potential to automatically detect mental health issues from text. Research suggests that mental health issues are reflected in emotions (e.g., sadness) indicated in a person's choice of language. Therefore, we developed a novel emotion-annotated mental health corpus (EmoMent), consisting of 2802 Facebook posts (14845 sentences) extracted from two South Asian countries - Sri Lanka and India. Three clinical psychology postgraduates were involved in annotating these posts into eight categories, including 'mental illness' (e.g., depression) and emotions (e.g., 'sadness', 'anger'). EmoMent corpus achieved 'very good' inter-annotator agreement of 98.3% (i.e. % with two or more agreement) and Fleiss' Kappa of 0.82. Our RoBERTa based models achieved an F1 score of 0.76 and a macro-averaged F1 score of 0.77 for the first task (i.e. predicting a mental health condition from a post) and the second task (i.e. extent of association of relevant posts with the categories defined in our taxonomy), respectively.