 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaNet: A Scalable and Flexible Framework for Automatically Learning Ensembles
Apr 30, 2019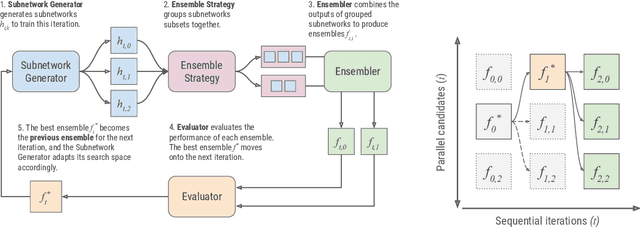
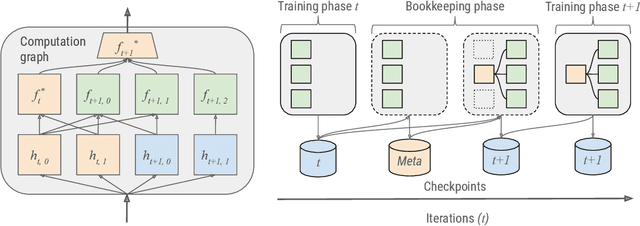
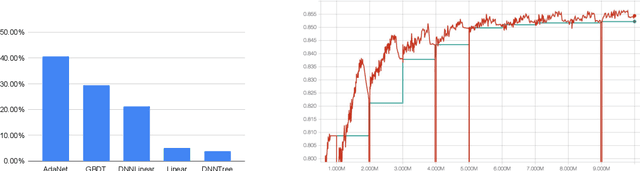
AdaNet is a lightweight TensorFlow-based (Abadi et al., 2015) framework for automatically learning high-quality ensembles with minimal expert intervention. Our framework is inspired by the AdaNet algorithm (Cortes et al., 2017) which learns the structure of a neural network as an ensemble of subnetworks. We designed it to: (1) integrate with the existing TensorFlow ecosystem, (2) offer sensible default search spaces to perform well on novel datasets, (3) present a flexible API to utilize expert information when available, and (4) efficiently accelerate training with distributed CPU, GPU, and TPU hardware. The code is open-source and available at: https://github.com/tensorflow/adanet.
Hypothesis Set Stability and Generalization
Apr 17, 2019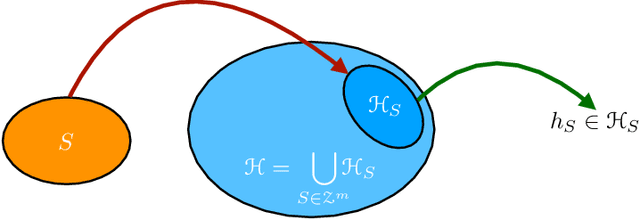
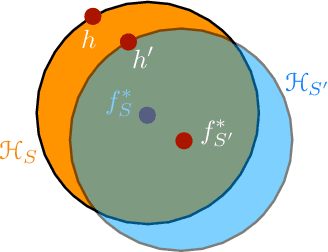
We present an extensive study of generalization for data-dependent hypothesis sets. We give a general learning guarantee for data-dependent hypothesis sets based on a notion of transductive Rademacher complexity. Our main results are two generalization bounds for data-dependent hypothesis sets expressed in terms of a notion of hypothesis set stability and a notion of Rademacher complexity for data-dependent hypothesis sets that we introduce. These bounds admit as special cases both standard Rademacher complexity bounds and algorithm-dependent uniform stability bounds. We also illustrate the use of these learning bounds in the analysis of several scenarios.
Agnostic Federated Learning
Feb 01, 2019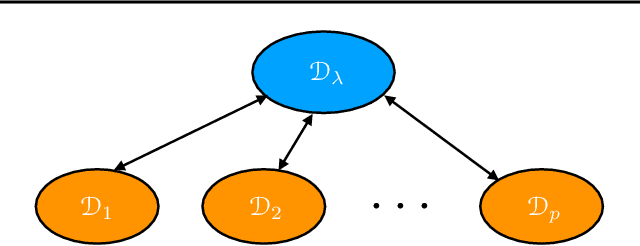

A key learning scenario in large-scale applications is that of federated learning, where a centralized model is trained based on data originating from a large number of clients. We argue that, with the existing training and inference, federated models can be biased towards different clients. Instead, we propose a new framework of agnostic federated learning, where the centralized model is optimized for any target distribution formed by a mixture of the client distributions. We further show that this framework naturally yields a notion of fairness. We present data-dependent Rademacher complexity guarantees for learning with this objective, which guide the definition of an algorithm for agnostic federated learning. We also give a fast stochastic optimization algorithm for solving the corresponding optimization problem, for which we prove convergence bounds, assuming a convex loss function and hypothesis set. We further empirically demonstrate the benefits of our approach in several datasets. Beyond federated learning, our framework and algorithm can be of interest to other learning scenarios such as cloud computing, domain adaptation, drifting, and other contexts where the training and test distributions do not coincide.
Policy Regret in Repeated Games
Nov 09, 2018

The notion of \emph{policy regret} in online learning is a well defined? performance measure for the common scenario of adaptive adversaries, which more traditional quantities such as external regret do not take into account. We revisit the notion of policy regret and first show that there are online learning settings in which policy regret and external regret are incompatible: any sequence of play that achieves a favorable regret with respect to one definition must do poorly with respect to the other. We then focus on the game-theoretic setting where the adversary is a self-interested agent. In that setting, we show that external regret and policy regret are not in conflict and, in fact, that a wide class of algorithms can ensure a favorable regret with respect to both definitions, so long as the adversary is also using such an algorithm. We also show that the sequence of play of no-policy regret algorithms converges to a \emph{policy equilibrium}, a new notion of equilibrium that we introduce. Relating this back to external regret, we show that coarse correlated equilibria, which no-external regret players converge to, are a strict subset of policy equilibria. Thus, in game-theoretic settings, every sequence of play with no external regret also admits no policy regret, but the converse does not hold.
Online Non-Additive Path Learning under Full and Partial Information
Sep 18, 2018
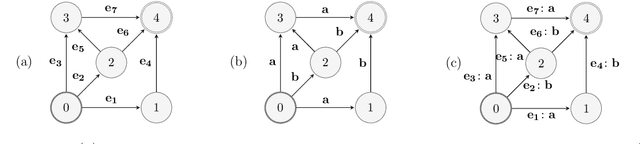
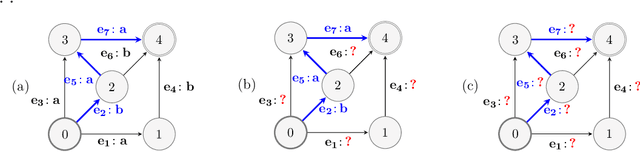

We study the problem of online path learning with non-additive gains, which is a central problem appearing in several applications, including ensemble structured prediction. We present new online algorithms for path learning with non-additive count-based gains for the three settings of full information, semi-bandit and full bandit. These algorithms admit very favorable regret guarantees and their guarantees can be viewed as the non-additive counterparts to the best known guarantees in the additive case. A key component of our algorithms is the definition and computation of an intermediate context-dependent automaton that enables us to use existing algorithms designed for additive gains. We further apply our methods to the important application of ensemble structured prediction. Finally, beyond count-based gains, we give an efficient implementation of the EXP3 algorithm for the full bandit setting with an arbitrary (non-additive) gain.
Algorithms and Theory for Multiple-Source Adaptation
May 20, 2018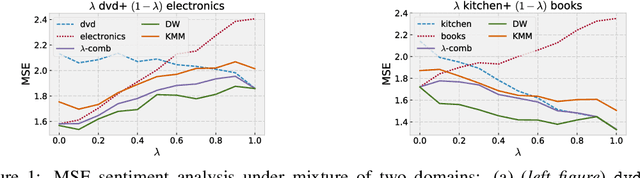
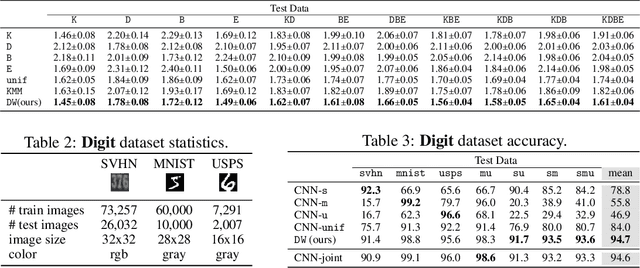
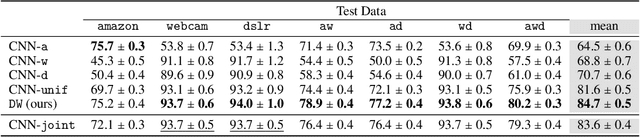
This work includes a number of novel contributions for the multiple-source adaptation problem. We present new normalized solutions with strong theoretical guarantees for the cross-entropy loss and other similar losses. We also provide new guarantees that hold in the case where the conditional probabilities for the source domains are distinct. Moreover, we give new algorithms for determining the distribution-weighted combination solution for the cross-entropy loss and other losses. We report the results of a series of experiments with real-world datasets. We find that our algorithm outperforms competing approaches by producing a single robust model that performs well on any target mixture distribution. Altogether, our theory, algorithms, and empirical results provide a full solution for the multiple-source adaptation problem with very practical benefits.
Logistic Regression: The Importance of Being Improper
Mar 25, 2018Learning linear predictors with the logistic loss---both in stochastic and online settings---is a fundamental task in learning and statistics, with direct connections to classification and boosting. Existing "fast rates" for this setting exhibit exponential dependence on the predictor norm, and Hazan et al. (2014) showed that this is unfortunately unimprovable. Starting with the simple observation that the logistic loss is 1-mixable, we design a new efficient improper learning algorithm for online logistic regression that circumvents the aforementioned lower bound with a regret bound exhibiting a doubly-exponential improvement in dependence on the predictor norm. This provides a positive resolution to a variant of the COLT 2012 open problem of McMahan and Streeter (2012) when improper learning is allowed. This improvement is obtained both in the online setting and, with some extra work, in the batch statistical setting with high probability. We also show that the improved dependency on predictor norm is also near-optimal. Leveraging this improved dependency on the predictor norm yields the following applications: (a) we give algorithms for online bandit multiclass learning with the logistic loss with an $\tilde{O}(\sqrt{n})$ relative mistake bound across essentially all parameter ranges, thus providing a solution to the COLT 2009 open problem of Abernethy and Rakhlin (2009), and (b) we give an adaptive algorithm for online multiclass boosting with optimal sample complexity, thus partially resolving an open problem of Beygelzimer et al. (2015) and Jung et al. (2017). Finally, we give information-theoretic bounds on the optimal rates for improper logistic regression with general function classes, thereby characterizing the extent to which our improvement for linear classes extends to other parameteric and even nonparametric settings.
Theory and Algorithms for Forecasting Time Series
Mar 15, 2018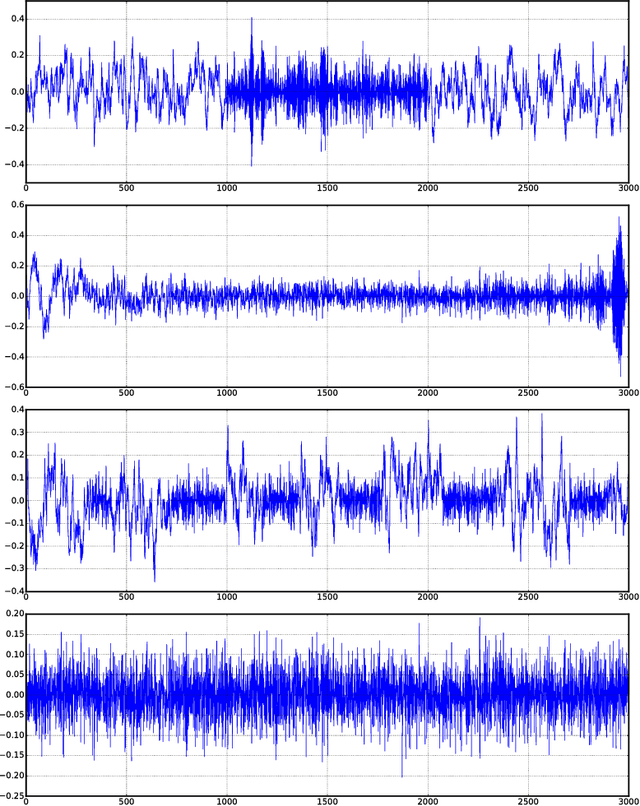
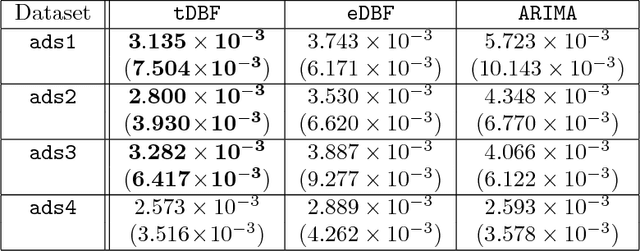
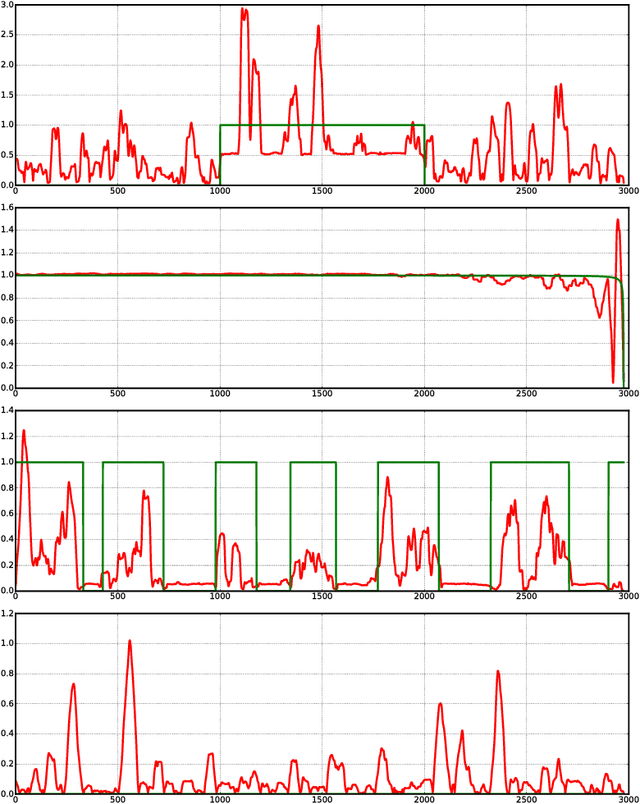

We present data-dependent learning bounds for the general scenario of non-stationary non-mixing stochastic processes. Our learning guarantees are expressed in terms of a data-dependent measure of sequential complexity and a discrepancy measure that can be estimated from data under some mild assumptions. We also also provide novel analysis of stable time series forecasting algorithm using this new notion of discrepancy that we introduce. We use our learning bounds to devise new algorithms for non-stationary time series forecasting for which we report some preliminary experimental results.
Online Learning with Abstention
Feb 27, 2018



We present an extensive study of the key problem of online learning where algorithms are allowed to abstain from making predictions. In the adversarial setting, we show how existing online algorithms and guarantees can be adapted to this problem. In the stochastic setting, we first point out a bias problem that limits the straightforward extension of algorithms such as UCB-N to time-varying feedback graphs, as needed in this context. Next, we give a new algorithm, UCB-GT, that exploits historical data and is adapted to time-varying feedback graphs. We show that this algorithm benefits from more favorable regret guarantees than a possible, but limited, extension of UCB-N. We further report the results of a series of experiments demonstrating that UCB-GT largely outperforms that extension of UCB-N, as well as more standard baselines.
Discrepancy-Based Algorithms for Non-Stationary Rested Bandits
Feb 27, 2018


We study the multi-armed bandit problem where the rewards are realizations of general non-stationary stochastic processes, a setting that generalizes many existing lines of work and analyses. In particular, we present a theoretical analysis and derive regret guarantees for rested bandits in which the reward distribution of each arm changes only when we pull that arm. Remarkably, our regret bounds are logarithmic in the number of rounds under several natural conditions. We introduce a new algorithm based on classical UCB ideas combined with the notion of weighted discrepancy, a useful tool for measuring the non-stationarity of a stochastic process. We show that the notion of discrepancy can be used to design very general algorithms and a unified framework for the analysis of multi-armed rested bandit problems with non-stationary rewards. In particular, we show that we can recover the regret guarantees of many specific instances of bandit problems with non-stationary rewards that have been studied in the literature. We also provide experiments demonstrating that our algorithms can enjoy a significant improvement in practice compared to standard benchmarks.