 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeriSim: A Configurable Framework for Evaluating Medical AI Under Realistic Patient Noise
Apr 12, 2026Medical large language models (LLMs) achieve impressive performance on standardized benchmarks, yet these evaluations fail to capture the complexity of real clinical encounters where patients exhibit memory gaps, limited health literacy, anxiety, and other communication barriers. We introduce VeriSim, a truth-preserving patient simulation framework that injects controllable, clinically evidence-grounded noise into patient responses while maintaining strict adherence to medical ground truth through a hybrid UMLS-LLM verification mechanism. Our framework operationalizes six noise dimensions derived from peer-reviewed medical communication literature, capturing authentic clinical phenomena such as patient recall limitations, health literacy barriers, and stigma-driven non-disclosure. Experiments across seven open-weight LLMs reveal that all models degrade significantly under realistic patient noise, with diagnostic accuracy dropping 15-25% and conversation length increasing 34-55%. Notably, smaller models (7B) show 40% greater degradation than larger models (70B+), while medical fine-tuning on standard corpora provides limited robustness benefits against patient communication noise. Evaluation by board-certified clinicians demonstrates high-quality simulation with strong inter-annotator agreement (kappa > 0.80), while LLM-as-a-Judge serves as a validated auxiliary evaluator achieving comparable reliability for scalable assessment. Our results highlight a critical Sim-to-Real gap in current medical AI. We release VeriSim as an open-source noise-injection framework, establishing a rigorous testbed for evaluating clinical robustness.
Context-Aware Decoding for Faithful Vision-Language Generation
Jan 09, 2026Hallucinations, generating responses inconsistent with the visual input, remain a critical limitation of large vision-language models (LVLMs), especially in open-ended tasks such as image captioning and visual reasoning. In this work, we probe the layer-wise generation dynamics that drive hallucinations and propose a training-free mitigation strategy. Employing the Logit Lens, we examine how LVLMs construct next-token distributions across decoder layers, uncovering a pronounced commitment-depth gap: truthful tokens accumulate probability mass on their final candidates earlier than hallucinatory ones. Drawing on this discovery, we introduce Context Embedding Injection (CEI), a lightweight method that harnesses the hidden state of the last input token-the context embedding-as a grounding signal to maintain visual fidelity throughout decoding and curb hallucinations. Evaluated on the CHAIR, AMBER, and MMHal-Bench benchmarks (with a maximum token length of 512), CEI outperforms state-of-the-art baselines across three LVLMs, with its dynamic variant yielding the lowest overall hallucination rates. By integrating novel mechanistic insights with a scalable intervention, this work advances the mitigation of hallucinations in LVLMs.
Mitigating Hallucination in Large Vision-Language Models via Adaptive Attention Calibration
May 27, 2025



Large vision-language models (LVLMs) achieve impressive performance on multimodal tasks but often suffer from hallucination, and confidently describe objects or attributes not present in the image. Current inference-time interventions, while training-free, struggle to maintain accuracy in open-ended and long-form generation scenarios. We introduce the Confidence-Aware Attention Calibration (CAAC) framework to address this challenge by targeting two key biases: spatial perception bias, which distributes attention disproportionately across image tokens, and modality bias, which shifts focus from visual to textual inputs over time. CAAC employs a two-step approach: Visual-Token Calibration (VTC) to balance attention across visual tokens, and Adaptive Attention Re-Scaling (AAR) to reinforce visual grounding based on the model's confidence. This confidence-driven adjustment ensures consistent visual alignment during generation. Experiments on CHAIR, AMBER, and POPE benchmarks demonstrate that CAAC outperforms baselines, particularly in long-form generations, effectively reducing hallucination.
Leveraging Wastewater Monitoring for COVID-19 Forecasting in the US: a Deep Learning study
Dec 17, 2022The outburst of COVID-19 in late 2019 was the start of a health crisis that shook the world and took millions of lives in the ensuing years. Many governments and health officials failed to arrest the rapid circulation of infection in their communities. The long incubation period and the large proportion of asymptomatic cases made COVID-19 particularly elusive to track. However, wastewater monitoring soon became a promising data source in addition to conventional indicators such as confirmed daily cases, hospitalizations, and deaths. Despite the consensus on the effectiveness of wastewater viral load data, there is a lack of methodological approaches that leverage viral load to improve COVID-19 forecasting. This paper proposes using deep learning to automatically discover the relationship between daily confirmed cases and viral load data. We trained one Deep Temporal Convolutional Networks (DeepTCN) and one Temporal Fusion Transformer (TFT) model to build a global forecasting model. We supplement the daily confirmed cases with viral loads and other socio-economic factors as covariates to the models. Our results suggest that TFT outperforms DeepTCN and learns a better association between viral load and daily cases. We demonstrated that equipping the models with the viral load improves their forecasting performance significantly. Moreover, viral load is shown to be the second most predictive input, following the containment and health index. Our results reveal the feasibility of training a location-agnostic deep-learning model to capture the dynamics of infection diffusion when wastewater viral load data is provided.
HHAR-net: Hierarchical Human Activity Recognition using Neural Networks
Nov 10, 2020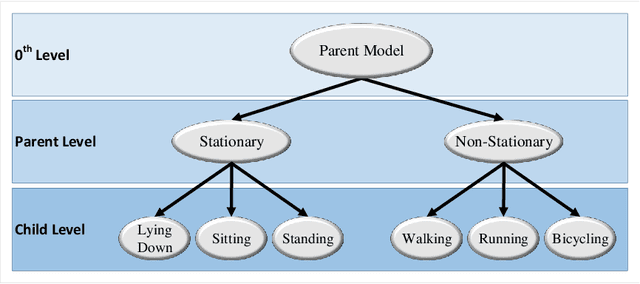

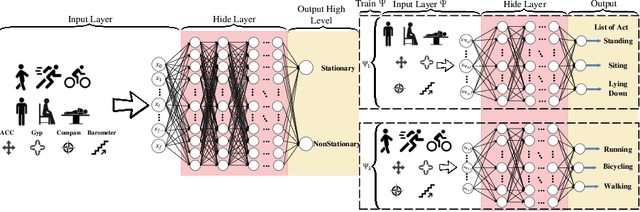
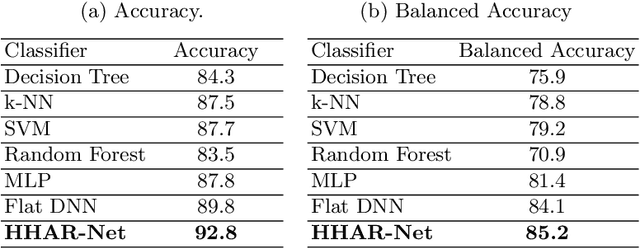
Activity recognition using built-in sensors in smart and wearable devices provides great opportunities to understand and detect human behavior in the wild and gives a more holistic view of individuals' health and well being. Numerous computational methods have been applied to sensor streams to recognize different daily activities. However, most methods are unable to capture different layers of activities concealed in human behavior. Also, the performance of the models starts to decrease with increasing the number of activities. This research aims at building a hierarchical classification with Neural Networks to recognize human activities based on different levels of abstraction. We evaluate our model on the Extrasensory dataset; a dataset collected in the wild and containing data from smartphones and smartwatches. We use a two-level hierarchy with a total of six mutually exclusive labels namely, "lying down", "sitting", "standing in place", "walking", "running", and "bicycling" divided into "stationary" and "non-stationary". The results show that our model can recognize low-level activities (stationary/non-stationary) with 95.8% accuracy and overall accuracy of 92.8% over six labels. This is 3% above our best performing baseline.