 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing Fast and Slow: Task-Adaptive Planning for Non-prehensile Manipulation Under Uncertainty
Jan 21, 2019
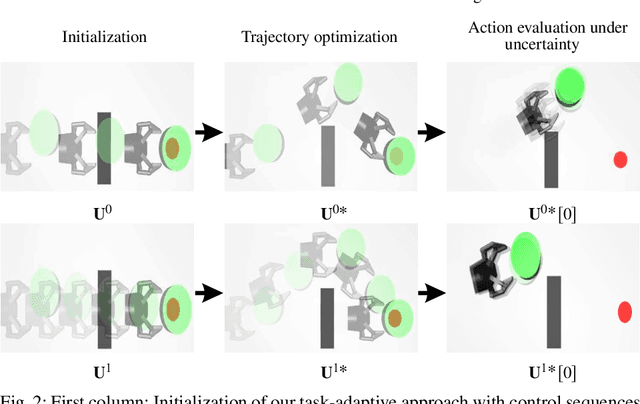
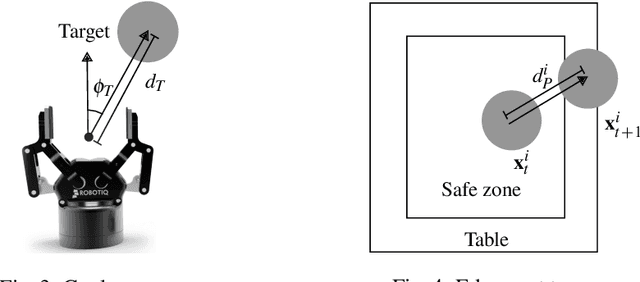
We propose a planning and control approach to physics-based manipulation. The key feature of the algorithm is that it can adapt to the accuracy requirements of a task, by slowing down and generating `careful' motion when the task requires high accuracy, and by speeding up and moving fast when the task tolerates inaccuracy. We formulate the problem as an MDP with action-dependent stochasticity and propose an approximate online solution to it. We use a trajectory optimizer with a deterministic model to suggest promising actions to the MDP, to reduce computation time spent on evaluating different actions. We conducted experiments in simulation and on a real robotic system. Our results show that with a task-adaptive planning and control approach, a robot can choose fast or slow actions depending on the task accuracy and uncertainty level. The robot makes these decisions online and is able to maintain high success rates while completing manipulation tasks as fast as possible.
Planning for Muscular and Peripersonal-Space Comfort during Human-Robot Forceful Collaboration
Oct 19, 2018
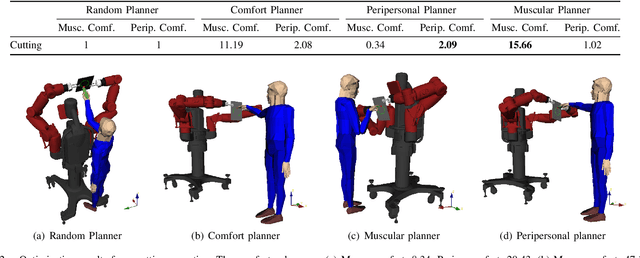


This paper presents a planning algorithm designed to improve cooperative robot behavior concerning human comfort during forceful human-robot physical interaction. Particularly, we are interested in planning for object grasping and positioning ensuring not only stability against the exerted human force but also empowering the robot with capabilities to address and improve human experience and comfort. Herein, comfort is addressed as both the muscular activation level required to exert the cooperative task, and the human spatial perception during the interaction, namely, the peripersonal space. By maximizing both comfort criteria, the robotic system can plan for the task (ensuring grasp stability) and for the human (improving human comfort). We believe this to be a key element to achieve intuitive and fluid human-robot interaction in real applications. Real HRI drilling and cutting experiments illustrated the efficiency of the proposed planner in improving overall comfort and HRI experience without compromising grasp stability.
Real-Time Online Re-Planning for Grasping Under Clutter and Uncertainty
Oct 09, 2018
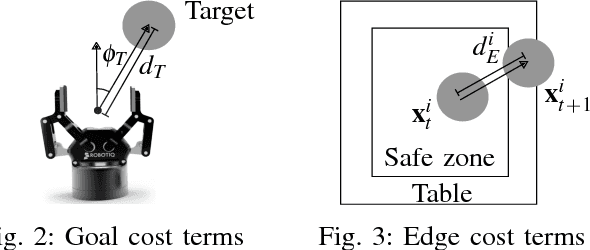


We consider the problem of grasping in clutter. While there have been motion planners developed to address this problem in recent years, these planners are mostly tailored for open-loop execution. Open-loop execution in this domain, however, is likely to fail, since it is not possible to model the dynamics of the multi-body multi-contact physical system with enough accuracy, neither is it reasonable to expect robots to know the exact physical properties of objects, such as frictional, inertial, and geometrical. Therefore, we propose an online re-planning approach for grasping through clutter. The main challenge is the long planning times this domain requires, which makes fast re-planning and fluent execution difficult to realize. In order to address this, we propose an easily parallelizable stochastic trajectory optimization based algorithm that generates a sequence of optimal controls. We show that by running this optimizer only for a small number of iterations, it is possible to perform real time re-planning cycles to achieve reactive manipulation under clutter and uncertainty.
Planning with a Receding Horizon for Manipulation in Clutter using a Learned Value Function
Jul 27, 2018
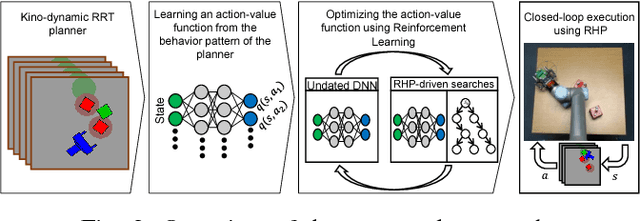
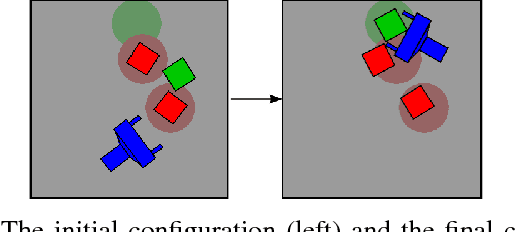
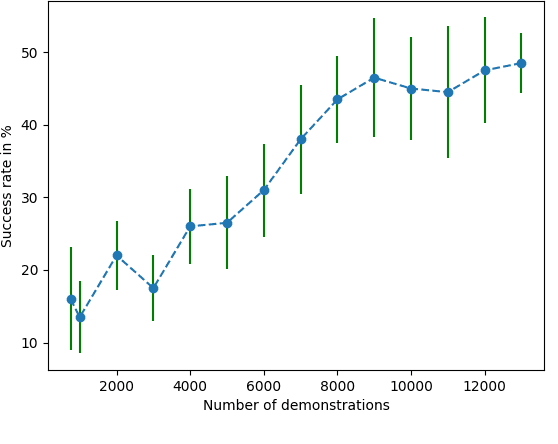
Manipulation in clutter requires solving complex sequential decision making problems in an environment rich with physical interactions. The transfer of motion planning solutions from simulation to the real world, in open-loop, suffers from the inherent uncertainty in modelling real world physics. We propose interleaving planning and execution in real-time, in a closed-loop setting, using a Receding Horizon Planner (RHP) for pushing manipulation in clutter. In this context, we address the problem of finding a suitable value function based heuristic for efficient planning, and for estimating the cost-to-go from the horizon to the goal. We estimate such a value function first by using plans generated by an existing sampling-based planner. Then, we further optimize the value function through reinforcement learning. We evaluate our approach and compare it to state-of-the-art planning techniques for manipulation in clutter. We conduct experiments in simulation with artificially injected uncertainty on the physics parameters, as well as in real world tasks of manipulation in clutter. We show that this approach enables the robot to react to the uncertain dynamics of the real world effectively.