 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildRelight: A Real-World Benchmark and Physics-Guided Adaptation for Single-Image Relighting
May 12, 2026Recent single-image relighting methods, powered by advanced generative models, have achieved impressive photorealism on synthetic benchmarks. However, their effectiveness in the complex visual landscape of the real world remains largely unverified. A critical gap exists, as current datasets are typically designed for multi-view reconstruction and fail to address the unique challenges of single-image relighting. To bridge this synthetic-to-real gap, we introduce WildRelight, the first in-the-wild dataset specifically created for evaluating single-image relighting models. WildRelight features a diverse collection of high-resolution outdoor scenes, captured under strictly aligned, temporally varying natural illuminations, each paired with a high-dynamic-range environment map. Using this data, we establish a rigorous benchmark revealing that state-of-the-art models trained on synthetic data suffer from severe domain shifts. The strictly aligned temporal structure of WildRelight enables a new paradigm for domain adaptation. We demonstrate this by introducing a physics-guided inference framework that leverages the captured natural light evolution as a self-supervised constraint. By integrating Diffusion Posterior Sampling (DPS) with temporal Sampling-Aware Test-Time Adaptation (TTA), we show that the dataset allows synthetic models to align with real-world statistics on-the-fly, transforming the intractable sim-to-real challenge into a tractable self-supervised task. The dataset and code will be made publicly available to foster robust, physically-grounded relighting research.
AutoQ-VIS: Improving Unsupervised Video Instance Segmentation via Automatic Quality Assessment
Aug 27, 2025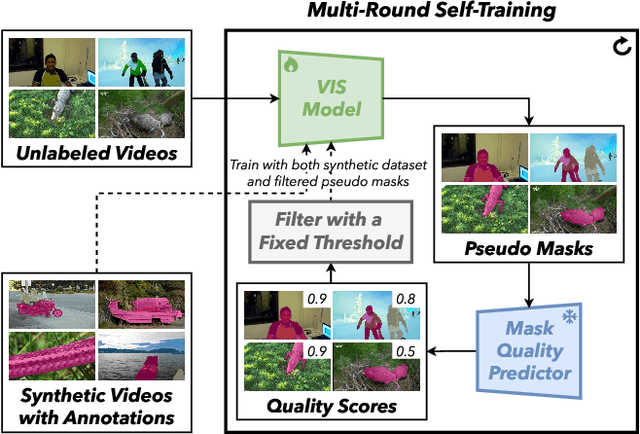
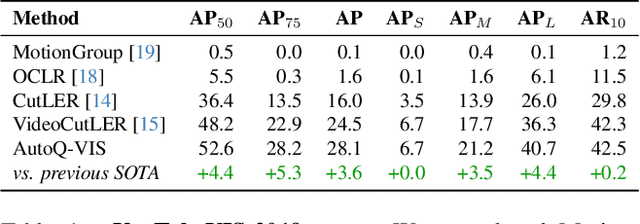
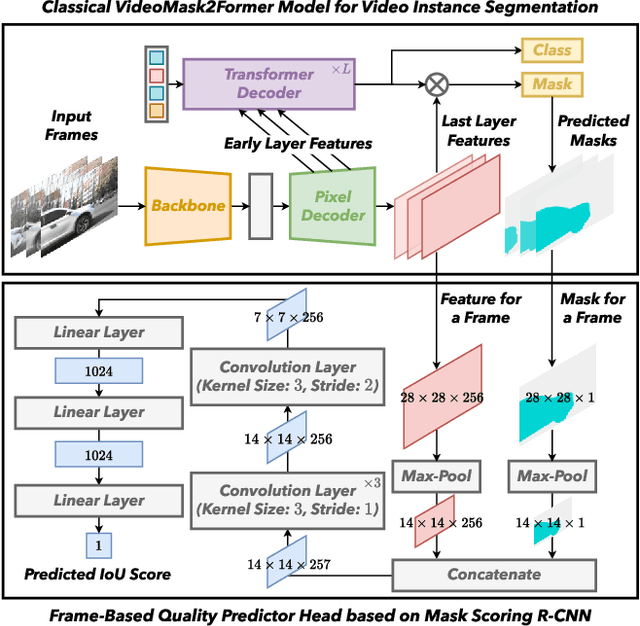

Video Instance Segmentation (VIS) faces significant annotation challenges due to its dual requirements of pixel-level masks and temporal consistency labels. While recent unsupervised methods like VideoCutLER eliminate optical flow dependencies through synthetic data, they remain constrained by the synthetic-to-real domain gap. We present AutoQ-VIS, a novel unsupervised framework that bridges this gap through quality-guided self-training. Our approach establishes a closed-loop system between pseudo-label generation and automatic quality assessment, enabling progressive adaptation from synthetic to real videos. Experiments demonstrate state-of-the-art performance with 52.6 $\text{AP}_{50}$ on YouTubeVIS-2019 val set, surpassing the previous state-of-the-art VideoCutLER by 4.4$\%$, while requiring no human annotations. This demonstrates the viability of quality-aware self-training for unsupervised VIS. The source code of our method is available at https://github.com/wcbup/AutoQ-VIS.
POEM: Precise Object-level Editing via MLLM control
Apr 10, 2025



Diffusion models have significantly improved text-to-image generation, producing high-quality, realistic images from textual descriptions. Beyond generation, object-level image editing remains a challenging problem, requiring precise modifications while preserving visual coherence. Existing text-based instructional editing methods struggle with localized shape and layout transformations, often introducing unintended global changes. Image interaction-based approaches offer better accuracy but require manual human effort to provide precise guidance. To reduce this manual effort while maintaining a high image editing accuracy, in this paper, we propose POEM, a framework for Precise Object-level Editing using Multimodal Large Language Models (MLLMs). POEM leverages MLLMs to analyze instructional prompts and generate precise object masks before and after transformation, enabling fine-grained control without extensive user input. This structured reasoning stage guides the diffusion-based editing process, ensuring accurate object localization and transformation. To evaluate our approach, we introduce VOCEdits, a benchmark dataset based on PASCAL VOC 2012, augmented with instructional edit prompts, ground-truth transformations, and precise object masks. Experimental results show that POEM outperforms existing text-based image editing approaches in precision and reliability while reducing manual effort compared to interaction-based methods.
DDRM-PR: Fourier Phase Retrieval using Denoising Diffusion Restoration Models
Jan 06, 2025



Diffusion models have demonstrated their utility as learned priors for solving various inverse problems. However, most existing approaches are limited to linear inverse problems. This paper exploits the efficient and unsupervised posterior sampling framework of Denoising Diffusion Restoration Models (DDRM) for the solution of nonlinear phase retrieval problem, which requires reconstructing an image from its noisy intensity-only measurements such as Fourier intensity. The approach combines the model-based alternating-projection methods with the DDRM to utilize pretrained unconditional diffusion priors for phase retrieval. The performance is demonstrated through both simulations and experimental data. Results demonstrate the potential of this approach for improving the alternating-projection methods as well as its limitations.