 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Music Track Popularity by Convolutional Neural Networks on Spotify Features and Spectrogram of Audio Waveform
May 12, 2025In the digital streaming landscape, it's becoming increasingly challenging for artists and industry experts to predict the success of music tracks. This study introduces a pioneering methodology that uses Convolutional Neural Networks (CNNs) and Spotify data analysis to forecast the popularity of music tracks. Our approach takes advantage of Spotify's wide range of features, including acoustic attributes based on the spectrogram of audio waveform, metadata, and user engagement metrics, to capture the complex patterns and relationships that influence a track's popularity. Using a large dataset covering various genres and demographics, our CNN-based model shows impressive effectiveness in predicting the popularity of music tracks. Additionally, we've conducted extensive experiments to assess the strength and adaptability of our model across different musical styles and time periods, with promising results yielding a 97\% F1 score. Our study not only offers valuable insights into the dynamic landscape of digital music consumption but also provides the music industry with advanced predictive tools for assessing and predicting the success of music tracks.
Car Sensors Health Monitoring by Verification Based on Autoencoder and Random Forest Regression
May 01, 2025



Driver assistance systems provide a wide range of crucial services, including closely monitoring the condition of vehicles. This paper showcases a groundbreaking sensor health monitoring system designed for the automotive industry. The ingenious system leverages cutting-edge techniques to process data collected from various vehicle sensors. It compares their outputs within the Electronic Control Unit (ECU) to evaluate the health of each sensor. To unravel the intricate correlations between sensor data, an extensive exploration of machine learning and deep learning methodologies was conducted. Through meticulous analysis, the most correlated sensor data were identified. These valuable insights were then utilized to provide accurate estimations of sensor values. Among the diverse learning methods examined, the combination of autoencoders for detecting sensor failures and random forest regression for estimating sensor values proved to yield the most impressive outcomes. A statistical model using the normal distribution has been developed to identify possible sensor failures proactively. By comparing the actual values of the sensors with their estimated values based on correlated sensors, faulty sensors can be detected early. When a defective sensor is detected, both the driver and the maintenance department are promptly alerted. Additionally, the system replaces the value of the faulty sensor with the estimated value obtained through analysis. This proactive approach was evaluated using data from twenty essential sensors in the Saipa's Quick vehicle's ECU, resulting in an impressive accuracy rate of 99\%.
Superior Scoring Rules for Probabilistic Evaluation of Single-Label Multi-Class Classification Tasks
Jul 25, 2024



This study introduces novel superior scoring rules called Penalized Brier Score (PBS) and Penalized Logarithmic Loss (PLL) to improve model evaluation for probabilistic classification. Traditional scoring rules like Brier Score and Logarithmic Loss sometimes assign better scores to misclassifications in comparison with correct classifications. This discrepancy from the actual preference for rewarding correct classifications can lead to suboptimal model selection. By integrating penalties for misclassifications, PBS and PLL modify traditional proper scoring rules to consistently assign better scores to correct predictions. Formal proofs demonstrate that PBS and PLL satisfy strictly proper scoring rule properties while also preferentially rewarding accurate classifications. Experiments showcase the benefits of using PBS and PLL for model selection, model checkpointing, and early stopping. PBS exhibits a higher negative correlation with the F1 score compared to the Brier Score during training. Thus, PBS more effectively identifies optimal checkpoints and early stopping points, leading to improved F1 scores. Comparative analysis verifies models selected by PBS and PLL achieve superior F1 scores. Therefore, PBS and PLL address the gap between uncertainty quantification and accuracy maximization by encapsulating both proper scoring principles and explicit preference for true classifications. The proposed metrics can enhance model evaluation and selection for reliable probabilistic classification.
Checkovid: A COVID-19 misinformation detection system on Twitter using network and content mining perspectives
Jul 20, 2021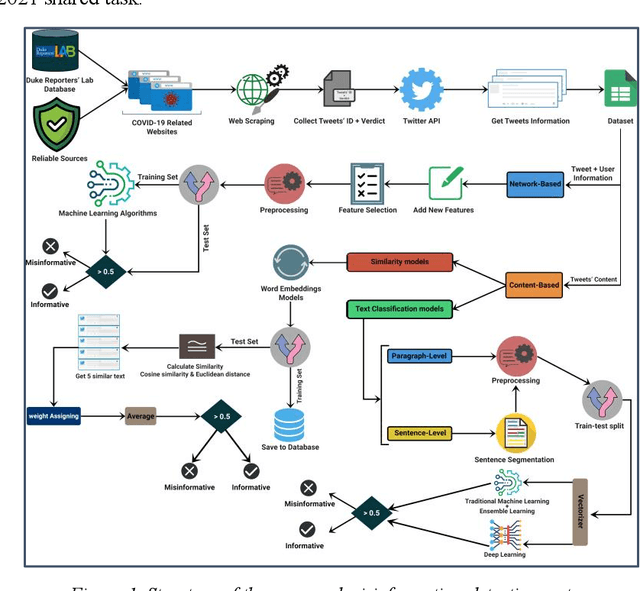

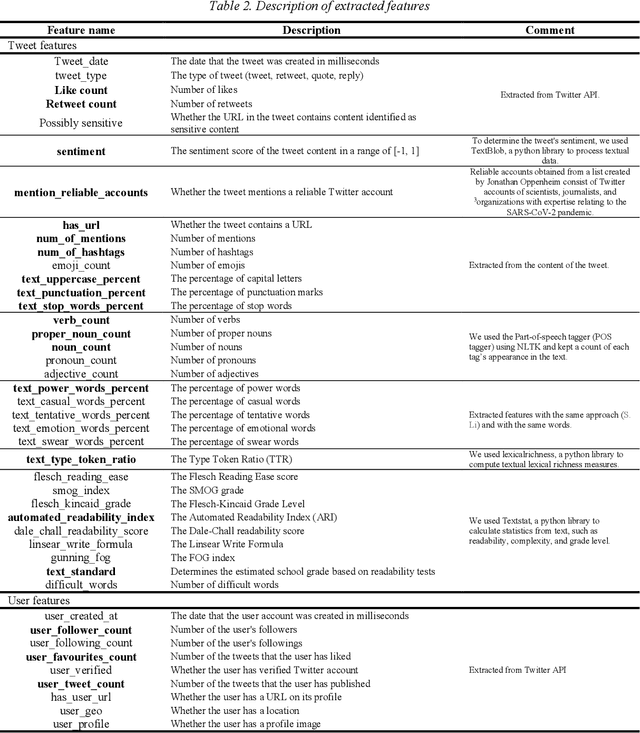
During the COVID-19 pandemic, social media platforms were ideal for communicating due to social isolation and quarantine. Also, it was the primary source of misinformation dissemination on a large scale, referred to as the infodemic. Therefore, automatic debunking misinformation is a crucial problem. To tackle this problem, we present two COVID-19 related misinformation datasets on Twitter and propose a misinformation detection system comprising network-based and content-based processes based on machine learning algorithms and NLP techniques. In the network-based process, we focus on social properties, network characteristics, and users. On the other hand, we classify misinformation using the content of the tweets directly in the content-based process, which contains text classification models (paragraph-level and sentence-level) and similarity models. The evaluation results on the network-based process show the best results for the artificial neural network model with an F1 score of 88.68%. In the content-based process, our novel similarity models, which obtained an F1 score of 90.26%, show an improvement in the misinformation classification results compared to the network-based models. In addition, in the text classification models, the best result was achieved using the stacking ensemble-learning model by obtaining an F1 score of 95.18%. Furthermore, we test our content-based models on the Constraint@AAAI2021 dataset, and by getting an F1 score of 94.38%, we improve the baseline results. Finally, we develop a fact-checking website called Checkovid that uses each process to detect misinformative and informative claims in the domain of COVID-19 from different perspectives.
Low-rank Dictionary Learning for Unsupervised Feature Selection
Jun 21, 2021
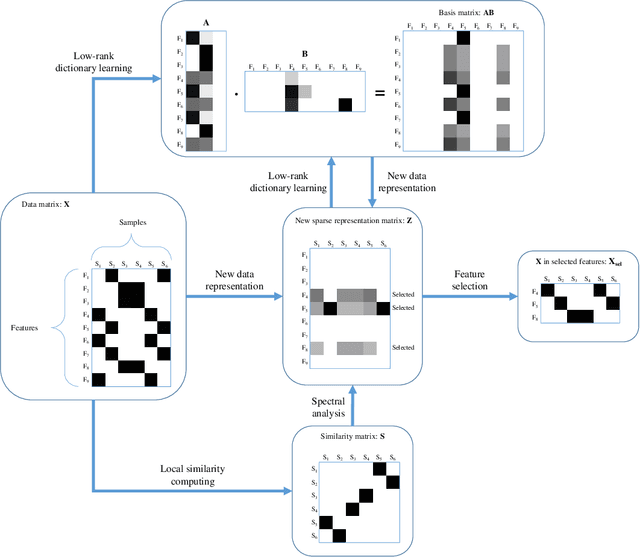
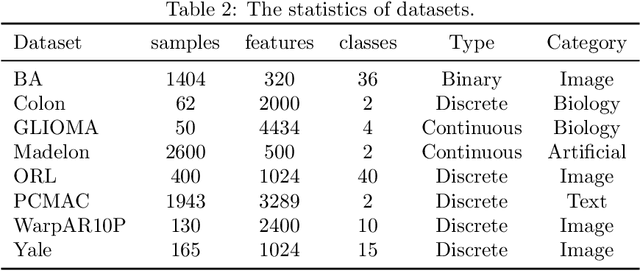
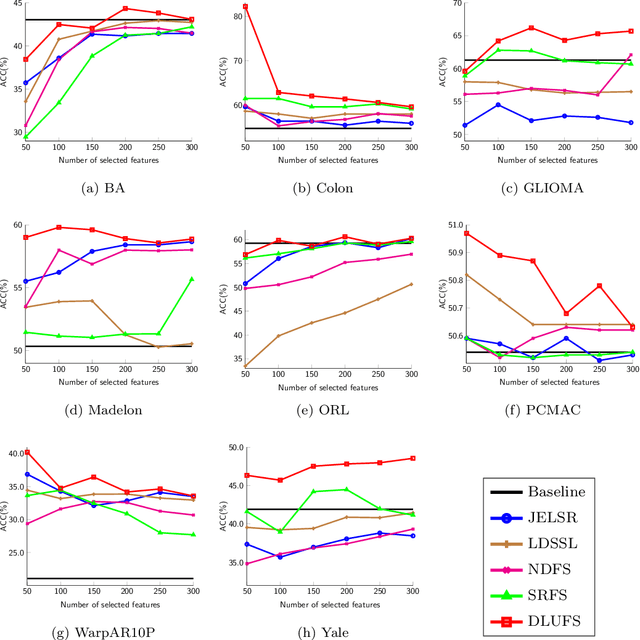
There exist many high-dimensional data in real-world applications such as biology, computer vision, and social networks. Feature selection approaches are devised to confront with high-dimensional data challenges with the aim of efficient learning technologies as well as reduction of models complexity. Due to the hardship of labeling on these datasets, there are a variety of approaches on feature selection process in an unsupervised setting by considering some important characteristics of data. In this paper, we introduce a novel unsupervised feature selection approach by applying dictionary learning ideas in a low-rank representation. Dictionary learning in a low-rank representation not only enables us to provide a new representation, but it also maintains feature correlation. Then, spectral analysis is employed to preserve sample similarities. Finally, a unified objective function for unsupervised feature selection is proposed in a sparse way by an $\ell_{2,1}$-norm regularization. Furthermore, an efficient numerical algorithm is designed to solve the corresponding optimization problem. We demonstrate the performance of the proposed method based on a variety of standard datasets from different applied domains. Our experimental findings reveal that the proposed method outperforms the state-of-the-art algorithm.
Adaptive Low-Rank Regularization with Damping Sequences to Restrict Lazy Weights in Deep Networks
Jun 17, 2021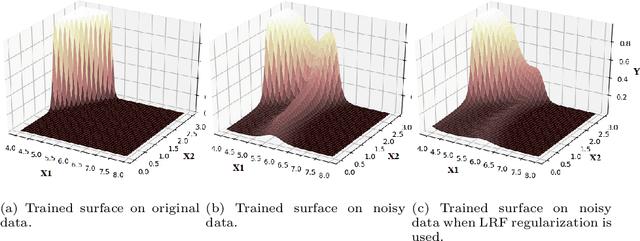
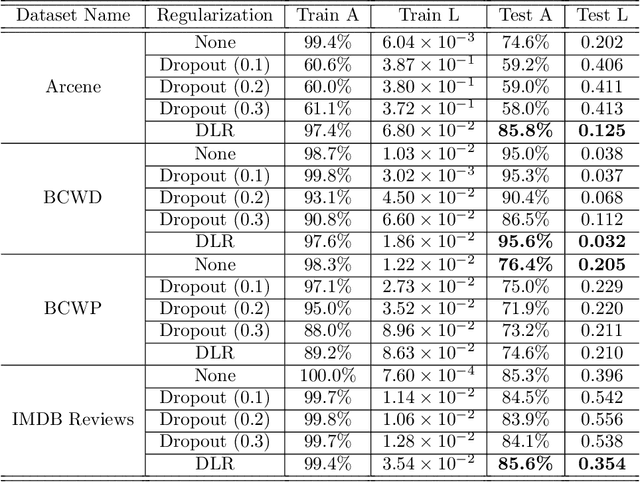
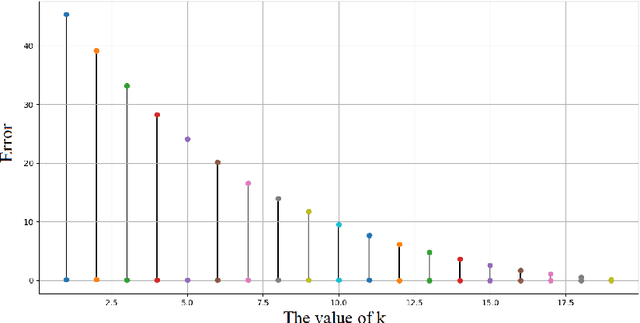
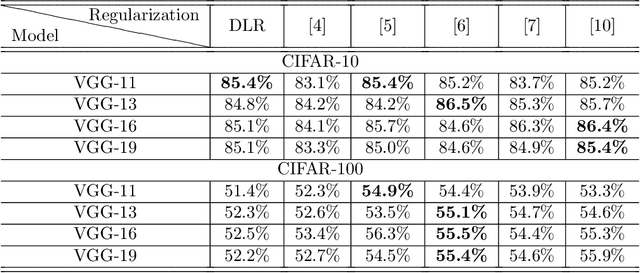
Overfitting is one of the critical problems in deep neural networks. Many regularization schemes try to prevent overfitting blindly. However, they decrease the convergence speed of training algorithms. Adaptive regularization schemes can solve overfitting more intelligently. They usually do not affect the entire network weights. This paper detects a subset of the weighting layers that cause overfitting. The overfitting recognizes by matrix and tensor condition numbers. An adaptive regularization scheme entitled Adaptive Low-Rank (ALR) is proposed that converges a subset of the weighting layers to their Low-Rank Factorization (LRF). It happens by minimizing a new Tikhonov-based loss function. ALR also encourages lazy weights to contribute to the regularization when epochs grow up. It uses a damping sequence to increment layer selection likelihood in the last generations. Thus before falling the training accuracy, ALR reduces the lazy weights and regularizes the network substantially. The experimental results show that ALR regularizes the deep networks well with high training speed and low resource usage.
Diverse and Styled Image Captioning Using SVD-Based Mixture of Recurrent Experts
Jul 07, 2020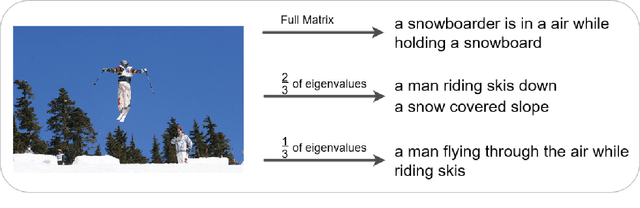
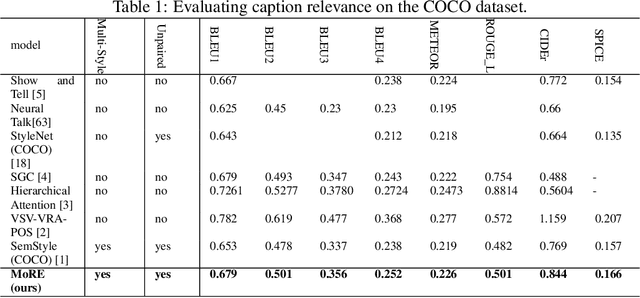
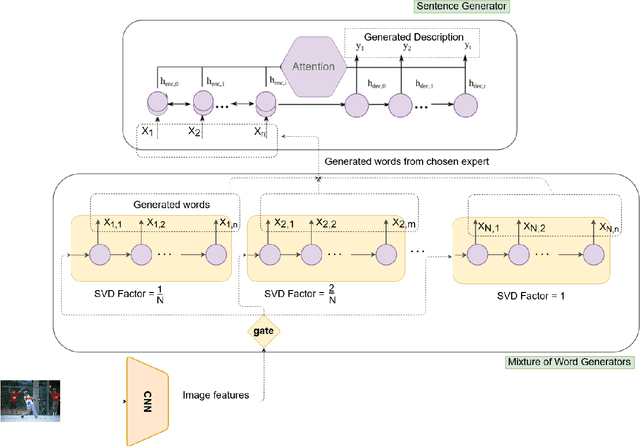

With great advances in vision and natural language processing, the generation of image captions becomes a need. In a recent paper, Mathews, Xie and He [1], extended a new model to generate styled captions by separating semantics and style. In continuation of this work, here a new captioning model is developed including an image encoder to extract the features, a mixture of recurrent networks to embed the set of extracted features to a set of words, and a sentence generator that combines the obtained words as a stylized sentence. The resulted system that entitled as Mixture of Recurrent Experts (MoRE), uses a new training algorithm that derives singular value decomposition (SVD) from weighting matrices of Recurrent Neural Networks (RNNs) to increase the diversity of captions. Each decomposition step depends on a distinctive factor based on the number of RNNs in MoRE. Since the used sentence generator gives a stylized language corpus without paired images, our captioning model can do the same. Besides, the styled and diverse captions are extracted without training on a densely labeled or styled dataset. To validate this captioning model, we use Microsoft COCO which is a standard factual image caption dataset. We show that the proposed captioning model can generate a diverse and stylized image captions without the necessity of extra-labeling. The results also show better descriptions in terms of content accuracy.
Adaptive Low-Rank Factorization to regularize shallow and deep neural networks
May 05, 2020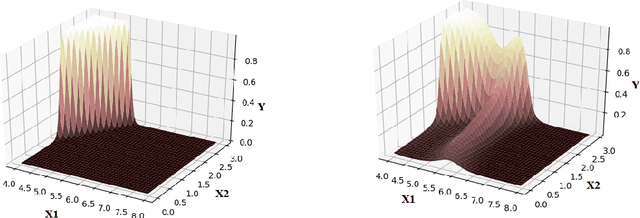
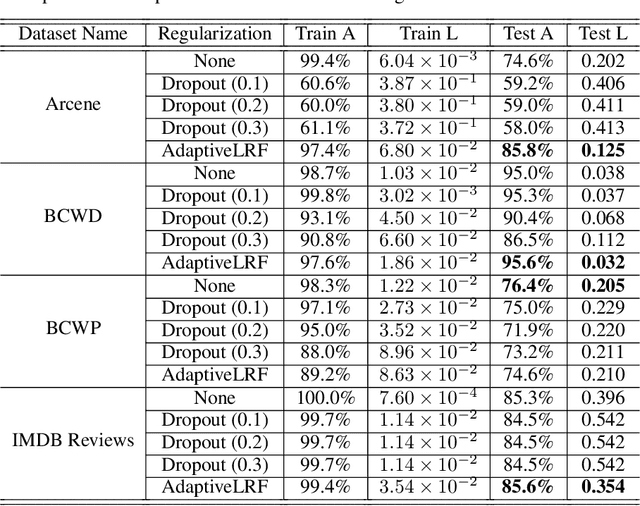
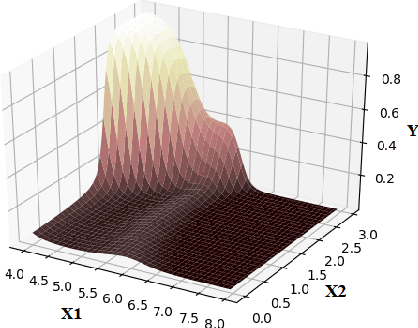
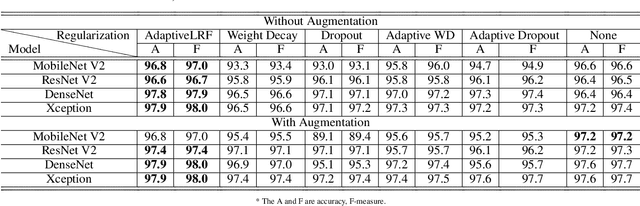
The overfitting is one of the cursing subjects in the deep learning field. To solve this challenge, many approaches were proposed to regularize the learning models. They add some hyper-parameters to the model to extend the generalization; however, it is a hard task to determine these hyper-parameters and a bad setting diverges the training process. In addition, most of the regularization schemes decrease the learning speed. Recently, Tai et al. [1] proposed low-rank tensor decomposition as a constrained filter for removing the redundancy in the convolution kernels of CNN. With a different viewpoint, we use Low-Rank matrix Factorization (LRF) to drop out some parameters of the learning model along the training process. However, this scheme similar to [1] probably decreases the training accuracy when it tries to decrease the number of operations. Instead, we use this regularization scheme adaptively when the complexity of a layer is high. The complexity of any layer can be evaluated by the nonlinear condition numbers of its learning system. The resulted method entitled "AdaptiveLRF" neither decreases the training speed nor vanishes the accuracy of the layer. The behavior of AdaptiveLRF is visualized on a noisy dataset. Then, the improvements are presented on some small-size and large-scale datasets. The preference of AdaptiveLRF on famous dropout regularizers on shallow networks is demonstrated. Also, AdaptiveLRF competes with dropout and adaptive dropout on the various deep networks including MobileNet V2, ResNet V2, DenseNet, and Xception. The best results of AdaptiveLRF on SVHN and CIFAR-10 datasets are 98%, 94.1% F-measure, and 97.9%, 94% accuracy. Finally, we state the usage of the LRF-based loss function to improve the quality of the learning model.
Unsupervised Feature Selection based on Adaptive Similarity Learning and Subspace Clustering
Dec 10, 2019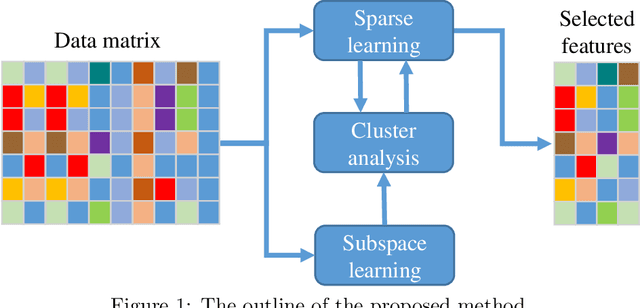

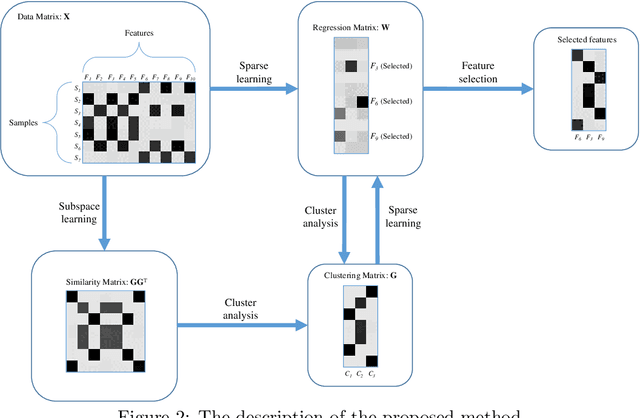
Feature selection methods have an important role on the readability of data and the reduction of complexity of learning algorithms. In recent years, a variety of efforts are investigated on feature selection problems based on unsupervised viewpoint due to the laborious labeling task on large datasets. In this paper, we propose a novel approach on unsupervised feature selection initiated from the subspace clustering to preserve the similarities by representation learning of low dimensional subspaces among the samples. A self-expressive model is employed to implicitly learn the cluster similarities in an adaptive manner. The proposed method not only maintains the sample similarities through subspace clustering, but it also captures the discriminative information based on a regularized regression model. In line with the convergence analysis of the proposed method, the experimental results on benchmark datasets demonstrate the effectiveness of our approach as compared with the state of the art methods.
Regularized Deep Networks in Intelligent Transportation Systems: A Taxonomy and a Case Study
Nov 08, 2019
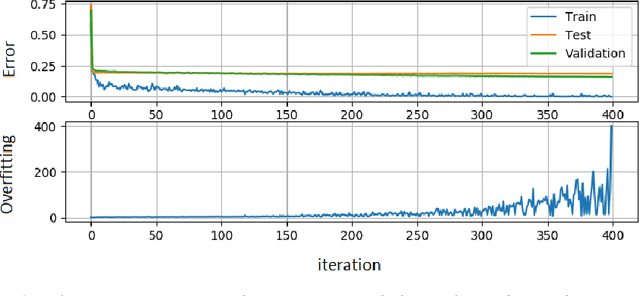
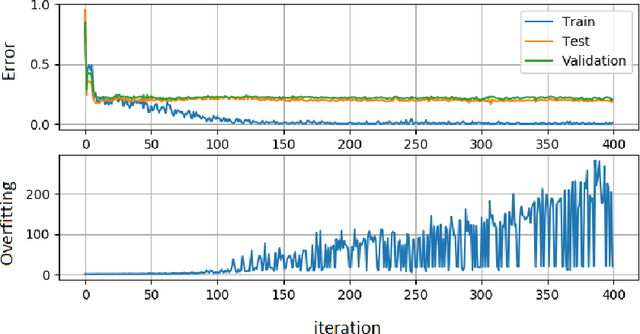
Intelligent Transportation Systems (ITS) are much correlated with data science mechanisms. Among the different correlation branches, this paper focuses on the neural network learning models. Some of the considered models are shallow and they get some user-defined features and learn the relationship, while deep models extract the necessary features before learning by themselves. Both of these paradigms are utilized in the recent intelligent transportation systems (ITS) to support decision-making by the aid of different operations such as frequent patterns mining, regression, clustering, and classification. When these learners cannot generalize the results and just memorize the training samples, they fail to support the necessities. In these cases, the testing error is bigger than the training error. This phenomenon is addressed as overfitting in the literature. Because, this issue decreases the reliability of learning systems, in ITS applications, we cannot use such over-fitted machine learning models for different tasks such as traffic prediction, the signal controlling, safety applications, emergency responses, mode detection, driving evaluation, etc. Besides, deep learning models use a great number of hyper-parameters, the overfitting in deep models is more attention. To solve this problem, the regularized learning models can be followed. The aim of this paper is to review the approaches presented to regularize the overfitting in different categories of ITS studies. Then, we give a case study on driving safety that uses a regularized version of the convolutional neural network (CNN).