 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing Classifier Adjacency Relations: A Case Study in Speaker Verification and Voice Anti-Spoofing
Jun 11, 2021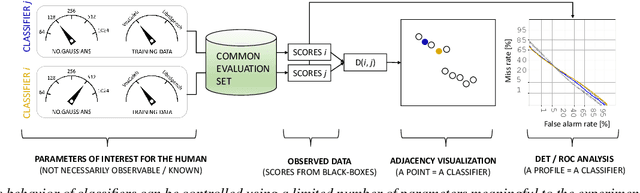
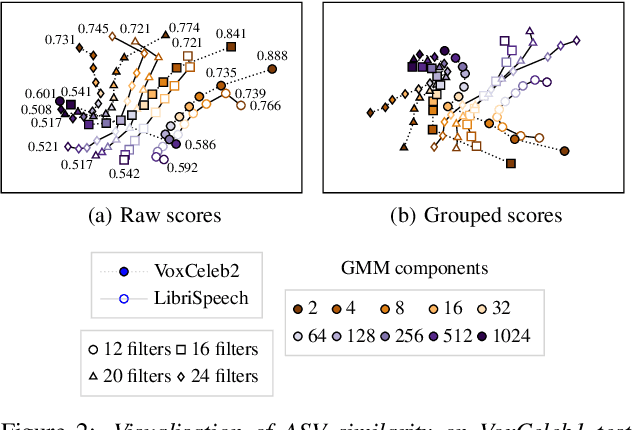
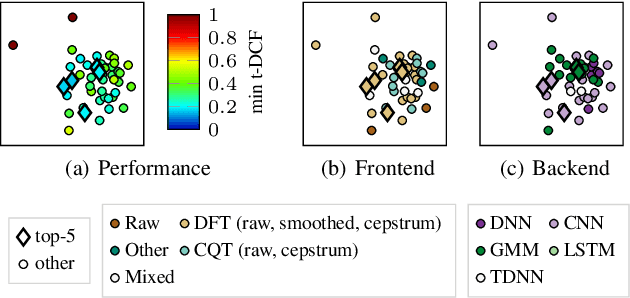
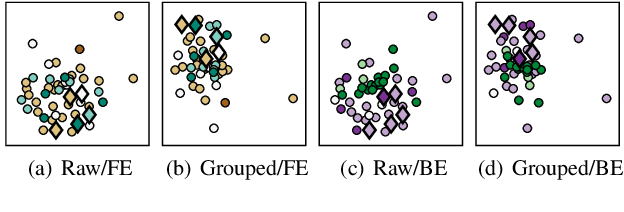
Whether it be for results summarization, or the analysis of classifier fusion, some means to compare different classifiers can often provide illuminating insight into their behaviour, (dis)similarity or complementarity. We propose a simple method to derive 2D representation from detection scores produced by an arbitrary set of binary classifiers in response to a common dataset. Based upon rank correlations, our method facilitates a visual comparison of classifiers with arbitrary scores and with close relation to receiver operating characteristic (ROC) and detection error trade-off (DET) analyses. While the approach is fully versatile and can be applied to any detection task, we demonstrate the method using scores produced by automatic speaker verification and voice anti-spoofing systems. The former are produced by a Gaussian mixture model system trained with VoxCeleb data whereas the latter stem from submissions to the ASVspoof 2019 challenge.
StutterNet: Stuttering Detection Using Time Delay Neural Network
Jun 08, 2021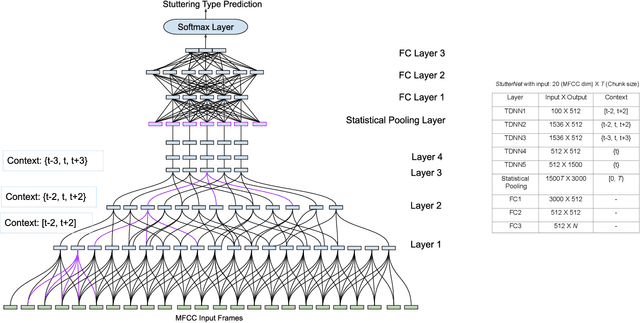
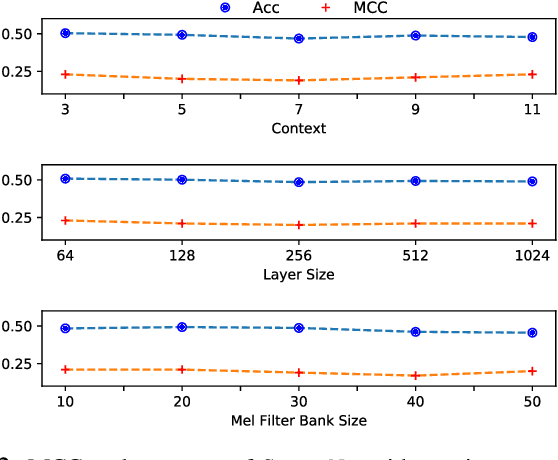
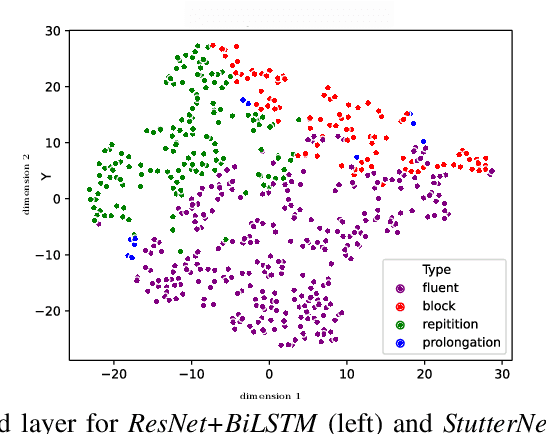

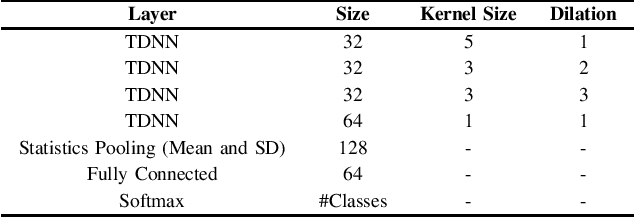
This paper introduces StutterNet, a novel deep learning based stuttering detection capable of detecting and identifying various types of disfluencies. Most of the existing work in this domain uses automatic speech recognition (ASR) combined with language models for stuttering detection. Compared to the existing work, which depends on the ASR module, our method relies solely on the acoustic signal. We use a time-delay neural network (TDNN) suitable for capturing contextual aspects of the disfluent utterances. We evaluate our system on the UCLASS stuttering dataset consisting of more than 100 speakers. Our method achieves promising results and outperforms the state-of-the-art residual neural network based method. The number of trainable parameters of the proposed method is also substantially less due to the parameter sharing scheme of TDNN.
Utterance partitioning for speaker recognition: an experimental review and analysis with new findings under GMM-SVM framework
May 25, 2021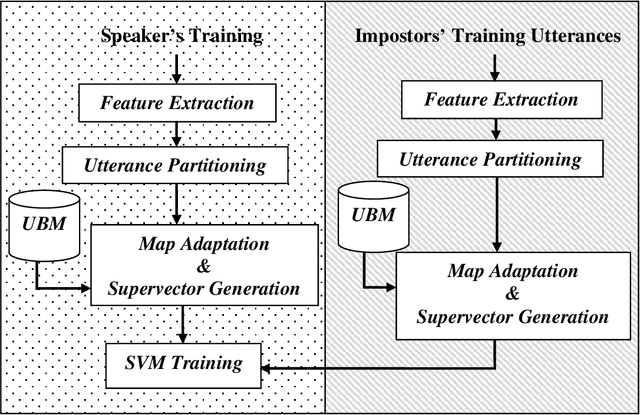
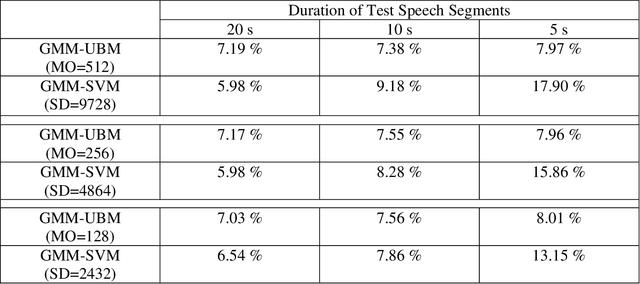
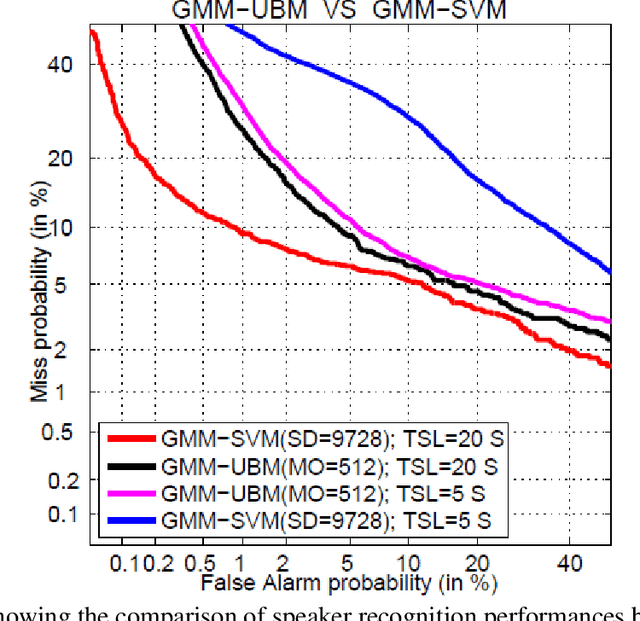
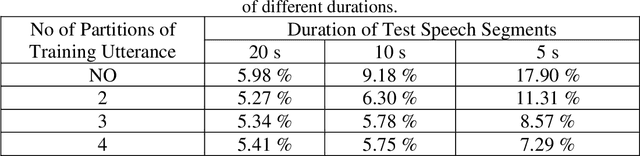
The performance of speaker recognition system is highly dependent on the amount of speech used in enrollment and test. This work presents a detailed experimental review and analysis of the GMM-SVM based speaker recognition system in presence of duration variability. This article also reports a comparison of the performance of GMM-SVM classifier with its precursor technique Gaussian mixture model-universal background model (GMM-UBM) classifier in presence of duration variability. The goal of this research work is not to propose a new algorithm for improving speaker recognition performance in presence of duration variability. However, the main focus of this work is on utterance partitioning (UP), a commonly used strategy to compensate the duration variability issue. We have analysed in detailed the impact of training utterance partitioning in speaker recognition performance under GMM-SVM framework. We further investigate the reason why the utterance partitioning is important for boosting speaker recognition performance. We have also shown in which case the utterance partitioning could be useful and where not. Our study has revealed that utterance partitioning does not reduce the data imbalance problem of the GMM-SVM classifier as claimed in earlier study. Apart from these, we also discuss issues related to the impact of parameters such as number of Gaussians, supervector length, amount of splitting required for obtaining better performance in short and long duration test conditions from speech duration perspective. We have performed the experiments with telephone speech from POLYCOST corpus consisting of 130 speakers.
Cross-Corpora Language Recognition: A Preliminary Investigation with Indian Languages
May 12, 2021
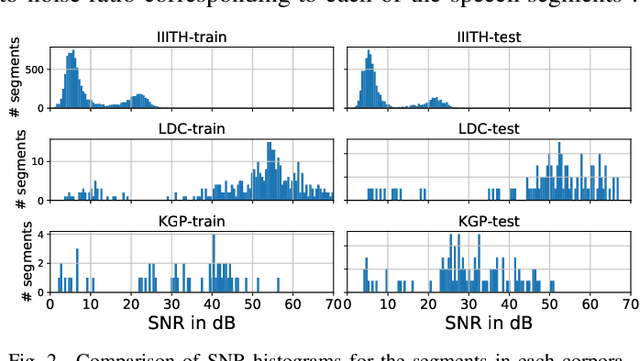
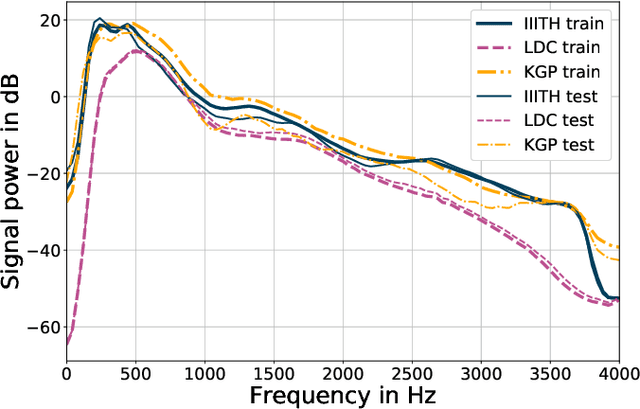
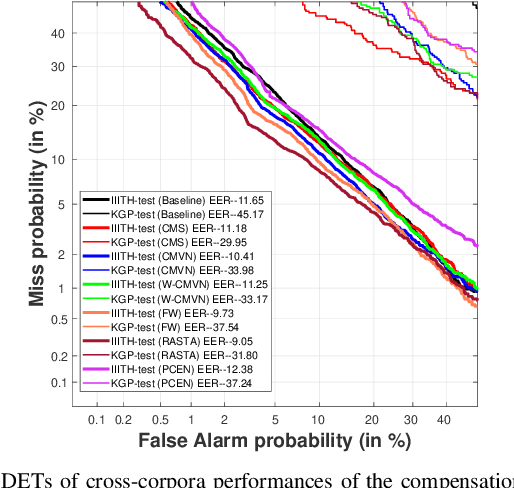
In this paper, we conduct one of the very first studies for cross-corpora performance evaluation in the spoken language identification (LID) problem. Cross-corpora evaluation was not explored much in LID research, especially for the Indian languages. We have selected three Indian spoken language corpora: IIITH-ILSC, LDC South Asian, and IITKGP-MLILSC. For each of the corpus, LID systems are trained on the state-of-the-art time-delay neural network (TDNN) based architecture with MFCC features. We observe that the LID performance degrades drastically for cross-corpora evaluation. For example, the system trained on the IIITH-ILSC corpus shows an average EER of 11.80 % and 43.34 % when evaluated with the same corpora and LDC South Asian corpora, respectively. Our preliminary analysis shows the significant differences among these corpora in terms of mismatch in the long-term average spectrum (LTAS) and signal-to-noise ratio (SNR). Subsequently, we apply different feature level compensation methods to reduce the cross-corpora acoustic mismatch. Our results indicate that these feature normalization schemes can help to achieve promising LID performance on cross-corpora experiments.
Deep scattering network for speech emotion recognition
May 11, 2021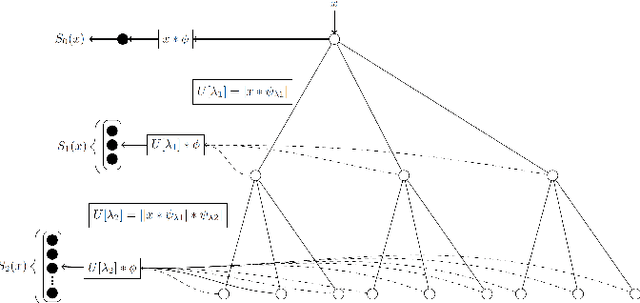
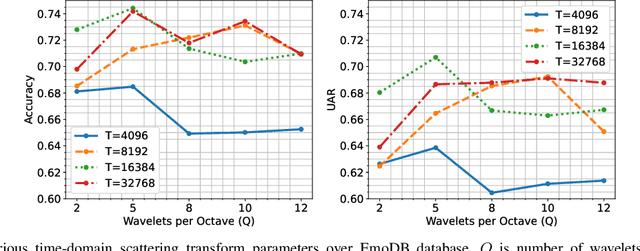

This paper introduces scattering transform for speech emotion recognition (SER). Scattering transform generates feature representations which remain stable to deformations and shifting in time and frequency without much loss of information. In speech, the emotion cues are spread across time and localised in frequency. The time and frequency invariance characteristic of scattering coefficients provides a representation robust against emotion irrelevant variations e.g., different speakers, language, gender etc. while preserving the variations caused by emotion cues. Hence, such a representation captures the emotion information more efficiently from speech. We perform experiments to compare scattering coefficients with standard mel-frequency cepstral coefficients (MFCCs) over different databases. It is observed that frequency scattering performs better than time-domain scattering and MFCCs. We also investigate layer-wise scattering coefficients to analyse the importance of time shift and deformation stable scalogram and modulation spectrum coefficients for SER. We observe that layer-wise coefficients taken independently also perform better than MFCCs.
Data Quality as Predictor of Voice Anti-Spoofing Generalization
Mar 26, 2021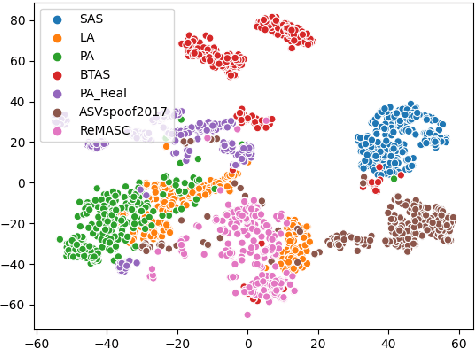
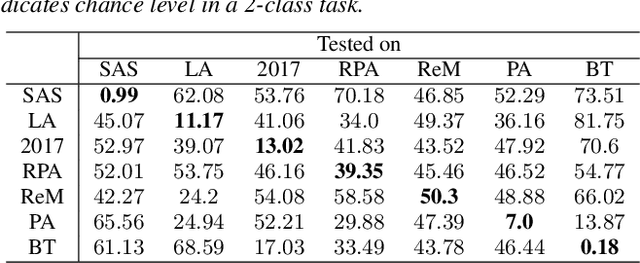
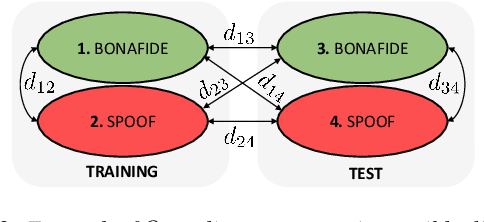
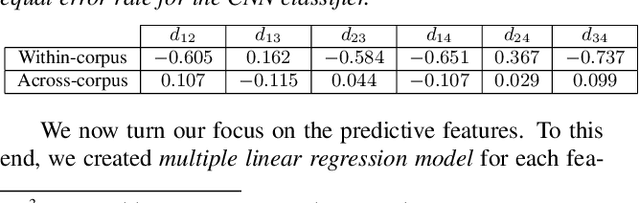
Voice anti-spoofing aims at classifying a given speech input either as a bonafide human sample, or a spoofing attack (e.g. synthetic or replayed sample). Numerous voice anti-spoofing methods have been proposed but most of them fail to generalize across domains (corpora) -- and we do not know \emph{why}. We outline a novel interpretative framework for gauging the impact of data quality upon anti-spoofing performance. Our within- and between-domain experiments pool data from seven public corpora and three anti-spoofing methods based on Gaussian mixture and convolutive neural network models. We assess the impacts of long-term spectral information, speaker population (through x-vector speaker embeddings), signal-to-noise ratio, and selected voice quality features.
Learnable MFCCs for Speaker Verification
Feb 20, 2021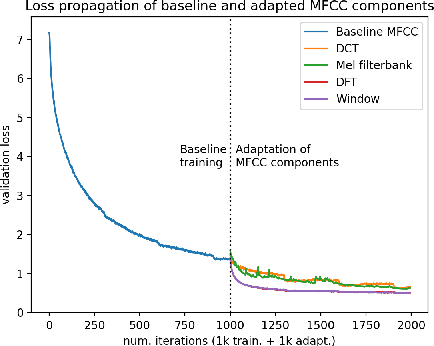
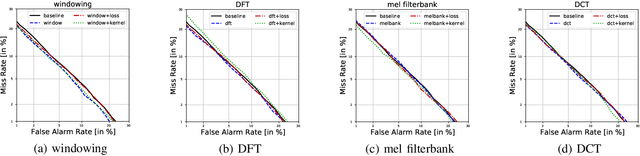
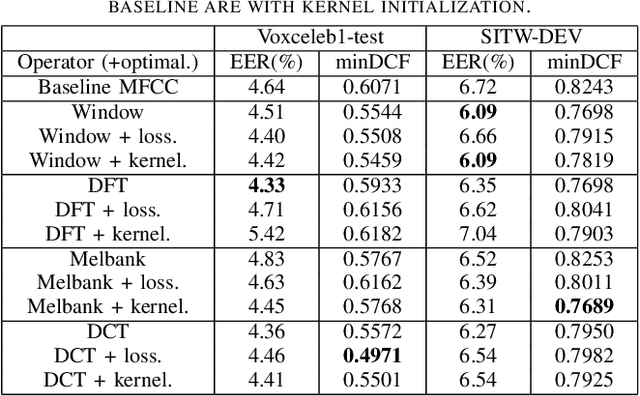
We propose a learnable mel-frequency cepstral coefficient (MFCC) frontend architecture for deep neural network (DNN) based automatic speaker verification. Our architecture retains the simplicity and interpretability of MFCC-based features while allowing the model to be adapted to data flexibly. In practice, we formulate data-driven versions of the four linear transforms of a standard MFCC extractor -- windowing, discrete Fourier transform (DFT), mel filterbank and discrete cosine transform (DCT). Results reported reach up to 6.7\% (VoxCeleb1) and 9.7\% (SITW) relative improvement in term of equal error rate (EER) from static MFCCs, without additional tuning effort.
ASVspoof 2019: spoofing countermeasures for the detection of synthesized, converted and replayed speech
Feb 11, 2021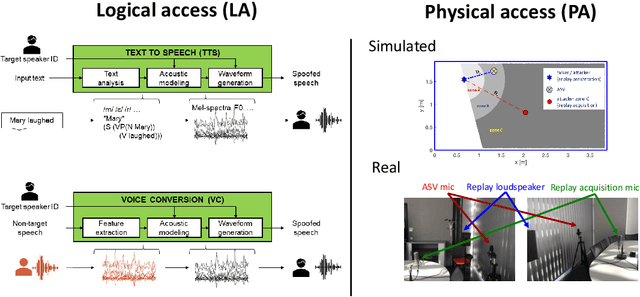
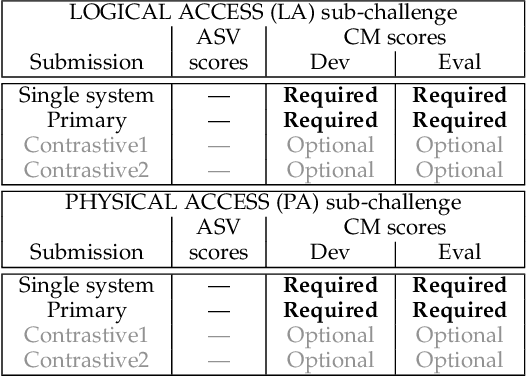
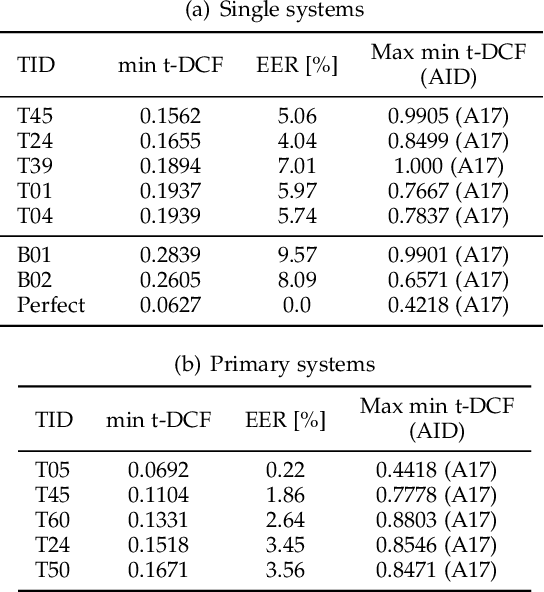
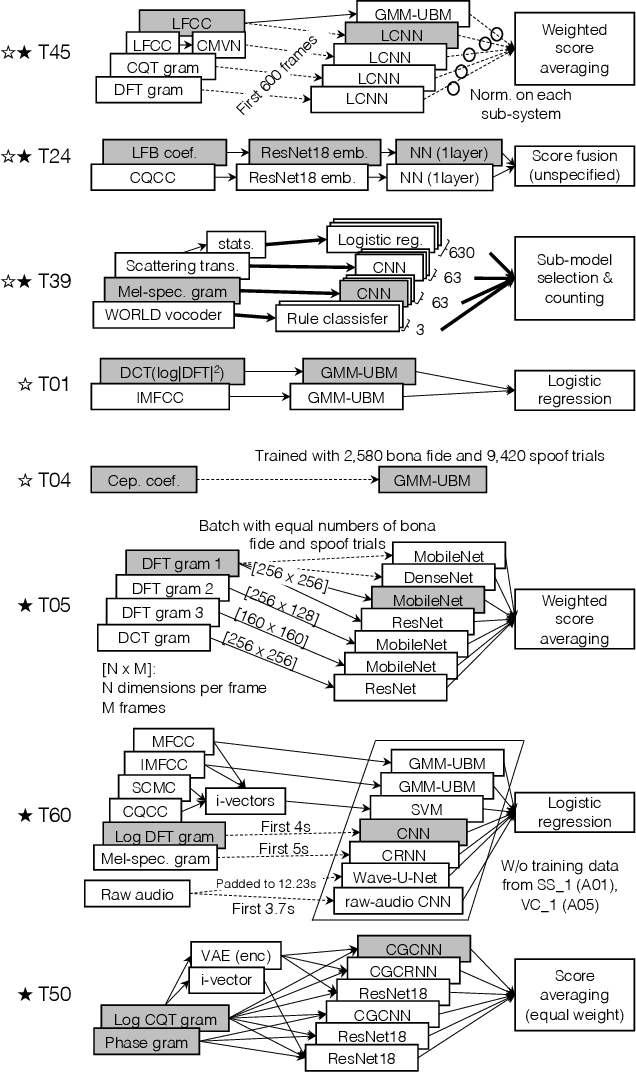
The ASVspoof initiative was conceived to spearhead research in anti-spoofing for automatic speaker verification (ASV). This paper describes the third in a series of bi-annual challenges: ASVspoof 2019. With the challenge database and protocols being described elsewhere, the focus of this paper is on results and the top performing single and ensemble system submissions from 62 teams, all of which out-perform the two baseline systems, often by a substantial margin. Deeper analyses shows that performance is dominated by specific conditions involving either specific spoofing attacks or specific acoustic environments. While fusion is shown to be particularly effective for the logical access scenario involving speech synthesis and voice conversion attacks, participants largely struggled to apply fusion successfully for the physical access scenario involving simulated replay attacks. This is likely the result of a lack of system complementarity, while oracle fusion experiments show clear potential to improve performance. Furthermore, while results for simulated data are promising, experiments with real replay data show a substantial gap, most likely due to the presence of additive noise in the latter. This finding, among others, leads to a number of ideas for further research and directions for future editions of the ASVspoof challenge.
ABSP System for The Third DIHARD Challenge
Feb 10, 2021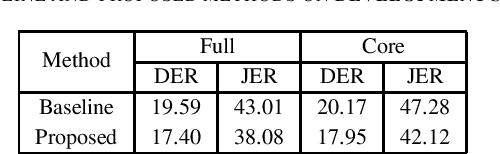
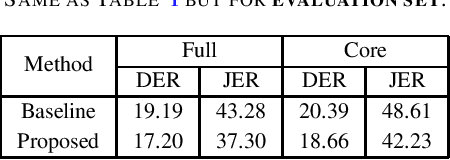
This report describes the speaker diarization system developed by the ABSP Laboratory team for the third DIHARD speech diarization challenge. Our primary contribution is to develop acoustic domain identification (ADI) system for speaker diarization. We investigate speaker embeddings based ADI system. We apply a domain-dependent threshold for agglomerative hierarchical clustering. Besides, we optimize the parameters for PCA-based dimensionality reduction in a domain-dependent way. Our method of integrating domain-based processing schemes in the baseline system of the challenge achieved a relative improvement of $9.63\%$ and $10.64\%$ in DER for core and full conditions, respectively, for Track 1 of the DIHARD III evaluation set.
Non-linear frequency warping using constant-Q transformation for speech emotion recognition
Feb 08, 2021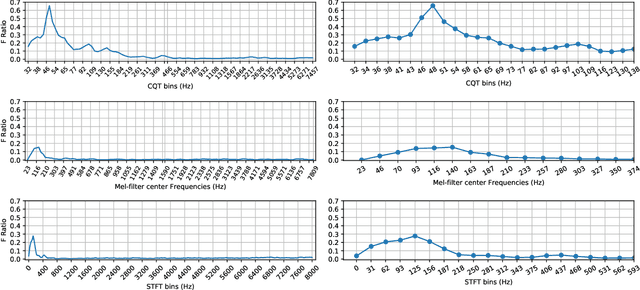
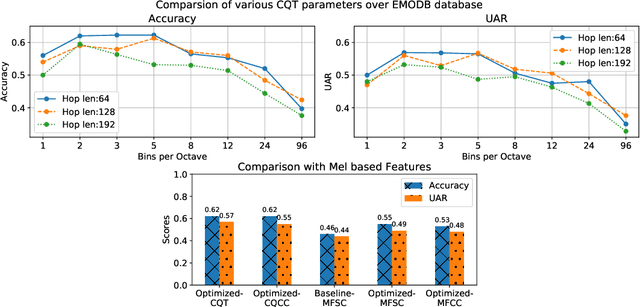

In this work, we explore the constant-Q transform (CQT) for speech emotion recognition (SER). The CQT-based time-frequency analysis provides variable spectro-temporal resolution with higher frequency resolution at lower frequencies. Since lower-frequency regions of speech signal contain more emotion-related information than higher-frequency regions, the increased low-frequency resolution of CQT makes it more promising for SER than standard short-time Fourier transform (STFT). We present a comparative analysis of short-term acoustic features based on STFT and CQT for SER with deep neural network (DNN) as a back-end classifier. We optimize different parameters for both features. The CQT-based features outperform the STFT-based spectral features for SER experiments. Further experiments with cross-corpora evaluation demonstrate that the CQT-based systems provide better generalization with out-of-domain training data.