 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing ECAPA-TDNN and Wav2Vec2.0 Embeddings to Stuttering Detection
Apr 04, 2022
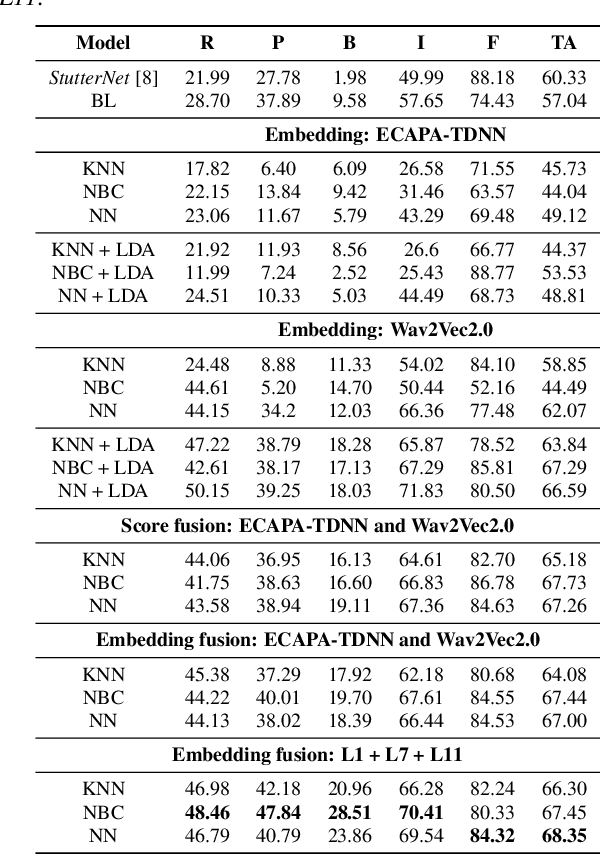

The adoption of advanced deep learning (DL) architecture in stuttering detection (SD) tasks is challenging due to the limited size of the available datasets. To this end, this work introduces the application of speech embeddings extracted with pre-trained deep models trained on massive audio datasets for different tasks. In particular, we explore audio representations obtained using emphasized channel attention, propagation, and aggregation-time-delay neural network (ECAPA-TDNN) and Wav2Vec2.0 model trained on VoxCeleb and LibriSpeech datasets respectively. After extracting the embeddings, we benchmark with several traditional classifiers, such as a k-nearest neighbor, Gaussian naive Bayes, and neural network, for the stuttering detection tasks. In comparison to the standard SD system trained only on the limited SEP-28k dataset, we obtain a relative improvement of 16.74% in terms of overall accuracy over baseline. Finally, we have shown that combining two embeddings and concatenating multiple layers of Wav2Vec2.0 can further improve SD performance up to 1% and 2.64% respectively.
Spoofing-Aware Speaker Verification with Unsupervised Domain Adaptation
Mar 21, 2022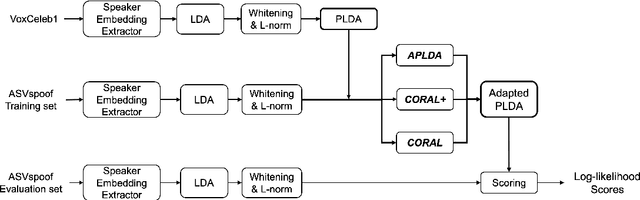
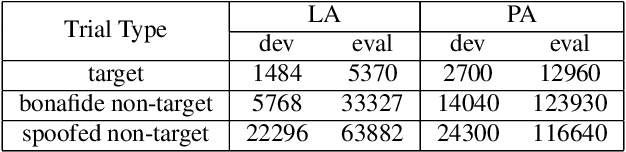
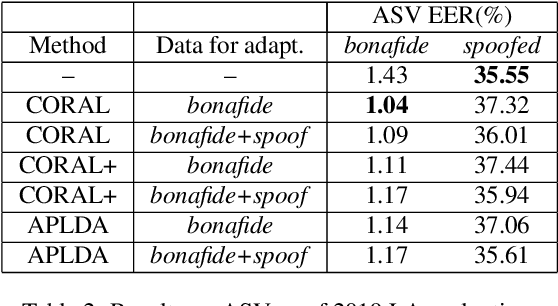
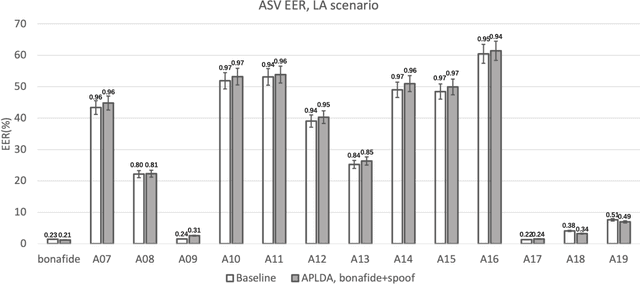
In this paper, we initiate the concern of enhancing the spoofing robustness of the automatic speaker verification (ASV) system, without the primary presence of a separate countermeasure module. We start from the standard ASV framework of the ASVspoof 2019 baseline and approach the problem from the back-end classifier based on probabilistic linear discriminant analysis. We employ three unsupervised domain adaptation techniques to optimize the back-end using the audio data in the training partition of the ASVspoof 2019 dataset. We demonstrate notable improvements on both logical and physical access scenarios, especially on the latter where the system is attacked by replayed audios, with a maximum of 36.1% and 5.3% relative improvement on bonafide and spoofed cases, respectively. We perform additional studies such as per-attack breakdown analysis, data composition, and integration with a countermeasure system at score-level with Gaussian back-end.
Learnable Nonlinear Compression for Robust Speaker Verification
Feb 10, 2022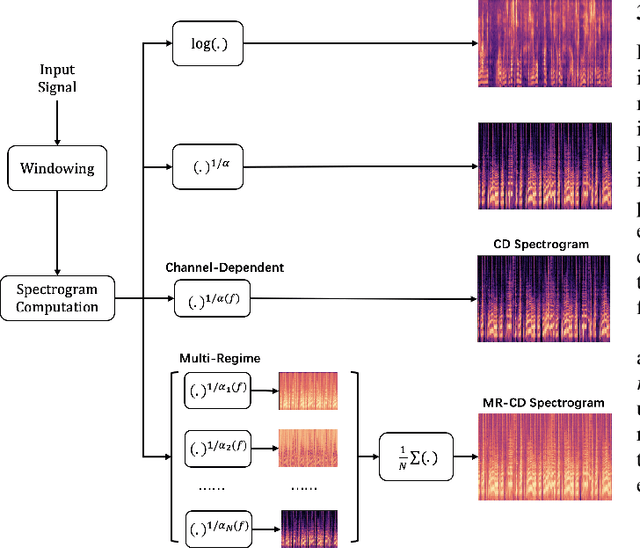

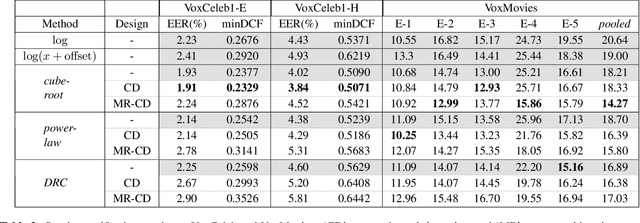
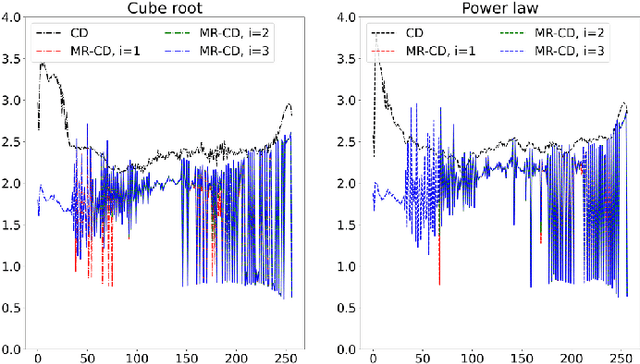
In this study, we focus on nonlinear compression methods in spectral features for speaker verification based on deep neural network. We consider different kinds of channel-dependent (CD) nonlinear compression methods optimized in a data-driven manner. Our methods are based on power nonlinearities and dynamic range compression (DRC). We also propose multi-regime (MR) design on the nonlinearities, at improving robustness. Results on VoxCeleb1 and VoxMovies data demonstrate improvements brought by proposed compression methods over both the commonly-used logarithm and their static counterparts, especially for ones based on power function. While CD generalization improves performance on VoxCeleb1, MR provides more robustness on VoxMovies, with a maximum relative equal error rate reduction of 21.6%.
Optimizing Multi-Taper Features for Deep Speaker Verification
Oct 21, 2021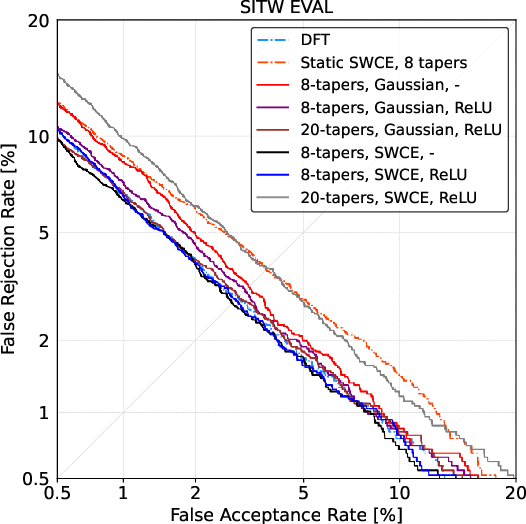
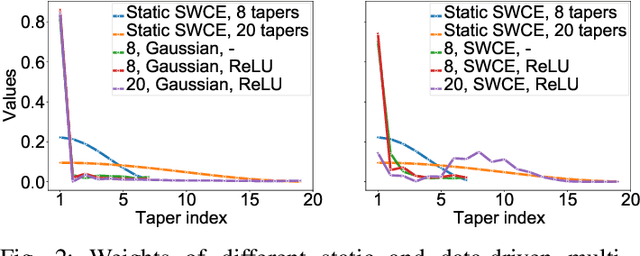
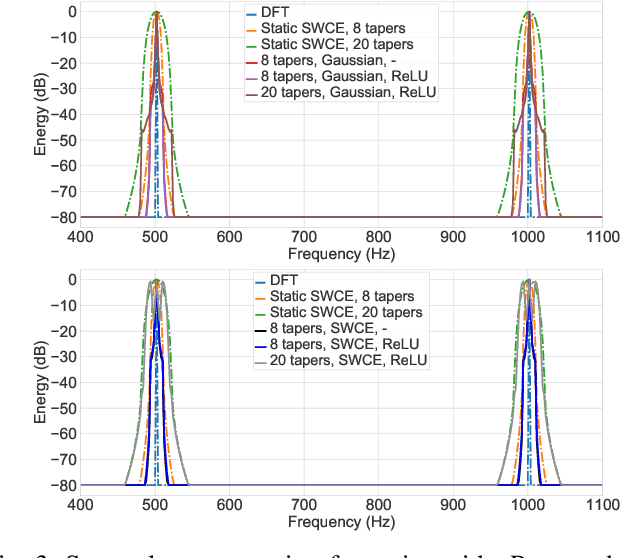
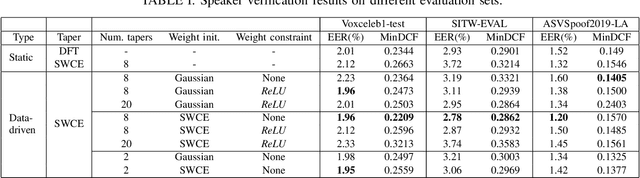
Multi-taper estimators provide low-variance power spectrum estimates that can be used in place of the windowed discrete Fourier transform (DFT) to extract speech features such as mel-frequency cepstral coefficients (MFCCs). Even if past work has reported promising automatic speaker verification (ASV) results with Gaussian mixture model-based classifiers, the performance of multi-taper MFCCs with deep ASV systems remains an open question. Instead of a static-taper design, we propose to optimize the multi-taper estimator jointly with a deep neural network trained for ASV tasks. With a maximum improvement on the SITW corpus of 25.8% in terms of equal error rate over the static-taper, our method helps preserve a balanced level of leakage and variance, providing more robustness.
Optimized Power Normalized Cepstral Coefficients towards Robust Deep Speaker Verification
Sep 24, 2021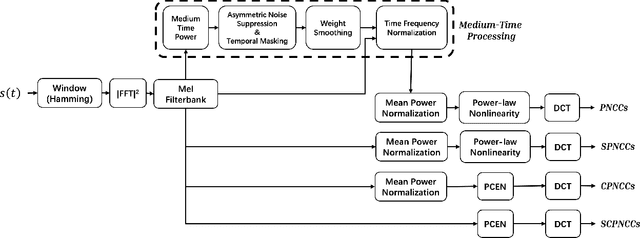
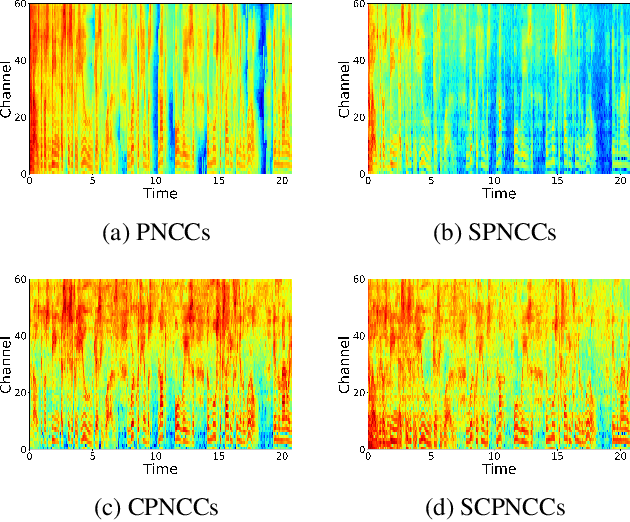
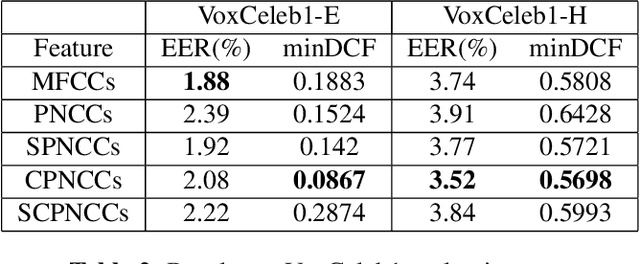
After their introduction to robust speech recognition, power normalized cepstral coefficient (PNCC) features were successfully adopted to other tasks, including speaker verification. However, as a feature extractor with long-term operations on the power spectrogram, its temporal processing and amplitude scaling steps dedicated on environmental compensation may be redundant. Further, they might suppress intrinsic speaker variations that are useful for speaker verification based on deep neural networks (DNN). Therefore, in this study, we revisit and optimize PNCCs by ablating its medium-time processor and by introducing channel energy normalization. Experimental results with a DNN-based speaker verification system indicate substantial improvement over baseline PNCCs on both in-domain and cross-domain scenarios, reflected by relatively 5.8% and 61.2% maximum lower equal error rate on VoxCeleb1 and VoxMovies, respectively.
Parameterized Channel Normalization for Far-field Deep Speaker Verification
Sep 24, 2021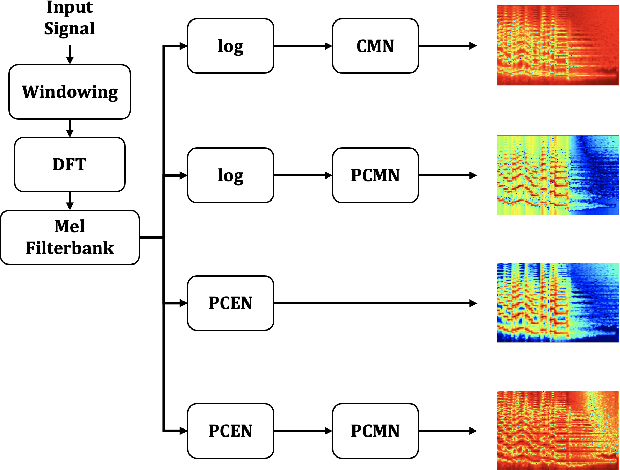
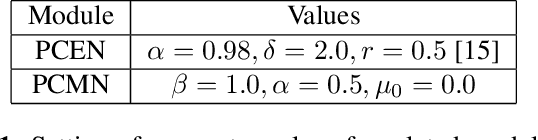
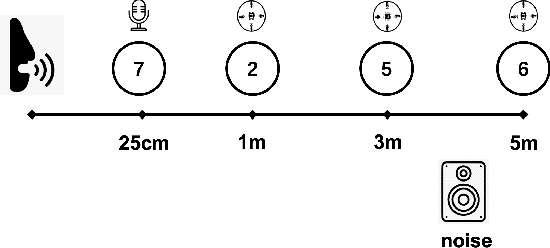
We address far-field speaker verification with deep neural network (DNN) based speaker embedding extractor, where mismatch between enrollment and test data often comes from convolutive effects (e.g. room reverberation) and noise. To mitigate these effects, we focus on two parametric normalization methods: per-channel energy normalization (PCEN) and parameterized cepstral mean normalization (PCMN). Both methods contain differentiable parameters and thus can be conveniently integrated to, and jointly optimized with the DNN using automatic differentiation methods. We consider both fixed and trainable (data-driven) variants of each method. We evaluate the performance on Hi-MIA, a recent large-scale far-field speech corpus, with varied microphone and positional settings. Our methods outperform conventional mel filterbank features, with maximum of 33.5% and 39.5% relative improvement on equal error rate under matched microphone and mismatched microphone conditions, respectively.
ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection
Sep 01, 2021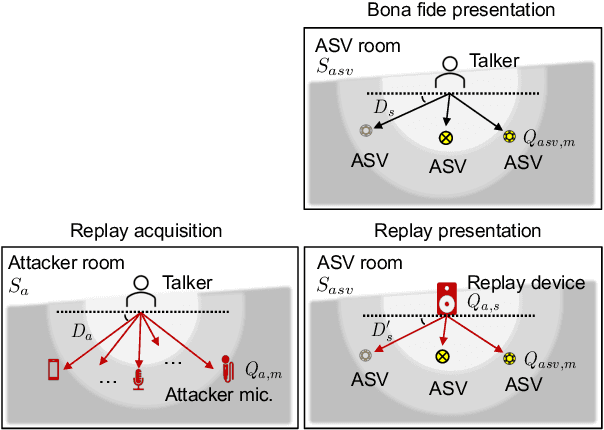
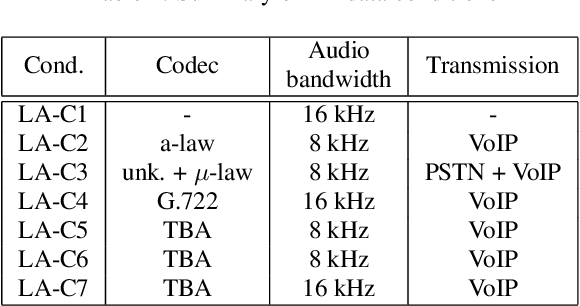
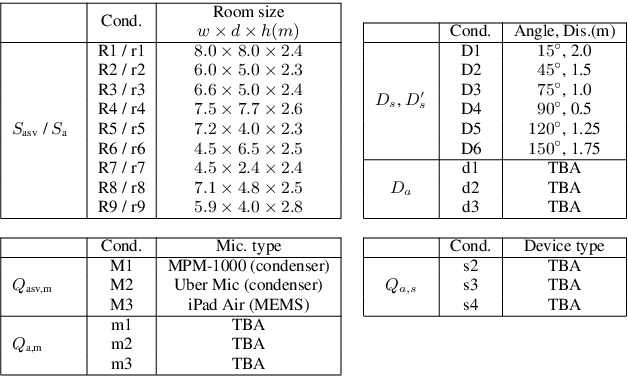
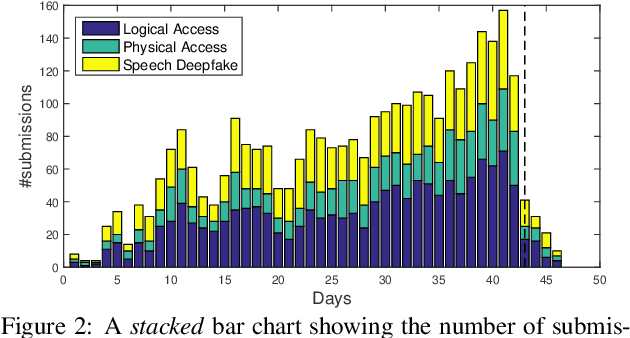
ASVspoof 2021 is the forth edition in the series of bi-annual challenges which aim to promote the study of spoofing and the design of countermeasures to protect automatic speaker verification systems from manipulation. In addition to a continued focus upon logical and physical access tasks in which there are a number of advances compared to previous editions, ASVspoof 2021 introduces a new task involving deepfake speech detection. This paper describes all three tasks, the new databases for each of them, the evaluation metrics, four challenge baselines, the evaluation platform and a summary of challenge results. Despite the introduction of channel and compression variability which compound the difficulty, results for the logical access and deepfake tasks are close to those from previous ASVspoof editions. Results for the physical access task show the difficulty in detecting attacks in real, variable physical spaces. With ASVspoof 2021 being the first edition for which participants were not provided with any matched training or development data and with this reflecting real conditions in which the nature of spoofed and deepfake speech can never be predicated with confidence, the results are extremely encouraging and demonstrate the substantial progress made in the field in recent years.
ASVspoof 2021: Automatic Speaker Verification Spoofing and Countermeasures Challenge Evaluation Plan
Sep 01, 2021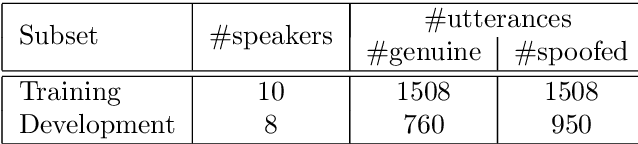
The automatic speaker verification spoofing and countermeasures (ASVspoof) challenge series is a community-led initiative which aims to promote the consideration of spoofing and the development of countermeasures. ASVspoof 2021 is the 4th in a series of bi-annual, competitive challenges where the goal is to develop countermeasures capable of discriminating between bona fide and spoofed or deepfake speech. This document provides a technical description of the ASVspoof 2021 challenge, including details of training, development and evaluation data, metrics, baselines, evaluation rules, submission procedures and the schedule.
Benchmarking and challenges in security and privacy for voice biometrics
Sep 01, 2021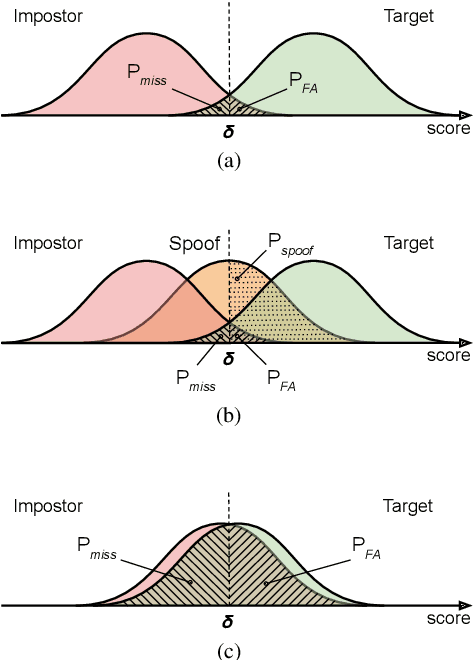
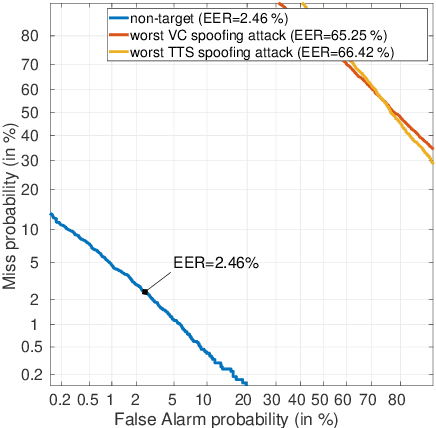
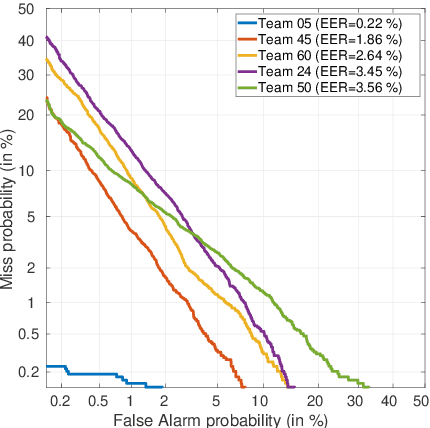
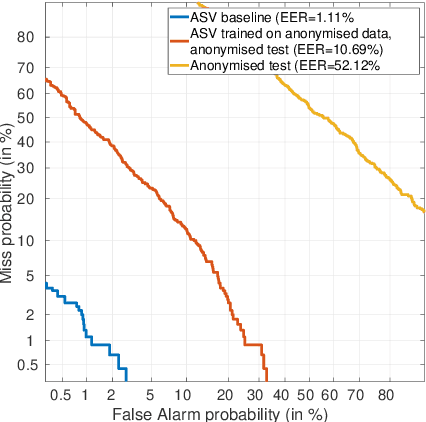
For many decades, research in speech technologies has focused upon improving reliability. With this now meeting user expectations for a range of diverse applications, speech technology is today omni-present. As result, a focus on security and privacy has now come to the fore. Here, the research effort is in its relative infancy and progress calls for greater, multidisciplinary collaboration with security, privacy, legal and ethical experts among others. Such collaboration is now underway. To help catalyse the efforts, this paper provides a high-level overview of some related research. It targets the non-speech audience and describes the benchmarking methodology that has spearheaded progress in traditional research and which now drives recent security and privacy initiatives related to voice biometrics. We describe: the ASVspoof challenge relating to the development of spoofing countermeasures; the VoicePrivacy initiative which promotes research in anonymisation for privacy preservation.
Machine Learning for Stuttering Identification: Review, Challenges & Future Directions
Jul 12, 2021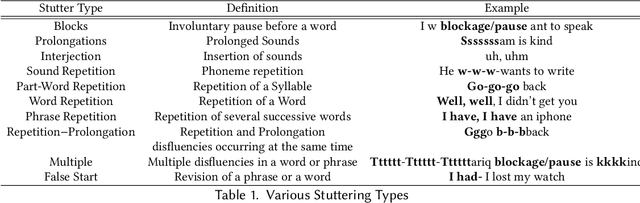
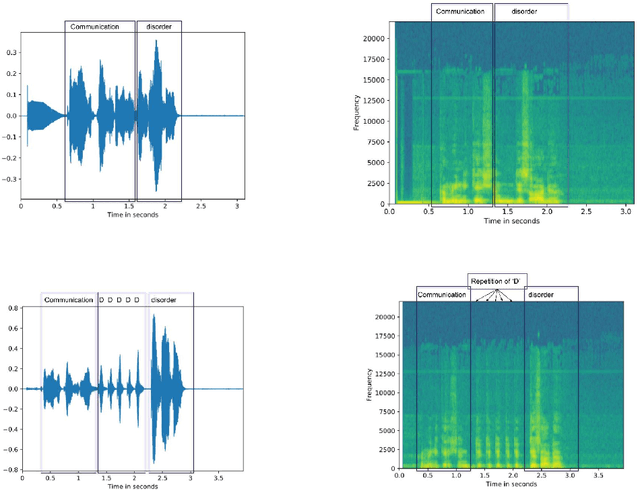
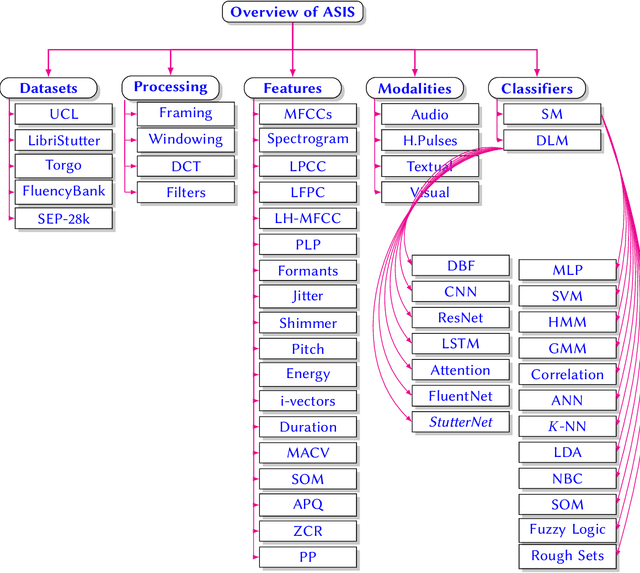
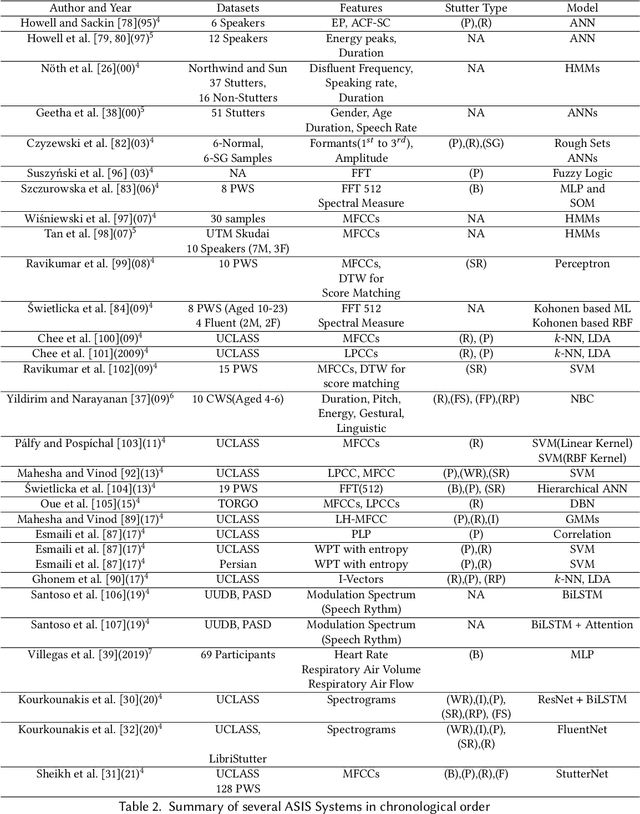
Stuttering is a speech disorder during which the flow of speech is interrupted by involuntary pauses and repetition of sounds. Stuttering identification is an interesting interdisciplinary domain research problem which involves pathology, psychology, acoustics, and signal processing that makes it hard and complicated to detect. Recent developments in machine and deep learning have dramatically revolutionized speech domain, however minimal attention has been given to stuttering identification. This work fills the gap by trying to bring researchers together from interdisciplinary fields. In this paper, we review comprehensively acoustic features, statistical and deep learning based stuttering/disfluency classification methods. We also present several challenges and possible future directions.