 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Apprenticeship Learning from Imperfect Demonstrations with Evolving Rewards
Mar 31, 2026While apprenticeship learning has shown promise for inducing effective pedagogical policies directly from student interactions in e-learning environments, most existing approaches rely on optimal or near-optimal expert demonstrations under a fixed reward. Real-world student interactions, however, are often inherently imperfect and evolving: students explore, make errors, revise strategies, and refine their goals as understanding develops. In this work, we argue that imperfect student demonstrations are not noise to be discarded, but structured signals-provided their relative quality is ranked. We introduce HALIDE, Hierarchical Apprenticeship Learning from Imperfect Demonstrations with Evolving Rewards, which not only leverages sub-optimal student demonstrations, but ranks them within a hierarchical learning framework. HALIDE models student behavior at multiple levels of abstraction, enabling inference of higher-level intent and strategy from suboptimal actions while explicitly capturing the temporal evolution of student reward functions. By integrating demonstration quality into hierarchical reward inference,HALIDE distinguishes transient errors from suboptimal strategies and meaningful progress toward higher-level learning goals. Our results show that HALIDE more accurately predicts student pedagogical decisions than approaches that rely on optimal trajectories, fixed rewards, or unranked imperfect demonstrations.
Revealing the Self: Brainwave-Based Human Trait Identification
Dec 26, 2024

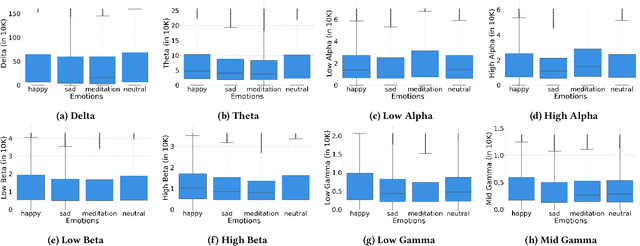

People exhibit unique emotional responses. In the same scenario, the emotional reactions of two individuals can be either similar or vastly different. For instance, consider one person's reaction to an invitation to smoke versus another person's response to a query about their sleep quality. The identification of these individual traits through the observation of common physical parameters opens the door to a wide range of applications, including psychological analysis, criminology, disease prediction, addiction control, and more. While there has been previous research in the fields of psychometrics, inertial sensors, computer vision, and audio analysis, this paper introduces a novel technique for identifying human traits in real time using brainwave data. To achieve this, we begin with an extensive study of brainwave data collected from 80 participants using a portable EEG headset. We also conduct a statistical analysis of the collected data utilizing box plots. Our analysis uncovers several new insights, leading us to a groundbreaking unified approach for identifying diverse human traits by leveraging machine learning techniques on EEG data. Our analysis demonstrates that this proposed solution achieves high accuracy. Moreover, we explore two deep-learning models to compare the performance of our solution. Consequently, we have developed an integrated, real-time trait identification solution using EEG data, based on the insights from our analysis. To validate our approach, we conducted a rigorous user evaluation with an additional 20 participants. The outcomes of this evaluation illustrate both high accuracy and favorable user ratings, emphasizing the robust potential of our proposed method to serve as a versatile solution for human trait identification.
A Generalized Apprenticeship Learning Framework for Modeling Heterogeneous Student Pedagogical Strategies
Jun 04, 2024



A key challenge in e-learning environments like Intelligent Tutoring Systems (ITSs) is to induce effective pedagogical policies efficiently. While Deep Reinforcement Learning (DRL) often suffers from sample inefficiency and reward function design difficulty, Apprenticeship Learning(AL) algorithms can overcome them. However, most AL algorithms can not handle heterogeneity as they assume all demonstrations are generated with a homogeneous policy driven by a single reward function. Still, some AL algorithms which consider heterogeneity, often can not generalize to large continuous state space and only work with discrete states. In this paper, we propose an expectation-maximization(EM)-EDM, a general AL framework to induce effective pedagogical policies from given optimal or near-optimal demonstrations, which are assumed to be driven by heterogeneous reward functions. We compare the effectiveness of the policies induced by our proposed EM-EDM against four AL-based baselines and two policies induced by DRL on two different but related tasks that involve pedagogical action prediction. Our overall results showed that, for both tasks, EM-EDM outperforms the four AL baselines across all performance metrics and the two DRL baselines. This suggests that EM-EDM can effectively model complex student pedagogical decision-making processes through the ability to manage a large, continuous state space and adapt to handle diverse and heterogeneous reward functions with very few given demonstrations.