 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Cross-Lingual Classification Approaches Enabling Topic Discovery for Multilingual Social Media Data
Feb 19, 2026Analysing multilingual social media discourse remains a major challenge in natural language processing, particularly when large-scale public debates span across diverse languages. This study investigates how different approaches for cross-lingual text classification can support reliable analysis of global conversations. Using hydrogen energy as a case study, we analyse a decade-long dataset of over nine million tweets in English, Japanese, Hindi, and Korean (2013--2022) for topic discovery. The online keyword-driven data collection results in a significant amount of irrelevant content. We explore four approaches to filter relevant content: (1) translating English annotated data into target languages for building language-specific models for each target language, (2) translating unlabelled data appearing from all languages into English for creating a single model based on English annotations, (3) applying English fine-tuned multilingual transformers directly to each target language data, and (4) a hybrid strategy that combines translated annotations with multilingual training. Each approach is evaluated for its ability to filter hydrogen-related tweets from noisy keyword-based collections. Subsequently, topic modeling is performed to extract dominant themes within the relevant subsets. The results highlight key trade-offs between translation and multilingual approaches, offering actionable insights into optimising cross-lingual pipelines for large-scale social media analysis.
IRLCov19: A Large COVID-19 Multilingual Twitter Dataset of Indian Regional Languages
Jul 26, 2021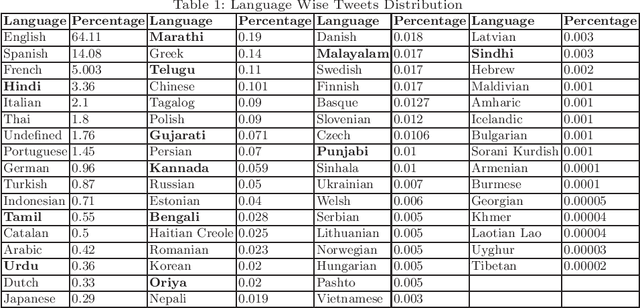
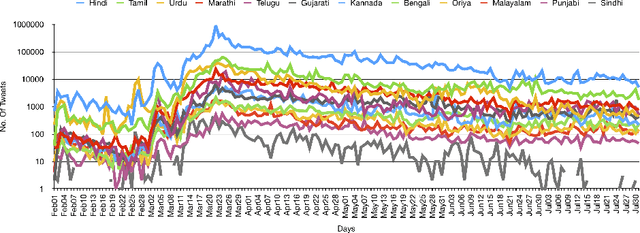

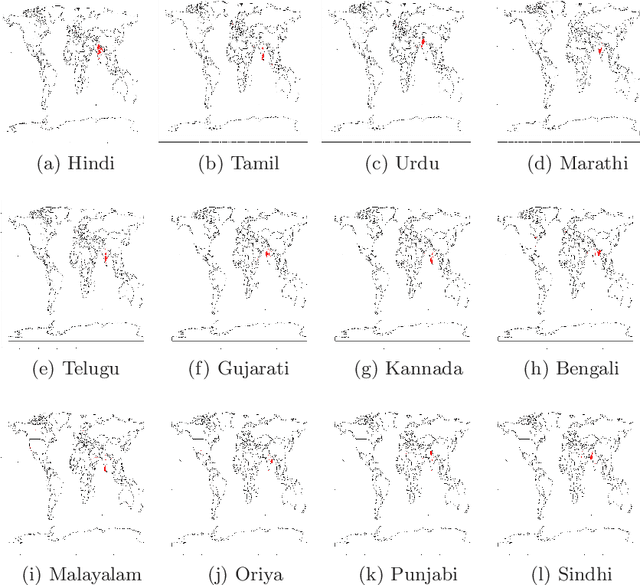
Emerged in Wuhan city of China in December 2019, COVID-19 continues to spread rapidly across the world despite authorities having made available a number of vaccines. While the coronavirus has been around for a significant period of time, people and authorities still feel the need for awareness due to the mutating nature of the virus and therefore varying symptoms and prevention strategies. People and authorities resort to social media platforms the most to share awareness information and voice out their opinions due to their massive outreach in spreading the word in practically no time. People use a number of languages to communicate over social media platforms based on their familiarity, language outreach, and availability on social media platforms. The entire world has been hit by the coronavirus and India is the second worst-hit country in terms of the number of active coronavirus cases. India, being a multilingual country, offers a great opportunity to study the outreach of various languages that have been actively used across social media platforms. In this study, we aim to study the dataset related to COVID-19 collected in the period between February 2020 to July 2020 specifically for regional languages in India. This could be helpful for the Government of India, various state governments, NGOs, researchers, and policymakers in studying different issues related to the pandemic. We found that English has been the mode of communication in over 64% of tweets while as many as twelve regional languages in India account for approximately 4.77% of tweets.