 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Dropout
Dec 10, 2018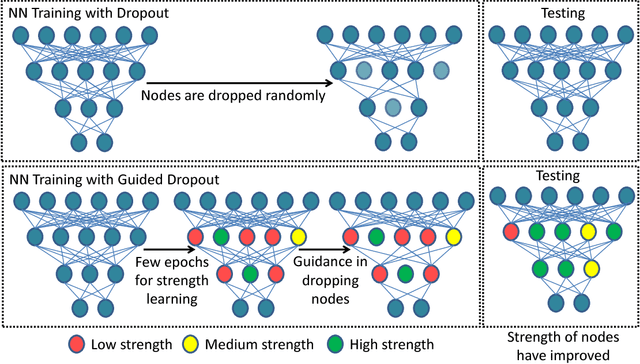
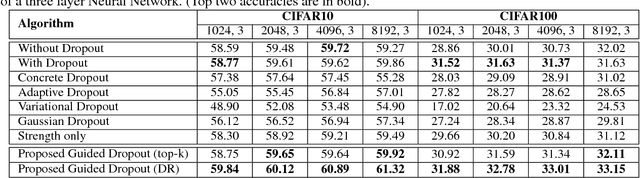
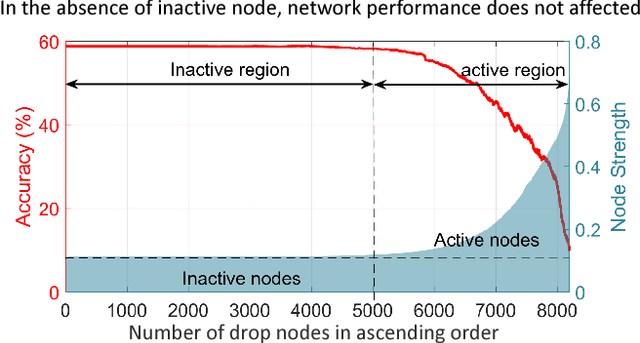
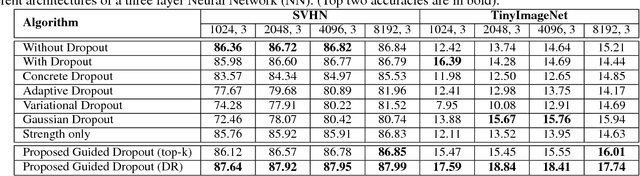
Dropout is often used in deep neural networks to prevent over-fitting. Conventionally, dropout training invokes \textit{random drop} of nodes from the hidden layers of a Neural Network. It is our hypothesis that a guided selection of nodes for intelligent dropout can lead to better generalization as compared to the traditional dropout. In this research, we propose "guided dropout" for training deep neural network which drop nodes by measuring the strength of each node. We also demonstrate that conventional dropout is a specific case of the proposed guided dropout. Experimental evaluation on multiple datasets including MNIST, CIFAR10, CIFAR100, SVHN, and Tiny ImageNet demonstrate the efficacy of the proposed guided dropout.
Data Fine-tuning
Dec 10, 2018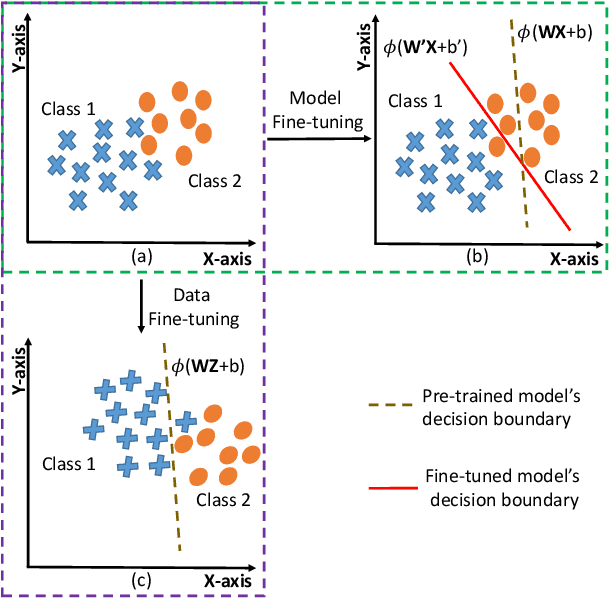
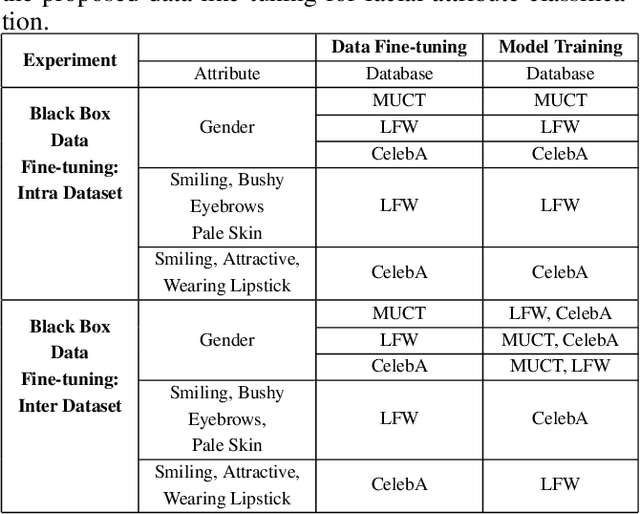
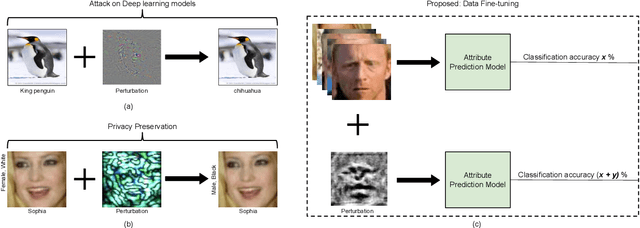
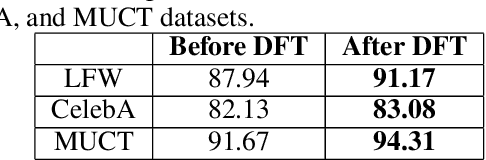
In real-world applications, commercial off-the-shelf systems are utilized for performing automated facial analysis including face recognition, emotion recognition, and attribute prediction. However, a majority of these commercial systems act as black boxes due to the inaccessibility of the model parameters which makes it challenging to fine-tune the models for specific applications. Stimulated by the advances in adversarial perturbations, this research proposes the concept of Data Fine-tuning to improve the classification accuracy of a given model without changing the parameters of the model. This is accomplished by modeling it as data (image) perturbation problem. A small amount of "noise" is added to the input with the objective of minimizing the classification loss without affecting the (visual) appearance. Experiments performed on three publicly available datasets LFW, CelebA, and MUCT, demonstrate the effectiveness of the proposed concept.
Recognizing Disguised Faces in the Wild
Nov 21, 2018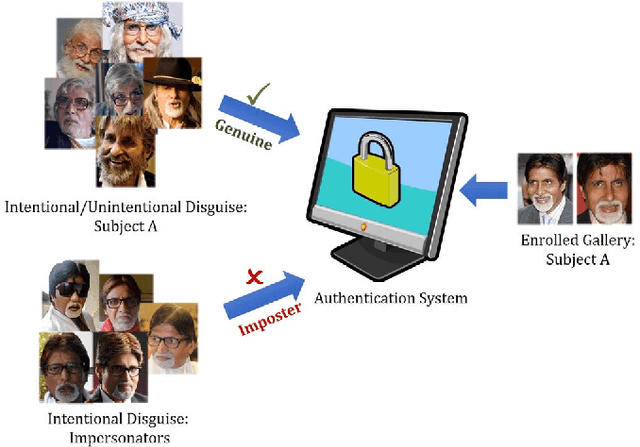

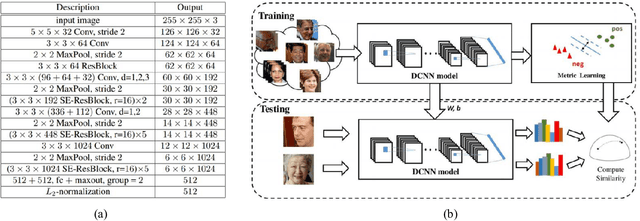
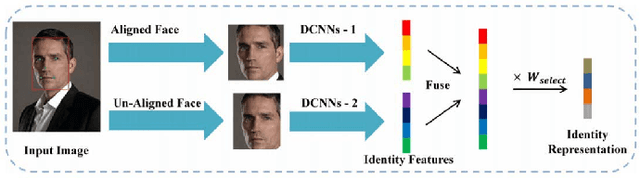
Research in face recognition has seen tremendous growth over the past couple of decades. Beginning from algorithms capable of performing recognition in constrained environments, the current face recognition systems achieve very high accuracies on large-scale unconstrained face datasets. While upcoming algorithms continue to achieve improved performance, a majority of the face recognition systems are susceptible to failure under disguise variations, one of the most challenging covariate of face recognition. Most of the existing disguise datasets contain images with limited variations, often captured in controlled settings. This does not simulate a real world scenario, where both intentional and unintentional unconstrained disguises are encountered by a face recognition system. In this paper, a novel Disguised Faces in the Wild (DFW) dataset is proposed which contains over 11000 images of 1000 identities with different types of disguise accessories. The dataset is collected from the Internet, resulting in unconstrained face images similar to real world settings. This is the first-of-a-kind dataset with the availability of impersonator and genuine obfuscated face images for each subject. The proposed dataset has been analyzed in terms of three levels of difficulty: (i) easy, (ii) medium, and (iii) hard in order to showcase the challenging nature of the problem. It is our view that the research community can greatly benefit from the DFW dataset in terms of developing algorithms robust to such adversaries. The proposed dataset was released as part of the First International Workshop and Competition on Disguised Faces in the Wild at CVPR, 2018. This paper presents the DFW dataset in detail, including the evaluation protocols, baseline results, performance analysis of the submissions received as part of the competition, and three levels of difficulties of the DFW challenge dataset.
On Matching Faces with Alterations due to Plastic Surgery and Disguise
Nov 18, 2018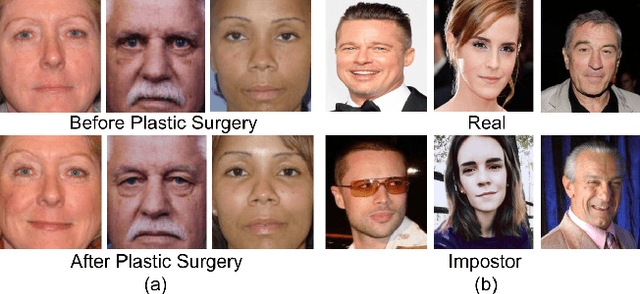
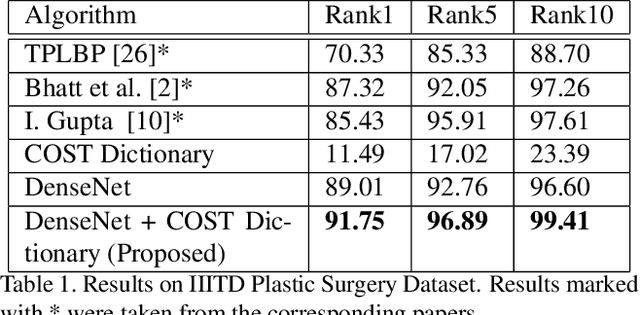
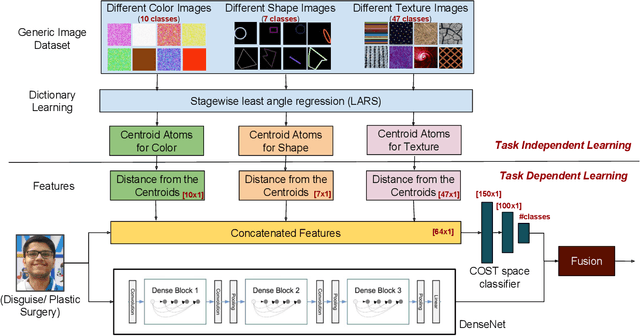

Plastic surgery and disguise variations are two of the most challenging co-variates of face recognition. The state-of-art deep learning models are not sufficiently successful due to the availability of limited training samples. In this paper, a novel framework is proposed which transfers fundamental visual features learnt from a generic image dataset to supplement a supervised face recognition model. The proposed algorithm combines off-the-shelf supervised classifier and a generic, task independent network which encodes information related to basic visual cues such as color, shape, and texture. Experiments are performed on IIITD plastic surgery face dataset and Disguised Faces in the Wild (DFW) dataset. Results showcase that the proposed algorithm achieves state of the art results on both the datasets. Specifically on the DFW database, the proposed algorithm yields over 87% verification accuracy at 1% false accept rate which is 53.8% better than baseline results computed using VGGFace.
Heterogeneity Aware Deep Embedding for Mobile Periocular Recognition
Nov 02, 2018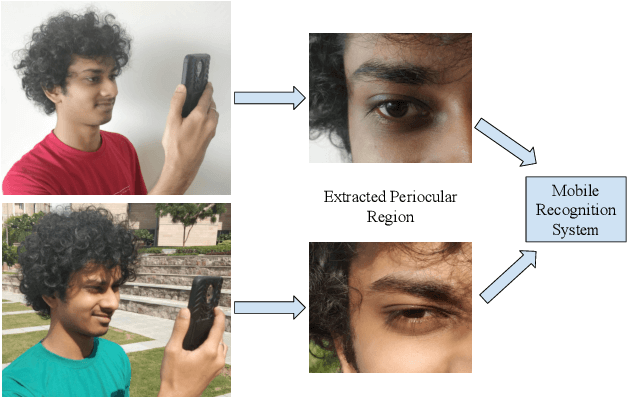
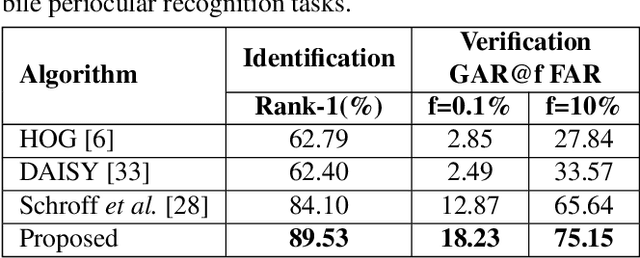
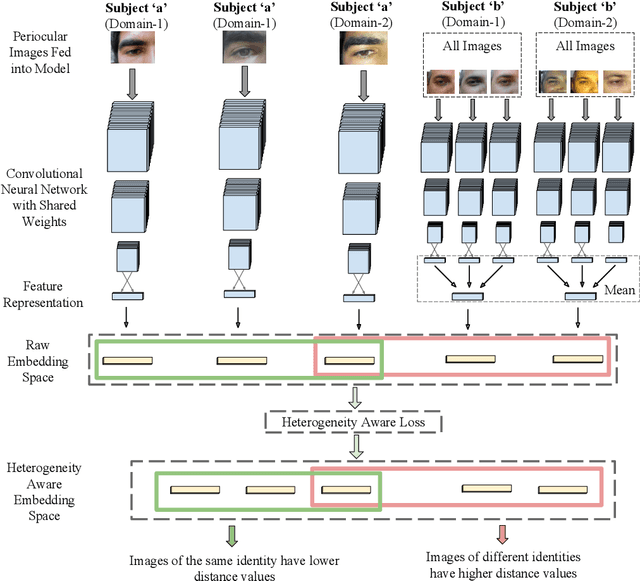
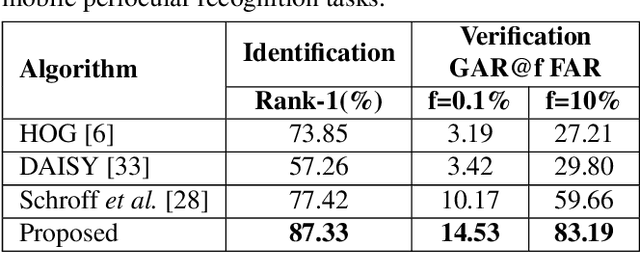
Mobile biometric approaches provide the convenience of secure authentication with an omnipresent technology. However, this brings an additional challenge of recognizing biometric patterns in unconstrained environment including variations in mobile camera sensors, illumination conditions, and capture distance. To address the heterogeneous challenge, this research presents a novel heterogeneity aware loss function within a deep learning framework. The effectiveness of the proposed loss function is evaluated for periocular biometrics using the CSIP, IMP and VISOB mobile periocular databases. The results show that the proposed algorithm yields state-of-the-art results in a heterogeneous environment and improves generalizability for cross-database experiments.
Supervised COSMOS Autoencoder: Learning Beyond the Euclidean Loss!
Oct 15, 2018

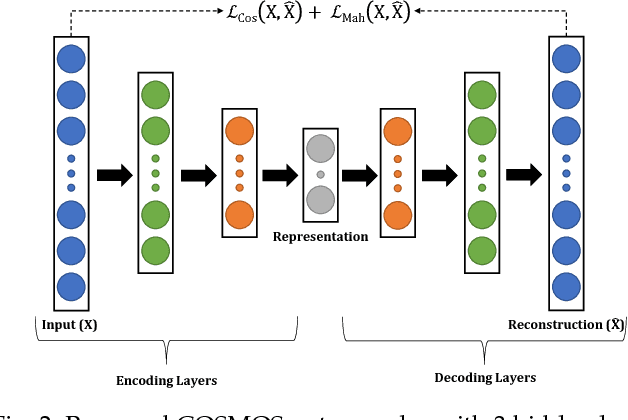
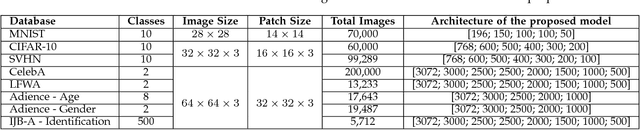
Autoencoders are unsupervised deep learning models used for learning representations. In literature, autoencoders have shown to perform well on a variety of tasks spread across multiple domains, thereby establishing widespread applicability. Typically, an autoencoder is trained to generate a model that minimizes the reconstruction error between the input and the reconstructed output, computed in terms of the Euclidean distance. While this can be useful for applications related to unsupervised reconstruction, it may not be optimal for classification. In this paper, we propose a novel Supervised COSMOS Autoencoder which utilizes a multi-objective loss function to learn representations that simultaneously encode the (i) "similarity" between the input and reconstructed vectors in terms of their direction, (ii) "distribution" of pixel values of the reconstruction with respect to the input sample, while also incorporating (iii) "discriminability" in the feature learning pipeline. The proposed autoencoder model incorporates a Cosine similarity and Mahalanobis distance based loss function, along with supervision via Mutual Information based loss. Detailed analysis of each component of the proposed model motivates its applicability for feature learning in different classification tasks. The efficacy of Supervised COSMOS autoencoder is demonstrated via extensive experimental evaluations on different image datasets. The proposed model outperforms existing algorithms on MNIST, CIFAR-10, and SVHN databases. It also yields state-of-the-art results on CelebA, LFWA, Adience, and IJB-A databases for attribute prediction and face recognition, respectively.
Anonymizing k-Facial Attributes via Adversarial Perturbations
Sep 28, 2018


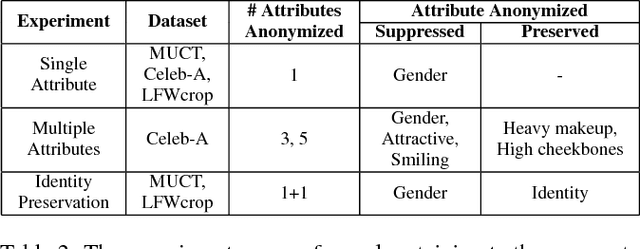
A face image not only provides details about the identity of a subject but also reveals several attributes such as gender, race, sexual orientation, and age. Advancements in machine learning algorithms and popularity of sharing images on the World Wide Web, including social media websites, have increased the scope of data analytics and information profiling from photo collections. This poses a serious privacy threat for individuals who do not want to be profiled. This research presents a novel algorithm for anonymizing selective attributes which an individual does not want to share without affecting the visual quality of images. Using the proposed algorithm, a user can select single or multiple attributes to be surpassed while preserving identity information and visual content. The proposed adversarial perturbation based algorithm embeds imperceptible noise in an image such that attribute prediction algorithm for the selected attribute yields incorrect classification result, thereby preserving the information according to user's choice. Experiments on three popular databases i.e. MUCT, LFWcrop, and CelebA show that the proposed algorithm not only anonymizes k-attributes, but also preserves image quality and identity information.
Learning A Shared Transform Model for Skull to Digital Face Image Matching
Aug 14, 2018
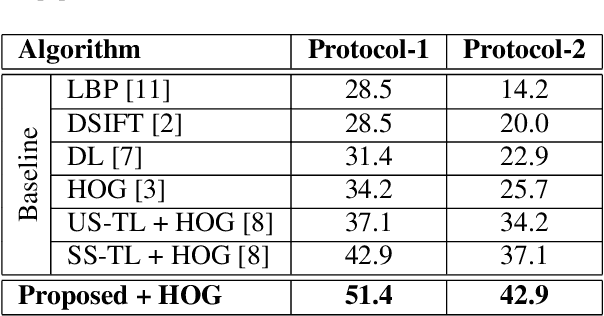
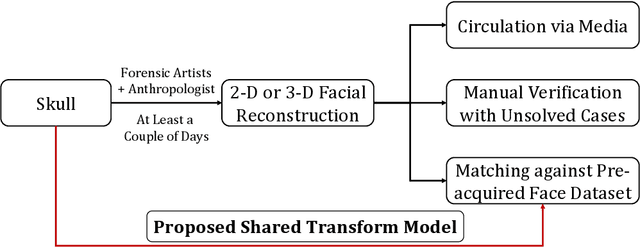
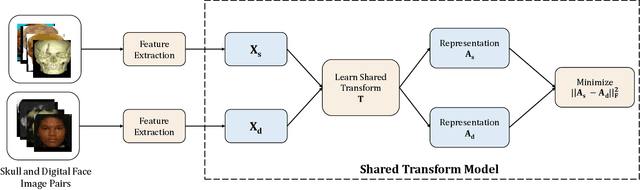
Human skull identification is an arduous task, traditionally requiring the expertise of forensic artists and anthropologists. This paper is an effort to automate the process of matching skull images to digital face images, thereby establishing an identity of the skeletal remains. In order to achieve this, a novel Shared Transform Model is proposed for learning discriminative representations. The model learns robust features while reducing the intra-class variations between skulls and digital face images. Such a model can assist law enforcement agencies by speeding up the process of skull identification, and reducing the manual load. Experimental evaluation performed on two pre-defined protocols of the publicly available IdentifyMe dataset demonstrates the efficacy of the proposed model.
Supervised Mixed Norm Autoencoder for Kinship Verification in Unconstrained Videos
May 30, 2018
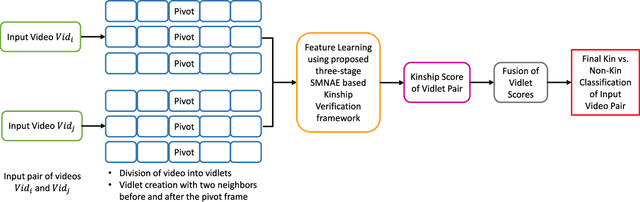
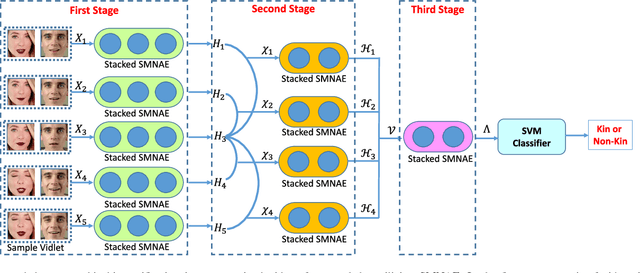

Identifying kinship relations has garnered interest due to several applications such as organizing and tagging the enormous amount of videos being uploaded on the Internet. Existing research in kinship verification primarily focuses on kinship prediction with image pairs. In this research, we propose a new deep learning framework for kinship verification in unconstrained videos using a novel Supervised Mixed Norm regularization Autoencoder (SMNAE). This new autoencoder formulation introduces class-specific sparsity in the weight matrix. The proposed three-stage SMNAE based kinship verification framework utilizes the learned spatio-temporal representation in the video frames for verifying kinship in a pair of videos. A new kinship video (KIVI) database of more than 500 individuals with variations due to illumination, pose, occlusion, ethnicity, and expression is collected for this research. It comprises a total of 355 true kin video pairs with over 250,000 still frames. The effectiveness of the proposed framework is demonstrated on the KIVI database and six existing kinship databases. On the KIVI database, SMNAE yields video-based kinship verification accuracy of 83.18% which is at least 3.2% better than existing algorithms. The algorithm is also evaluated on six publicly available kinship databases and compared with best-reported results. It is observed that the proposed SMNAE consistently yields best results on all the databases
Hierarchical Representation Learning for Kinship Verification
May 27, 2018
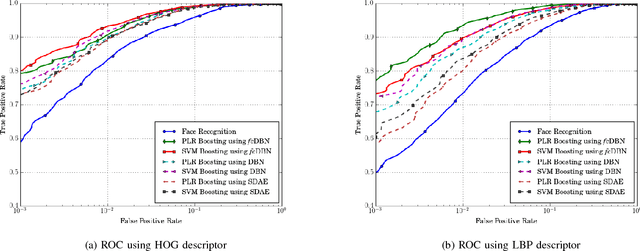

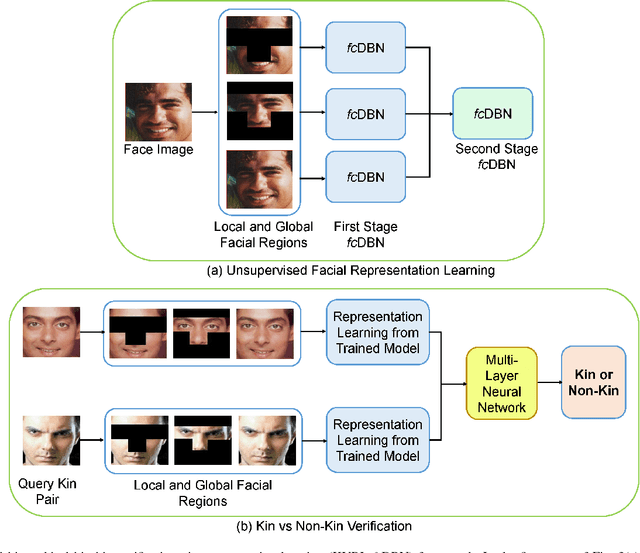
Kinship verification has a number of applications such as organizing large collections of images and recognizing resemblances among humans. In this research, first, a human study is conducted to understand the capabilities of human mind and to identify the discriminatory areas of a face that facilitate kinship-cues. Utilizing the information obtained from the human study, a hierarchical Kinship Verification via Representation Learning (KVRL) framework is utilized to learn the representation of different face regions in an unsupervised manner. We propose a novel approach for feature representation termed as filtered contractive deep belief networks (fcDBN). The proposed feature representation encodes relational information present in images using filters and contractive regularization penalty. A compact representation of facial images of kin is extracted as an output from the learned model and a multi-layer neural network is utilized to verify the kin accurately. A new WVU Kinship Database is created which consists of multiple images per subject to facilitate kinship verification. The results show that the proposed deep learning framework (KVRL-fcDBN) yields stateof-the-art kinship verification accuracy on the WVU Kinship database and on four existing benchmark datasets. Further, kinship information is used as a soft biometric modality to boost the performance of face verification via product of likelihood ratio and support vector machine based approaches. Using the proposed KVRL-fcDBN framework, an improvement of over 20% is observed in the performance of face verification.