 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending a Parliamentary Corpus with MPs' Tweets: Automatic Annotation and Evaluation Using MultiParTweet
Dec 12, 2025Social media serves as a critical medium in modern politics because it both reflects politicians' ideologies and facilitates communication with younger generations. We present MultiParTweet, a multilingual tweet corpus from X that connects politicians' social media discourse with German political corpus GerParCor, thereby enabling comparative analyses between online communication and parliamentary debates. MultiParTweet contains 39 546 tweets, including 19 056 media items. Furthermore, we enriched the annotation with nine text-based models and one vision-language model (VLM) to annotate MultiParTweet with emotion, sentiment, and topic annotations. Moreover, the automated annotations are evaluated against a manually annotated subset. MultiParTweet can be reconstructed using our tool, TTLABTweetCrawler, which provides a framework for collecting data from X. To demonstrate a methodological demonstration, we examine whether the models can predict each other using the outputs of the remaining models. In summary, we provide MultiParTweet, a resource integrating automatic text and media-based annotations validated with human annotations, and TTLABTweetCrawler, a general-purpose X data collection tool. Our analysis shows that the models are mutually predictable. In addition, VLM-based annotation were preferred by human annotators, suggesting that multimodal representations align more with human interpretation.
You Shall Know a Tool by the Traces it Leaves: The Predictability of Sentiment Analysis Tools
Oct 18, 2024



If sentiment analysis tools were valid classifiers, one would expect them to provide comparable results for sentiment classification on different kinds of corpora and for different languages. In line with results of previous studies we show that sentiment analysis tools disagree on the same dataset. Going beyond previous studies we show that the sentiment tool used for sentiment annotation can even be predicted from its outcome, revealing an algorithmic bias of sentiment analysis. Based on Twitter, Wikipedia and different news corpora from the English, German and French languages, our classifiers separate sentiment tools with an averaged F1-score of 0.89 (for the English corpora). We therefore warn against taking sentiment annotations as face value and argue for the need of more and systematic NLP evaluation studies.
Multiple Texts as a Limiting Factor in Online Learning: Quantifying similarities of Knowledge Networks across Languages
Aug 05, 2020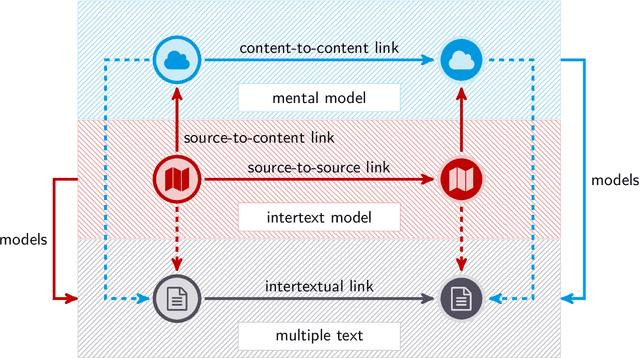

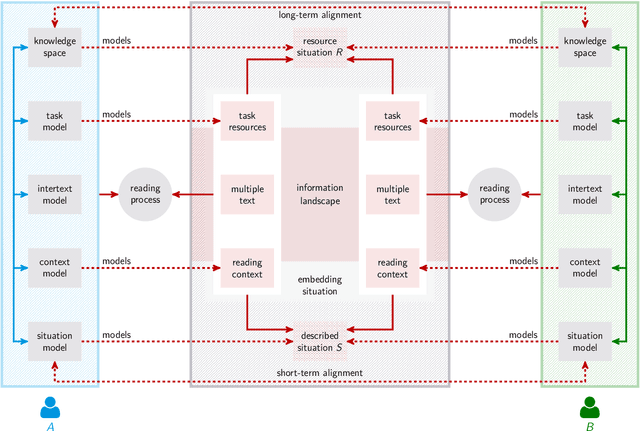
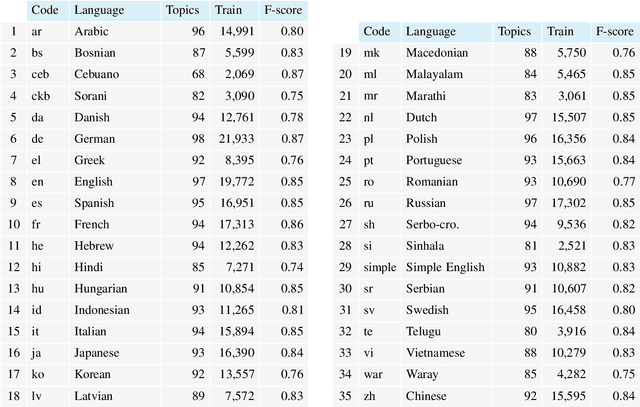
We test the hypothesis that the extent to which one obtains information on a given topic through Wikipedia depends on the language in which it is consulted. Controlling the size factor, we investigate this hypothesis for a number of 25 subject areas. Since Wikipedia is a central part of the web-based information landscape, this indicates a language-related, linguistic bias. The article therefore deals with the question of whether Wikipedia exhibits this kind of linguistic relativity or not. From the perspective of educational science, the article develops a computational model of the information landscape from which multiple texts are drawn as typical input of web-based reading. For this purpose, it develops a hybrid model of intra- and intertextual similarity of different parts of the information landscape and tests this model on the example of 35 languages and corresponding Wikipedias. In this way the article builds a bridge between reading research, educational science, Wikipedia research and computational linguistics.