 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending a Parliamentary Corpus with MPs' Tweets: Automatic Annotation and Evaluation Using MultiParTweet
Dec 12, 2025Social media serves as a critical medium in modern politics because it both reflects politicians' ideologies and facilitates communication with younger generations. We present MultiParTweet, a multilingual tweet corpus from X that connects politicians' social media discourse with German political corpus GerParCor, thereby enabling comparative analyses between online communication and parliamentary debates. MultiParTweet contains 39 546 tweets, including 19 056 media items. Furthermore, we enriched the annotation with nine text-based models and one vision-language model (VLM) to annotate MultiParTweet with emotion, sentiment, and topic annotations. Moreover, the automated annotations are evaluated against a manually annotated subset. MultiParTweet can be reconstructed using our tool, TTLABTweetCrawler, which provides a framework for collecting data from X. To demonstrate a methodological demonstration, we examine whether the models can predict each other using the outputs of the remaining models. In summary, we provide MultiParTweet, a resource integrating automatic text and media-based annotations validated with human annotations, and TTLABTweetCrawler, a general-purpose X data collection tool. Our analysis shows that the models are mutually predictable. In addition, VLM-based annotation were preferred by human annotators, suggesting that multimodal representations align more with human interpretation.
You Shall Know a Tool by the Traces it Leaves: The Predictability of Sentiment Analysis Tools
Oct 18, 2024



If sentiment analysis tools were valid classifiers, one would expect them to provide comparable results for sentiment classification on different kinds of corpora and for different languages. In line with results of previous studies we show that sentiment analysis tools disagree on the same dataset. Going beyond previous studies we show that the sentiment tool used for sentiment annotation can even be predicted from its outcome, revealing an algorithmic bias of sentiment analysis. Based on Twitter, Wikipedia and different news corpora from the English, German and French languages, our classifiers separate sentiment tools with an averaged F1-score of 0.89 (for the English corpora). We therefore warn against taking sentiment annotations as face value and argue for the need of more and systematic NLP evaluation studies.
The Frankfurt Latin Lexicon: From Morphological Expansion and Word Embeddings to SemioGraphs
May 21, 2020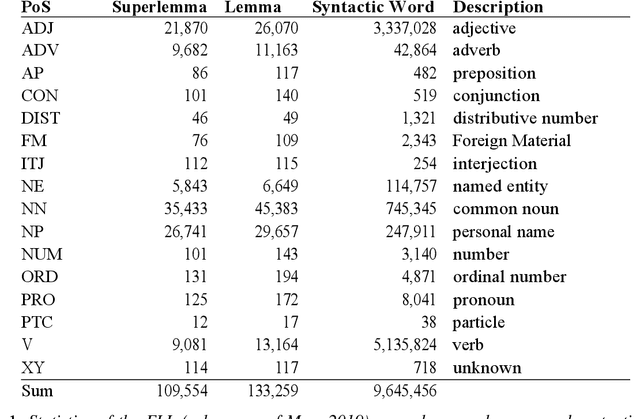
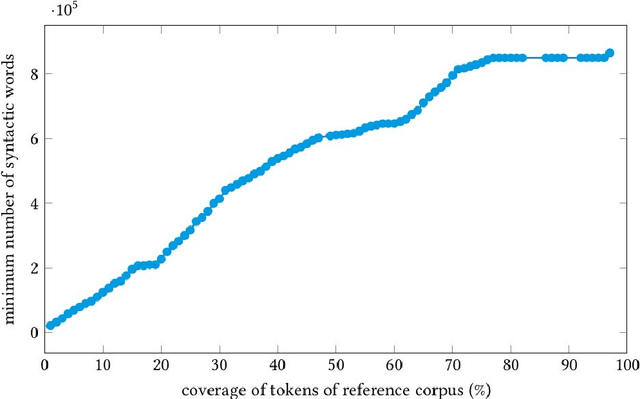
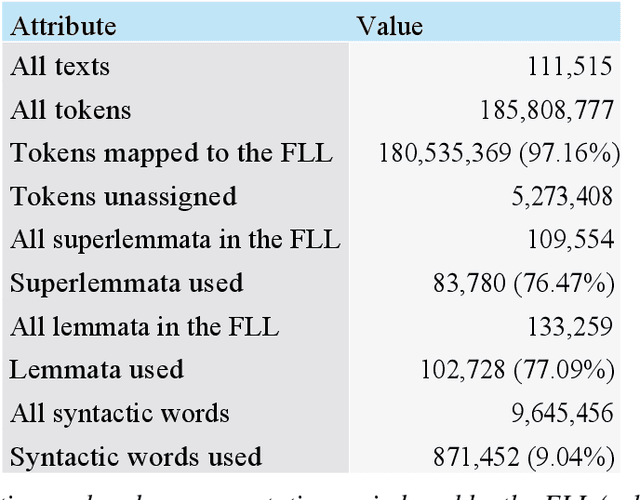
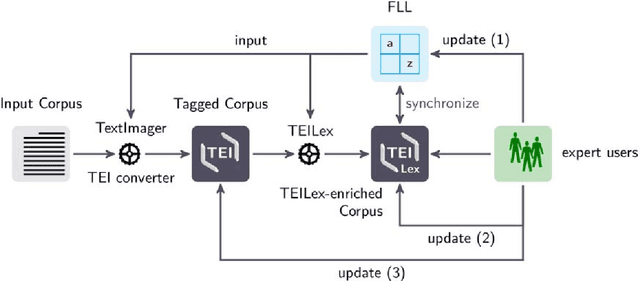
In this article we present the Frankfurt Latin Lexicon (FLL), a lexical resource for Medieval Latin that is used both for the lemmatization of Latin texts and for the post-editing of lemmatizations. We describe recent advances in the development of lemmatizers and test them against the Capitularies corpus (comprising Frankish royal edicts, mid-6th to mid-9th century), a corpus created as a reference for processing Medieval Latin. We also consider the post-correction of lemmatizations using a limited crowdsourcing process aimed at continuous review and updating of the FLL. Starting from the texts resulting from this lemmatization process, we describe the extension of the FLL by means of word embeddings, whose interactive traversing by means of SemioGraphs completes the digital enhanced hermeneutic circle. In this way, the article argues for a more comprehensive understanding of lemmatization, encompassing classical machine learning as well as intellectual post-corrections and, in particular, human computation in the form of interpretation processes based on graph representations of the underlying lexical resources.