 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Weight-Sharing for Neural Network Compression
May 09, 2017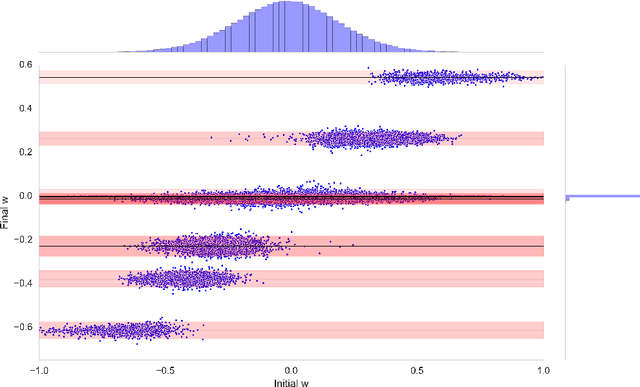
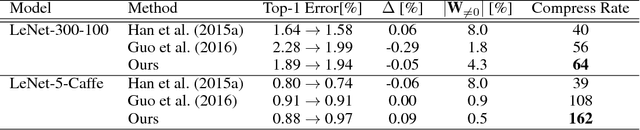
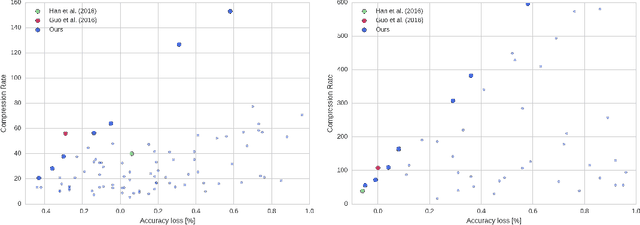
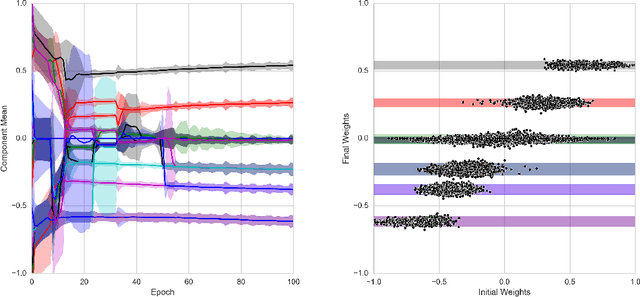
The success of deep learning in numerous application domains created the de- sire to run and train them on mobile devices. This however, conflicts with their computationally, memory and energy intense nature, leading to a growing interest in compression. Recent work by Han et al. (2015a) propose a pipeline that involves retraining, pruning and quantization of neural network weights, obtaining state-of-the-art compression rates. In this paper, we show that competitive compression rates can be achieved by using a version of soft weight-sharing (Nowlan & Hinton, 1992). Our method achieves both quantization and pruning in one simple (re-)training procedure. This point of view also exposes the relation between compression and the minimum description length (MDL) principle.
Semi-Supervised Classification with Graph Convolutional Networks
Feb 22, 2017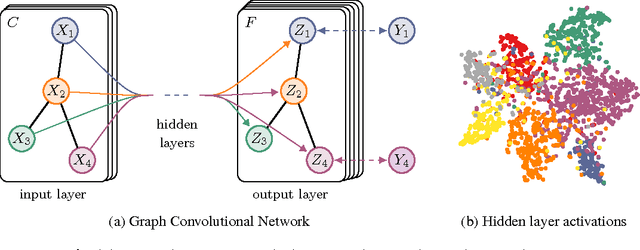
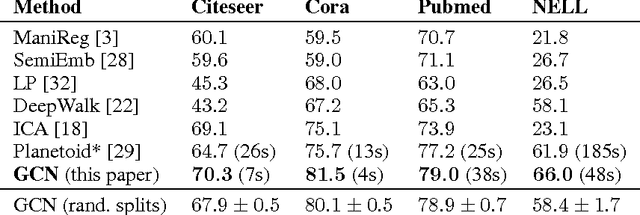
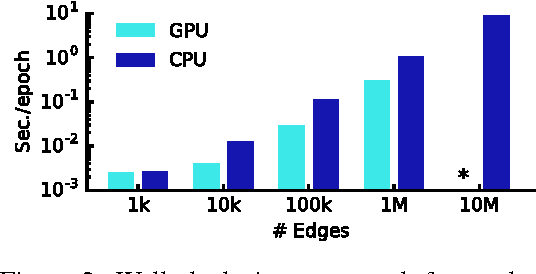

We present a scalable approach for semi-supervised learning on graph-structured data that is based on an efficient variant of convolutional neural networks which operate directly on graphs. We motivate the choice of our convolutional architecture via a localized first-order approximation of spectral graph convolutions. Our model scales linearly in the number of graph edges and learns hidden layer representations that encode both local graph structure and features of nodes. In a number of experiments on citation networks and on a knowledge graph dataset we demonstrate that our approach outperforms related methods by a significant margin.
Visualizing Deep Neural Network Decisions: Prediction Difference Analysis
Feb 15, 2017
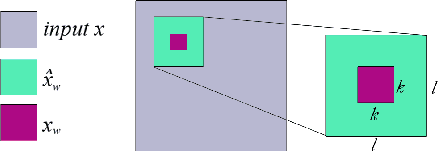


This article presents the prediction difference analysis method for visualizing the response of a deep neural network to a specific input. When classifying images, the method highlights areas in a given input image that provide evidence for or against a certain class. It overcomes several shortcoming of previous methods and provides great additional insight into the decision making process of classifiers. Making neural network decisions interpretable through visualization is important both to improve models and to accelerate the adoption of black-box classifiers in application areas such as medicine. We illustrate the method in experiments on natural images (ImageNet data), as well as medical images (MRI brain scans).
Improving Variational Inference with Inverse Autoregressive Flow
Jan 30, 2017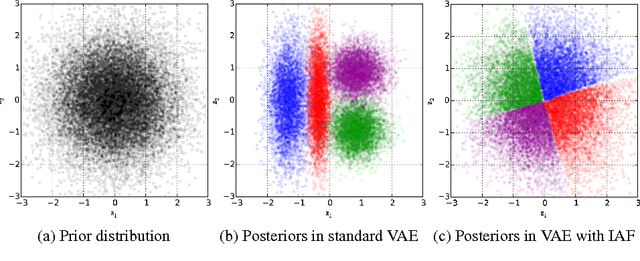
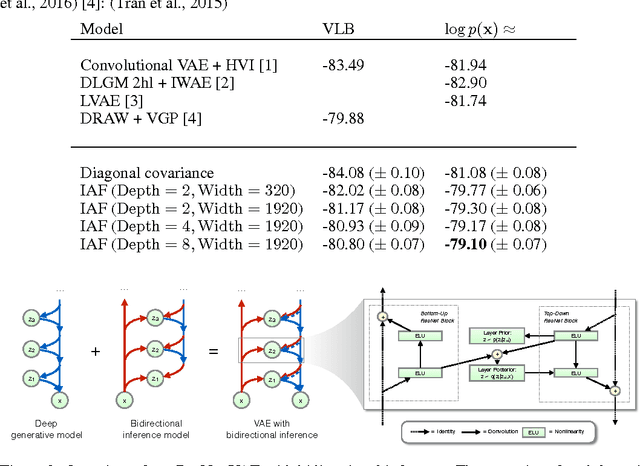
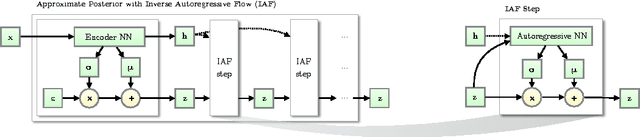
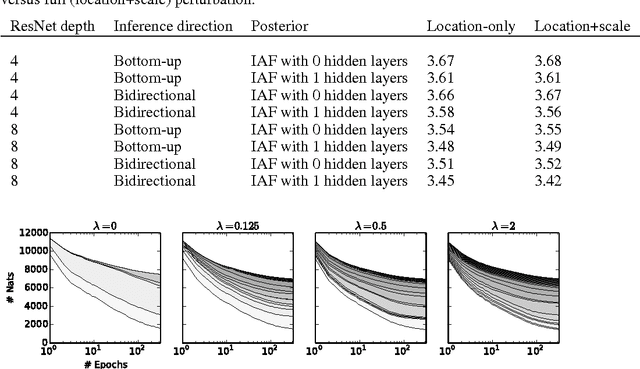
The framework of normalizing flows provides a general strategy for flexible variational inference of posteriors over latent variables. We propose a new type of normalizing flow, inverse autoregressive flow (IAF), that, in contrast to earlier published flows, scales well to high-dimensional latent spaces. The proposed flow consists of a chain of invertible transformations, where each transformation is based on an autoregressive neural network. In experiments, we show that IAF significantly improves upon diagonal Gaussian approximate posteriors. In addition, we demonstrate that a novel type of variational autoencoder, coupled with IAF, is competitive with neural autoregressive models in terms of attained log-likelihood on natural images, while allowing significantly faster synthesis.
Improving Variational Auto-Encoders using Householder Flow
Jan 27, 2017
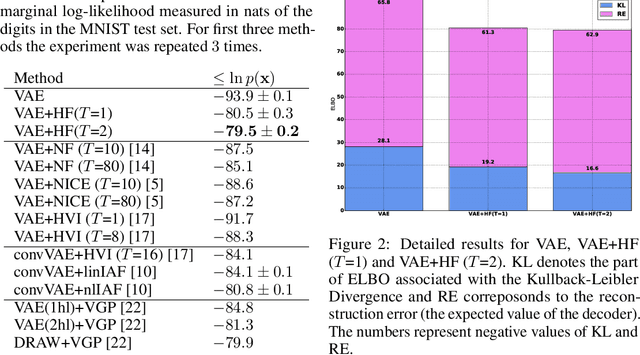
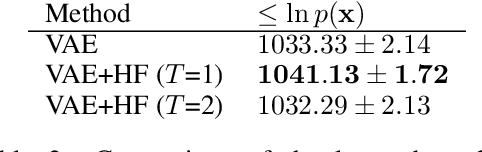

Variational auto-encoders (VAE) are scalable and powerful generative models. However, the choice of the variational posterior determines tractability and flexibility of the VAE. Commonly, latent variables are modeled using the normal distribution with a diagonal covariance matrix. This results in computational efficiency but typically it is not flexible enough to match the true posterior distribution. One fashion of enriching the variational posterior distribution is application of normalizing flows, i.e., a series of invertible transformations to latent variables with a simple posterior. In this paper, we follow this line of thinking and propose a volume-preserving flow that uses a series of Householder transformations. We show empirically on MNIST dataset and histopathology data that the proposed flow allows to obtain more flexible variational posterior and competitive results comparing to other normalizing flows.
Steerable CNNs
Dec 27, 2016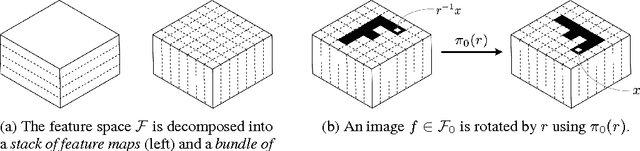
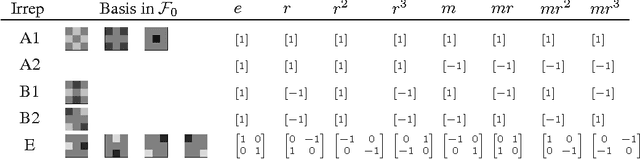
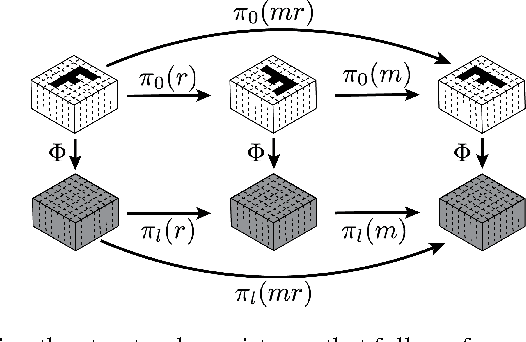
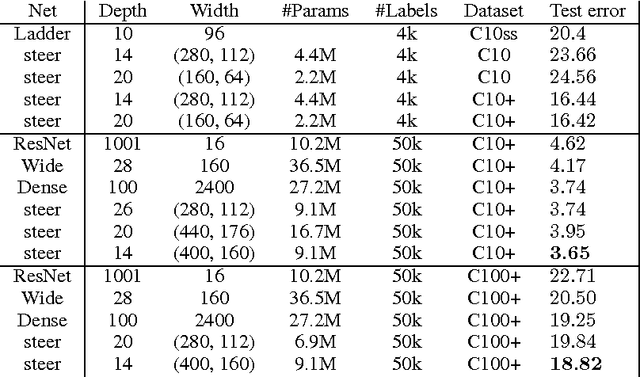
It has long been recognized that the invariance and equivariance properties of a representation are critically important for success in many vision tasks. In this paper we present Steerable Convolutional Neural Networks, an efficient and flexible class of equivariant convolutional networks. We show that steerable CNNs achieve state of the art results on the CIFAR image classification benchmark. The mathematical theory of steerable representations reveals a type system in which any steerable representation is a composition of elementary feature types, each one associated with a particular kind of symmetry. We show how the parameter cost of a steerable filter bank depends on the types of the input and output features, and show how to use this knowledge to construct CNNs that utilize parameters effectively.
Private Topic Modeling
Nov 28, 2016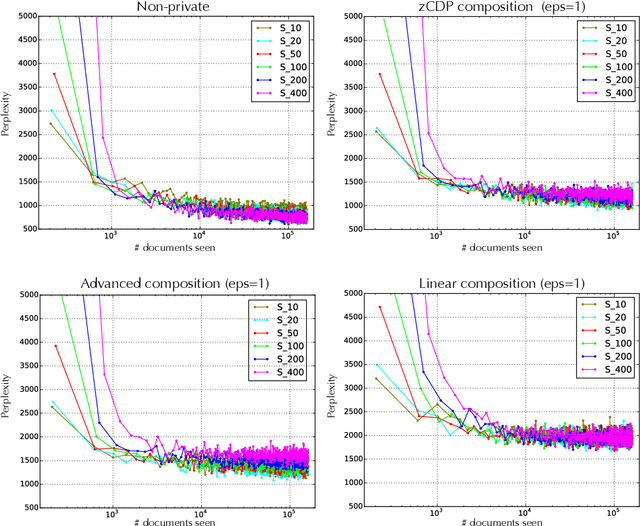
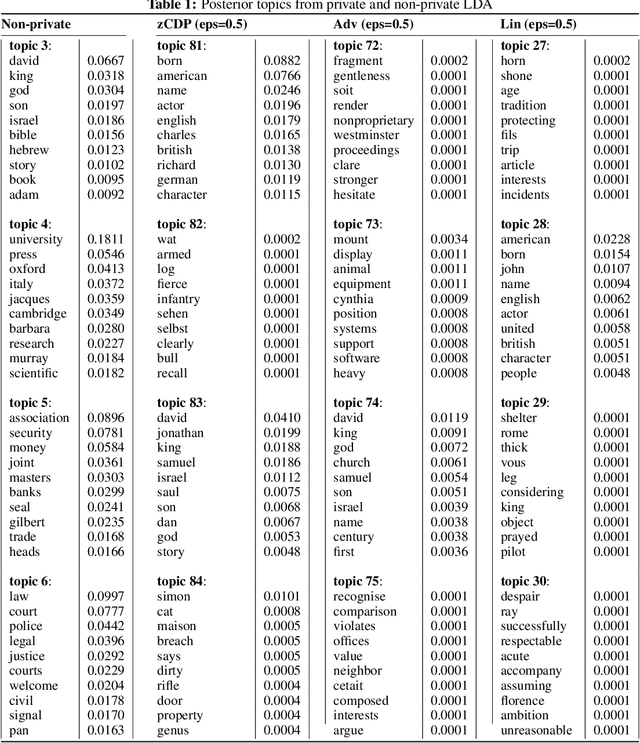
We develop a privatised stochastic variational inference method for Latent Dirichlet Allocation (LDA). The iterative nature of stochastic variational inference presents challenges: multiple iterations are required to obtain accurate posterior distributions, yet each iteration increases the amount of noise that must be added to achieve a reasonable degree of privacy. We propose a practical algorithm that overcomes this challenge by combining: (1) A relaxed notion of the differential privacy, called concentrated differential privacy, which provides high probability bounds for cumulative privacy loss, which is well suited for iterative algorithms, rather than focusing on single-query loss; and (2) Privacy amplification resulting from subsampling of large-scale data. Focusing on conjugate exponential family models, in our private variational inference, all the posterior distributions will be privatised by simply perturbing expected sufficient statistics. Using Wikipedia data, we illustrate the effectiveness of our algorithm for large-scale data.
Variational Graph Auto-Encoders
Nov 21, 2016
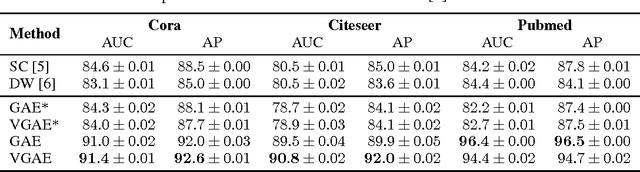
We introduce the variational graph auto-encoder (VGAE), a framework for unsupervised learning on graph-structured data based on the variational auto-encoder (VAE). This model makes use of latent variables and is capable of learning interpretable latent representations for undirected graphs. We demonstrate this model using a graph convolutional network (GCN) encoder and a simple inner product decoder. Our model achieves competitive results on a link prediction task in citation networks. In contrast to most existing models for unsupervised learning on graph-structured data and link prediction, our model can naturally incorporate node features, which significantly improves predictive performance on a number of benchmark datasets.
Sigma Delta Quantized Networks
Nov 10, 2016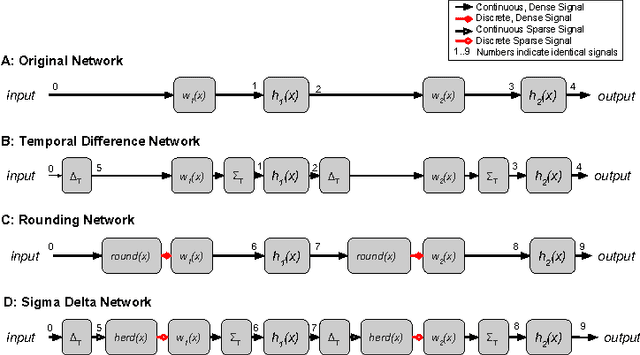
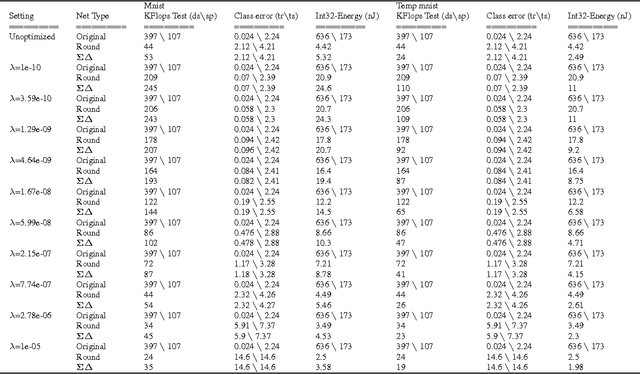
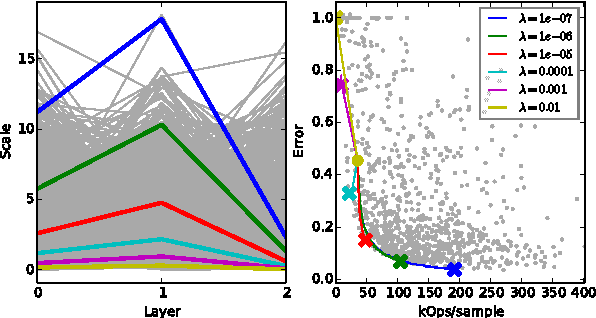

Deep neural networks can be obscenely wasteful. When processing video, a convolutional network expends a fixed amount of computation for each frame with no regard to the similarity between neighbouring frames. As a result, it ends up repeatedly doing very similar computations. To put an end to such waste, we introduce Sigma-Delta networks. With each new input, each layer in this network sends a discretized form of its change in activation to the next layer. Thus the amount of computation that the network does scales with the amount of change in the input and layer activations, rather than the size of the network. We introduce an optimization method for converting any pre-trained deep network into an optimally efficient Sigma-Delta network, and show that our algorithm, if run on the appropriate hardware, could cut at least an order of magnitude from the computational cost of processing video data.
Accelerating the BSM interpretation of LHC data with machine learning
Nov 08, 2016
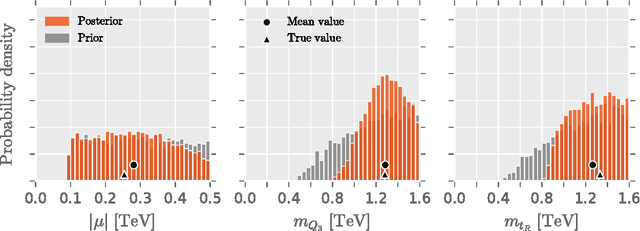
The interpretation of Large Hadron Collider (LHC) data in the framework of Beyond the Standard Model (BSM) theories is hampered by the need to run computationally expensive event generators and detector simulators. Performing statistically convergent scans of high-dimensional BSM theories is consequently challenging, and in practice unfeasible for very high-dimensional BSM theories. We present here a new machine learning method that accelerates the interpretation of LHC data, by learning the relationship between BSM theory parameters and data. As a proof-of-concept, we demonstrate that this technique accurately predicts natural SUSY signal events in two signal regions at the High Luminosity LHC, up to four orders of magnitude faster than standard techniques. The new approach makes it possible to rapidly and accurately reconstruct the theory parameters of complex BSM theories, should an excess in the data be discovered at the LHC.