 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Engineering Methods on Multivariate Time-Series Data for Financial Data Science Competitions
Apr 18, 2023



This paper is a work in progress. We are looking for collaborators to provide us financial datasets in Equity/Futures market to conduct more bench-marking studies. The authors have papers employing similar methods applied on the Numerai dataset, which is freely available but obfuscated. We apply different feature engineering methods for time-series to US market price data. The predictive power of models are tested against Numerai-Signals targets.
Interpretable statistical representations of neural population dynamics and geometry
Apr 06, 2023



The dynamics of neuron populations during diverse tasks often evolve on low-dimensional manifolds. However, it remains challenging to discern the contributions of geometry and dynamics for encoding relevant behavioural variables. Here, we introduce an unsupervised geometric deep learning framework for representing non-linear dynamical systems based on statistical distributions of local phase portrait features. Our method provides robust geometry-aware or geometry-agnostic representations for the unbiased comparison of dynamics based on measured trajectories. We demonstrate that our statistical representation can generalise across neural network instances to discriminate computational mechanisms, obtain interpretable embeddings of neural dynamics in a primate reaching task with geometric correspondence to hand kinematics, and develop a decoding algorithm with state-of-the-art accuracy. Our results highlight the importance of using the intrinsic manifold structure over temporal information to develop better decoding algorithms and assimilate data across experiments.
Robust machine learning pipelines for trading market-neutral stock portfolios
Dec 30, 2022



The application of deep learning algorithms to financial data is difficult due to heavy non-stationarities which can lead to over-fitted models that underperform under regime changes. Using the Numerai tournament data set as a motivating example, we propose a machine learning pipeline for trading market-neutral stock portfolios based on tabular data which is robust under changes in market conditions. We evaluate various machine-learning models, including Gradient Boosting Decision Trees (GBDTs) and Neural Networks with and without simple feature engineering, as the building blocks for the pipeline. We find that GBDT models with dropout display high performance, robustness and generalisability with relatively low complexity and reduced computational cost. We then show that online learning techniques can be used in post-prediction processing to enhance the results. In particular, dynamic feature neutralisation, an efficient procedure that requires no retraining of models and can be applied post-prediction to any machine learning model, improves robustness by reducing drawdown in volatile market conditions. Furthermore, we demonstrate that the creation of model ensembles through dynamic model selection based on recent model performance leads to improved performance over baseline by improving the Sharpe and Calmar ratios. We also evaluate the robustness of our pipeline across different data splits and random seeds with good reproducibility of results.
ICE-NODE: Integration of Clinical Embeddings with Neural Ordinary Differential Equations
Jul 06, 2022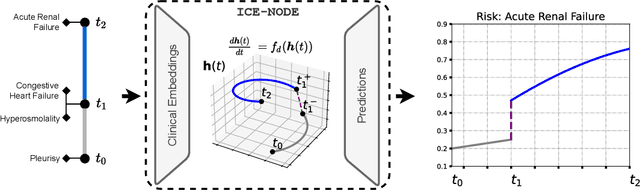
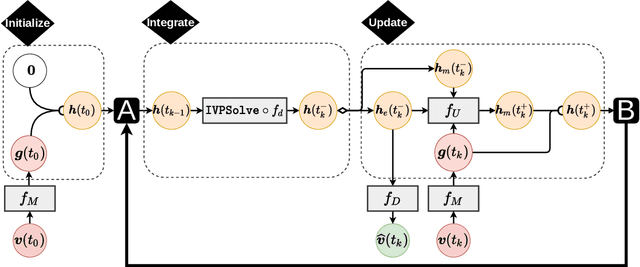
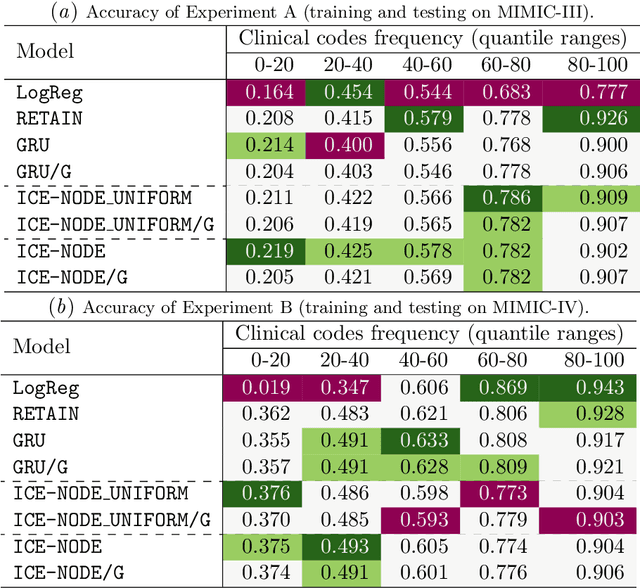
Early diagnosis of disease can result in improved health outcomes, such as higher survival rates and lower treatment costs. With the massive amount of information in electronic health records (EHRs), there is great potential to use machine learning (ML) methods to model disease progression aimed at early prediction of disease onset and other outcomes. In this work, we employ recent innovations in neural ODEs to harness the full temporal information of EHRs. We propose ICE-NODE (Integration of Clinical Embeddings with Neural Ordinary Differential Equations), an architecture that temporally integrates embeddings of clinical codes and neural ODEs to learn and predict patient trajectories in EHRs. We apply our method to the publicly available MIMIC-III and MIMIC-IV datasets, reporting improved prediction results compared to state-of-the-art methods, specifically for clinical codes that are not frequently observed in EHRs. We also show that ICE-NODE is more competent at predicting certain medical conditions, like acute renal failure and pulmonary heart disease, and is also able to produce patient risk trajectories over time that can be exploited for further predictions.
Similarity measure for sparse time course data based on Gaussian processes
Feb 24, 2021We propose a similarity measure for sparsely sampled time course data in the form of a log-likelihood ratio of Gaussian processes (GP). The proposed GP similarity is similar to a Bayes factor and provides enhanced robustness to noise in sparse time series, such as those found in various biological settings, e.g., gene transcriptomics. We show that the GP measure is equivalent to the Euclidean distance when the noise variance in the GP is negligible compared to the noise variance of the signal. Our numerical experiments on both synthetic and real data show improved performance of the GP similarity when used in conjunction with two distance-based clustering methods.
Graph-based Topic Extraction from Vector Embeddings of Text Documents: Application to a Corpus of News Articles
Oct 28, 2020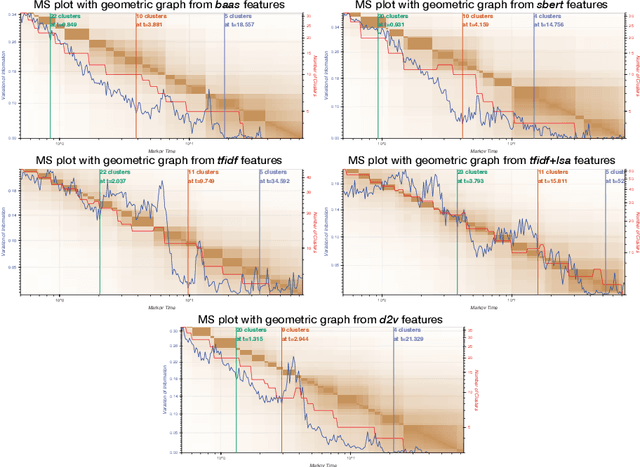
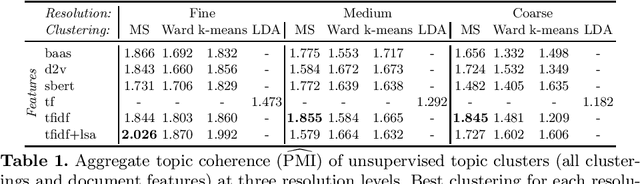
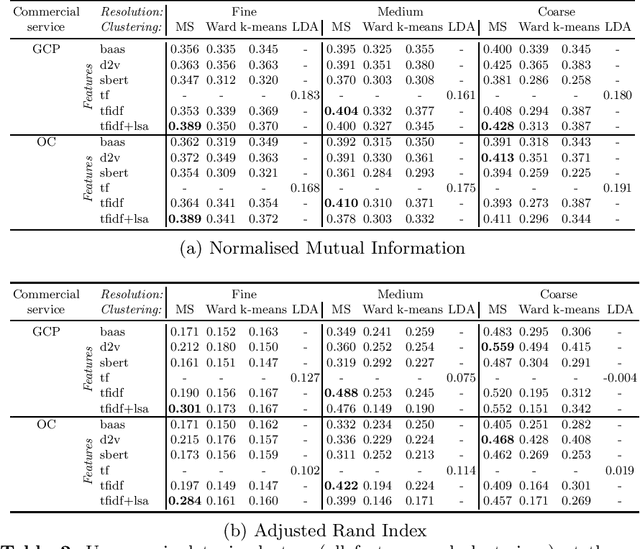
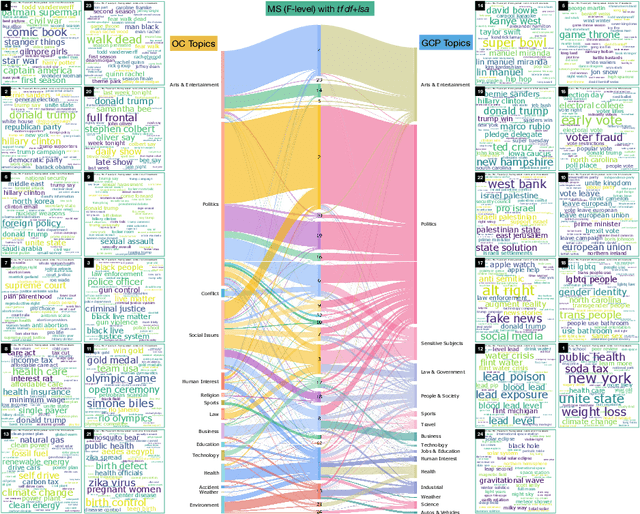
Production of news content is growing at an astonishing rate. To help manage and monitor the sheer amount of text, there is an increasing need to develop efficient methods that can provide insights into emerging content areas, and stratify unstructured corpora of text into `topics' that stem intrinsically from content similarity. Here we present an unsupervised framework that brings together powerful vector embeddings from natural language processing with tools from multiscale graph partitioning that can reveal natural partitions at different resolutions without making a priori assumptions about the number of clusters in the corpus. We show the advantages of graph-based clustering through end-to-end comparisons with other popular clustering and topic modelling methods, and also evaluate different text vector embeddings, from classic Bag-of-Words to Doc2Vec to the recent transformers based model Bert. This comparative work is showcased through an analysis of a corpus of US news coverage during the presidential election year of 2016.
BART-based inference for Poisson processes
May 16, 2020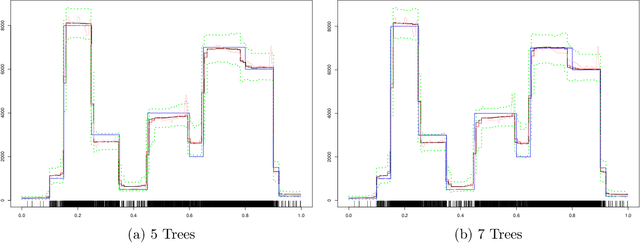

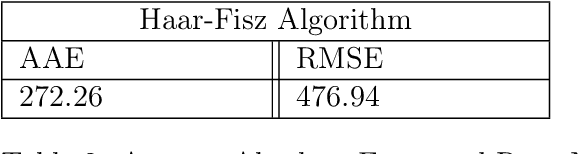
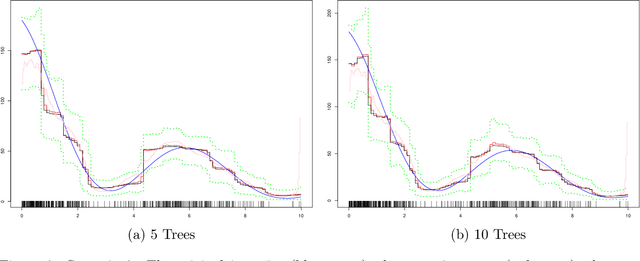
The effectiveness of Bayesian Additive Regression Trees (BART) has been demonstrated in a variety of contexts including non parametric regression and classification. Here we introduce a BART scheme for estimating the intensity of inhomogeneous Poisson Processes. Poisson intensity estimation is a vital task in various applications including medical imaging, astrophysics and network traffic analysis. Our approach enables full posterior inference of the intensity in a nonparametric regression setting. We demonstrate the performance of our scheme through simulation studies on synthetic and real datasets in one and two dimensions, and compare our approach to alternative approaches.
Geometric graphs from data to aid classification tasks with graph convolutional networks
May 08, 2020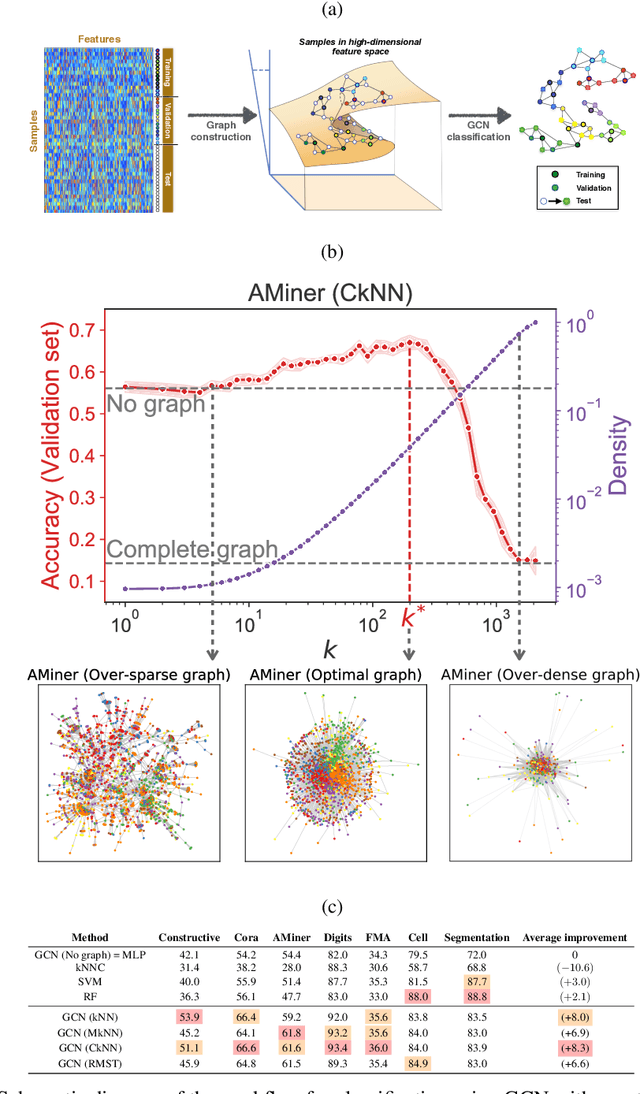
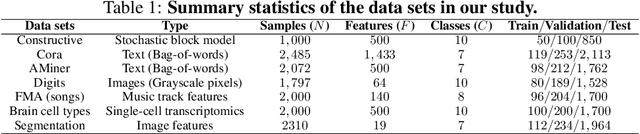
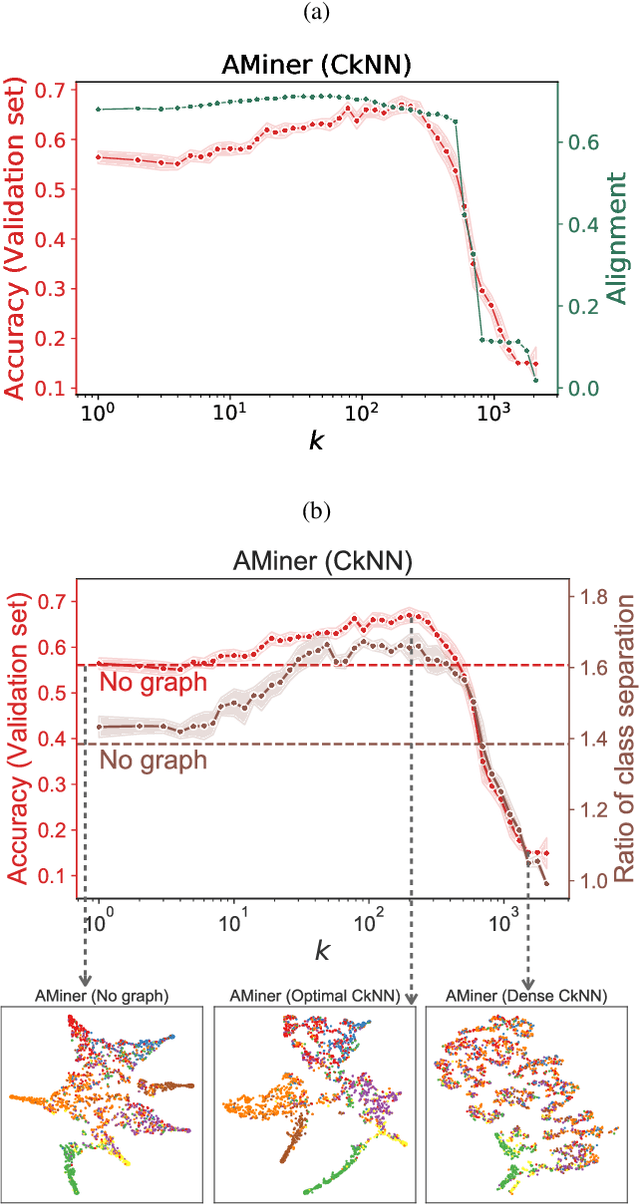
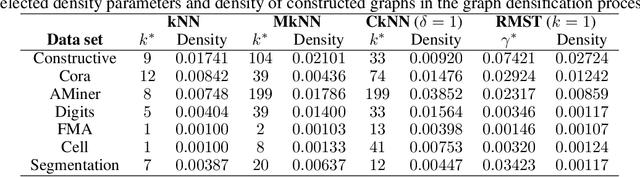
Classification is a classic problem in data analytics and has been approached from many different angles, including machine learning. Traditionally, machine learning methods classify samples based solely on their features. This paradigm is evolving. Recent developments on Graph Convolutional Networks have shown that explicitly using information not directly present in the features to represent a type of relationship between samples can improve the classification performance by a significant margin. However, graphs are not often immediately present in data sets, thus limiting the applicability of Graph Convolutional Networks. In this paper, we explore if graphs extracted from the features themselves can aid classification performance. First, we show that constructing optimal geometric graphs directly from data features can aid classification tasks on both synthetic and real-world data sets from different domains. Second, we introduce two metrics to characterize optimal graphs: i) by measuring the alignment between the subspaces spanned by the features convolved with the graph and the ground truth; and ii) ratio of class separation in the output activations of Graph Convolutional Networks: this shows that the optimal graph maximally separates classes. Finally, we find that sparsifying the optimal graph can potentially improve classification performance.
Semi-supervised classification on graphs using explicit diffusion dynamics
Sep 24, 2019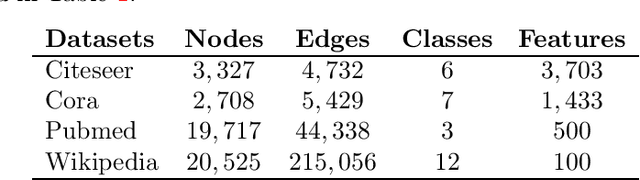
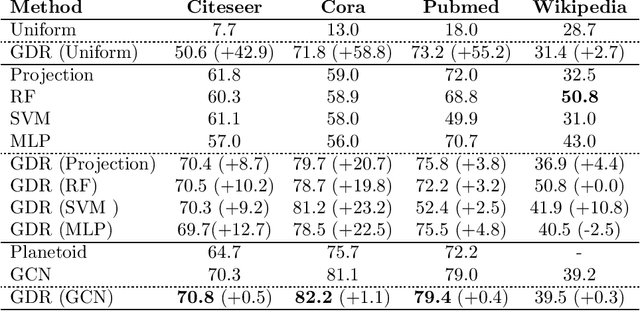


Classification tasks based on feature vectors can be significantly improved by including within deep learning a graph that summarises pairwise relationships between the samples. Intuitively, the graph acts as a conduit to channel and bias the inference of class labels. Here, we study classification methods that consider the graph as the originator of an explicit graph diffusion. We show that appending graph diffusion to feature-based learning as an \textit{a posteriori} refinement achieves state-of-the-art classification accuracy. This method, which we call Graph Diffusion Reclassification (GDR), uses overshooting events of a diffusive graph dynamics to reclassify individual nodes. The method uses intrinsic measures of node influence, which are distinct for each node, and allows the evaluation of the relationship and importance of features and graph for classification. We also present diff-GCN, a simple extension of Graph Convolutional Neural Network (GCN) architectures that leverages explicit diffusion dynamics, and allows the natural use of directed graphs. To showcase our methods, we use benchmark datasets of documents with associated citation data.
Graph-based data clustering via multiscale community detection
Sep 06, 2019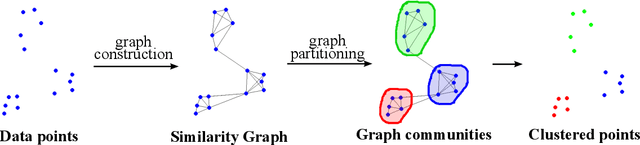
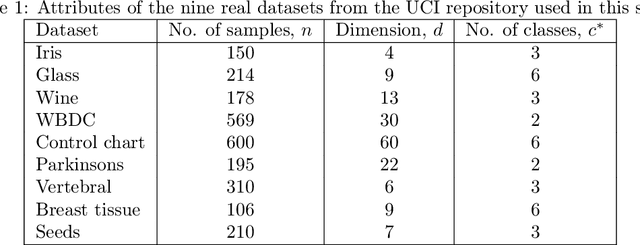
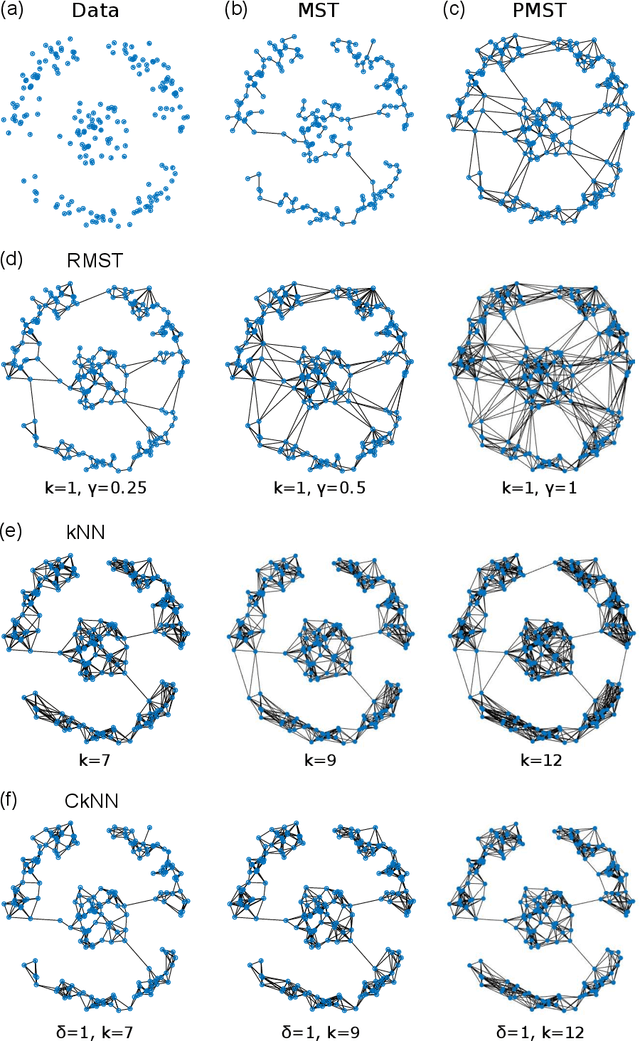
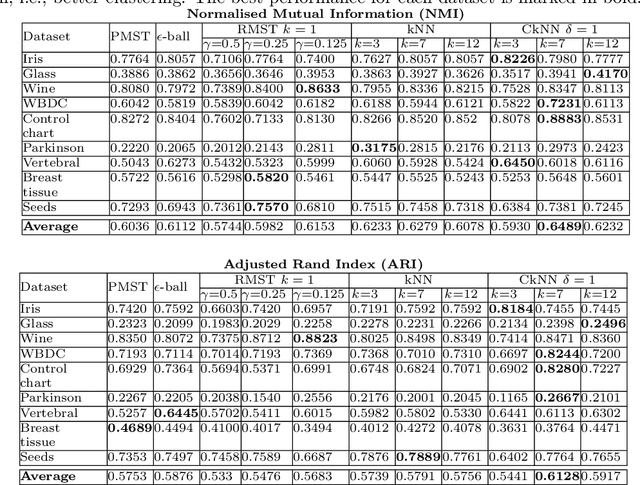
We present a graph-theoretical approach to data clustering, which combines the creation of a graph from the data with Markov Stability, a multiscale community detection framework. We show how the multiscale capabilities of the method allow the estimation of the number of clusters, as well as alleviating the sensitivity to the parameters in graph construction. We use both synthetic and benchmark real datasets to compare and evaluate several graph construction methods and clustering algorithms, and show that multiscale graph-based clustering achieves improved performance compared to popular clustering methods without the need to set externally the number of clusters.