 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Promise of Large Language Models in Digital Health: Evidence from Sentiment Analysis in Online Health Communities
Aug 19, 2025Digital health analytics face critical challenges nowadays. The sophisticated analysis of patient-generated health content, which contains complex emotional and medical contexts, requires scarce domain expertise, while traditional ML approaches are constrained by data shortage and privacy limitations in healthcare settings. Online Health Communities (OHCs) exemplify these challenges with mixed-sentiment posts, clinical terminology, and implicit emotional expressions that demand specialised knowledge for accurate Sentiment Analysis (SA). To address these challenges, this study explores how Large Language Models (LLMs) can integrate expert knowledge through in-context learning for SA, providing a scalable solution for sophisticated health data analysis. Specifically, we develop a structured codebook that systematically encodes expert interpretation guidelines, enabling LLMs to apply domain-specific knowledge through targeted prompting rather than extensive training. Six GPT models validated alongside DeepSeek and LLaMA 3.1 are compared with pre-trained language models (BioBERT variants) and lexicon-based methods, using 400 expert-annotated posts from two OHCs. LLMs achieve superior performance while demonstrating expert-level agreement. This high agreement, with no statistically significant difference from inter-expert agreement levels, suggests knowledge integration beyond surface-level pattern recognition. The consistent performance across diverse LLM models, supported by in-context learning, offers a promising solution for digital health analytics. This approach addresses the critical challenge of expert knowledge shortage in digital health research, enabling real-time, expert-quality analysis for patient monitoring, intervention assessment, and evidence-based health strategies.
Geometric graphs from data to aid classification tasks with graph convolutional networks
May 08, 2020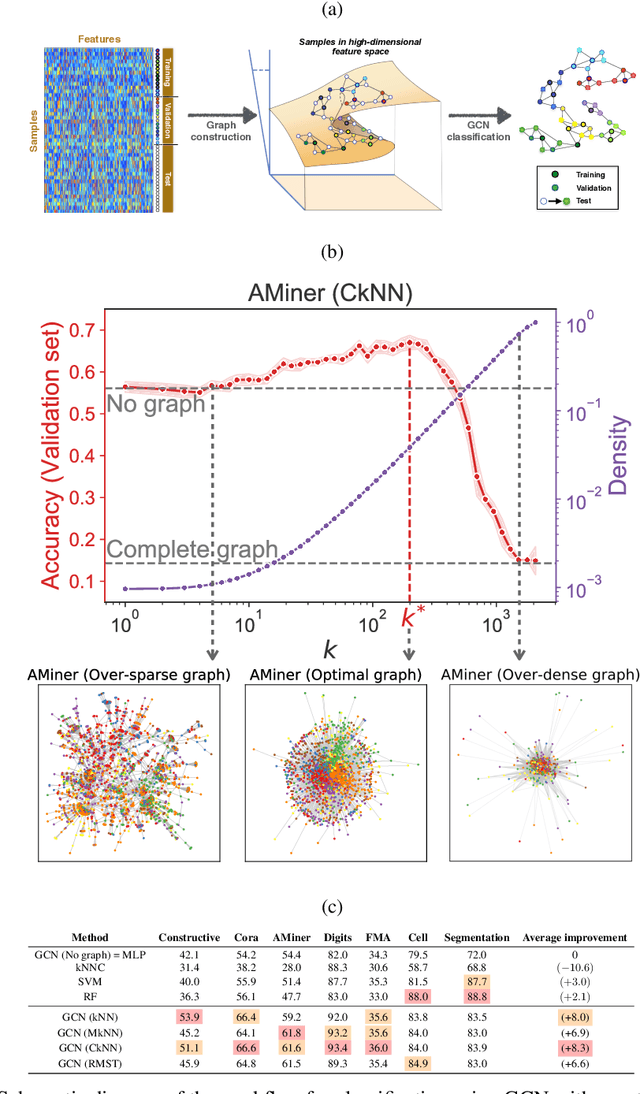
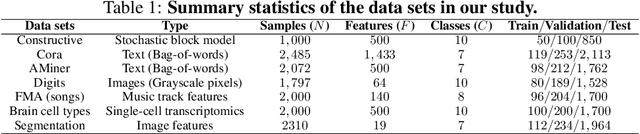
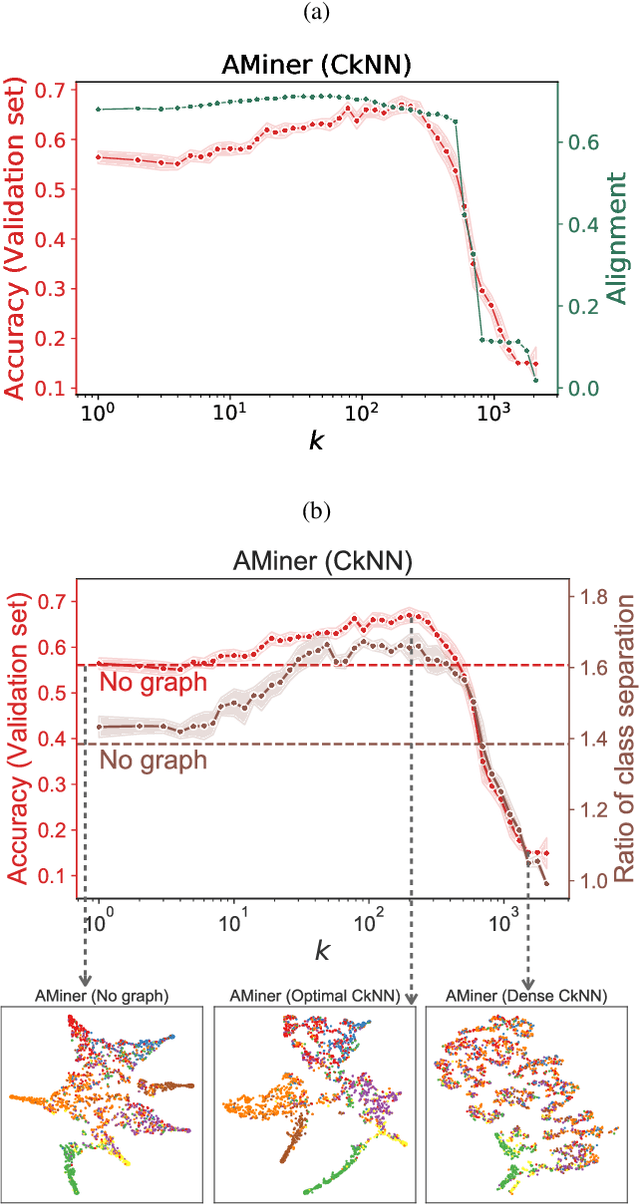
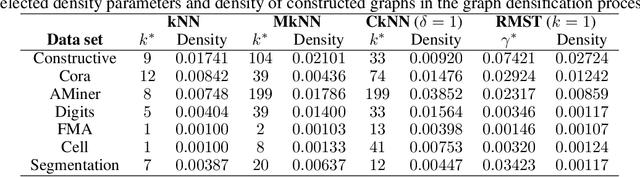
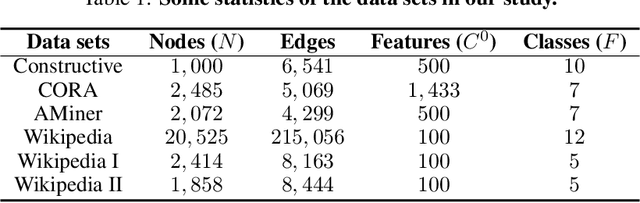
Classification is a classic problem in data analytics and has been approached from many different angles, including machine learning. Traditionally, machine learning methods classify samples based solely on their features. This paradigm is evolving. Recent developments on Graph Convolutional Networks have shown that explicitly using information not directly present in the features to represent a type of relationship between samples can improve the classification performance by a significant margin. However, graphs are not often immediately present in data sets, thus limiting the applicability of Graph Convolutional Networks. In this paper, we explore if graphs extracted from the features themselves can aid classification performance. First, we show that constructing optimal geometric graphs directly from data features can aid classification tasks on both synthetic and real-world data sets from different domains. Second, we introduce two metrics to characterize optimal graphs: i) by measuring the alignment between the subspaces spanned by the features convolved with the graph and the ground truth; and ii) ratio of class separation in the output activations of Graph Convolutional Networks: this shows that the optimal graph maximally separates classes. Finally, we find that sparsifying the optimal graph can potentially improve classification performance.
Quantifying the alignment of graph and features in deep learning
May 30, 2019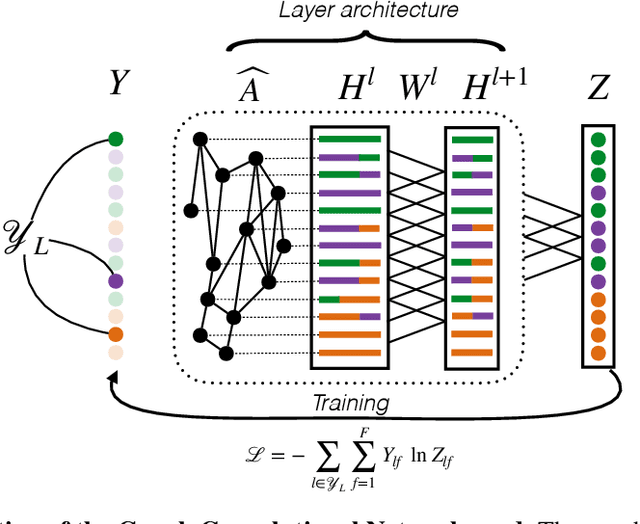
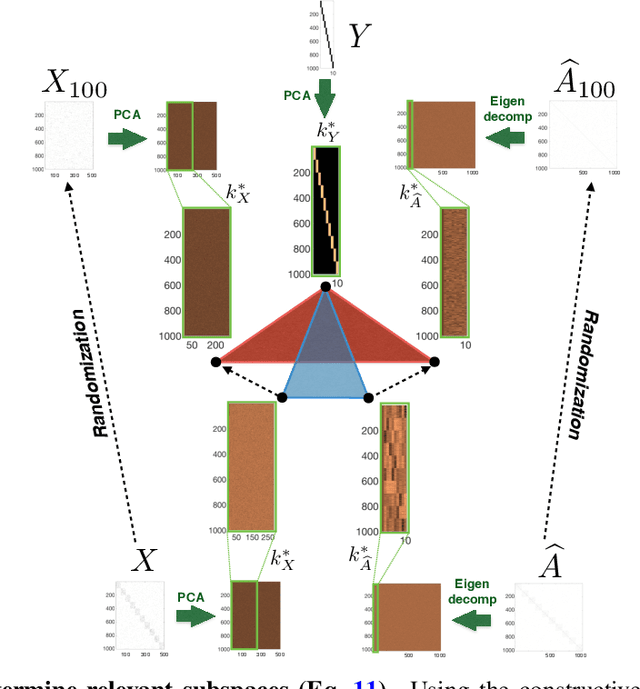
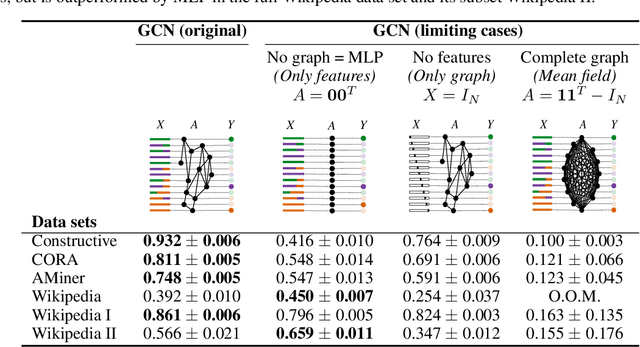
We show that the classification performance of Graph Convolutional Networks is related to the alignment between features, graph and ground truth, which we quantify using a subspace alignment measure corresponding to the Frobenius norm of the matrix of pairwise chordal distances between three subspaces associated with features, graph and ground truth. The proposed measure is based on the principal angles between subspaces and has both spectral and geometrical interpretations. We showcase the relationship between the subspace alignment measure and the classification performance through the study of limiting cases of Graph Convolutional Networks as well as systematic randomizations of both features and graph structure applied to a constructive example and several examples of citation networks of different origin. The analysis also reveals the relative importance of the graph and features for classification purposes.