 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Human Performance: A Vision-Language Multi-Agent Approach for Quality Control in Pharmaceutical Manufacturing
Feb 24, 2026Colony-forming unit (CFU) detection is critical in pharmaceutical manufacturing, serving as a key component of Environmental Monitoring programs and ensuring compliance with stringent quality standards. Manual counting is labor-intensive and error-prone, while deep learning (DL) approaches, though accurate, remain vulnerable to sample quality variations and artifacts. Building on our earlier CNN-based framework (Beznik et al., 2020), we evaluated YOLOv5, YOLOv7, and YOLOv8 for CFU detection; however, these achieved only 97.08 percent accuracy, insufficient for pharmaceutical-grade requirements. A custom Detectron2 model trained on GSK's dataset of over 50,000 Petri dish images achieved 99 percent detection rate with 2 percent false positives and 0.6 percent false negatives. Despite high validation accuracy, Detectron2 performance degrades on outlier cases including contaminated plates, plastic artifacts, or poor optical clarity. To address this, we developed a multi-agent framework combining DL with vision-language models (VLMs). The VLM agent first classifies plates as valid or invalid. For valid samples, both DL and VLM agents independently estimate colony counts. When predictions align within 5 percent, results are automatically recorded in Postgres and SAP; otherwise, samples are routed for expert review. Expert feedback enables continuous retraining and self-improvement. Initial DL-based automation reduced human verification by 50 percent across vaccine manufacturing sites. With VLM integration, this increased to 85 percent, delivering significant operational savings. The proposed system provides a scalable, auditable, and regulation-ready solution for microbiological quality control, advancing automation in biopharmaceutical production.
Comparative Evaluation of Applicability Domain Definition Methods for Regression Models
Nov 01, 2024



The applicability domain refers to the range of data for which the prediction of the predictive model is expected to be reliable and accurate and using a model outside its applicability domain can lead to incorrect results. The ability to define the regions in data space where a predictive model can be safely used is a necessary condition for having safer and more reliable predictions to assure the reliability of new predictions. However, defining the applicability domain of a model is a challenging problem, as there is no clear and universal definition or metric for it. This work aims to make the applicability domain more quantifiable and pragmatic. Eight applicability domain detection techniques were applied to seven regression models, trained on five different datasets, and their performance was benchmarked using a validation framework. We also propose a novel approach based on non-deterministic Bayesian neural networks to define the applicability domain of the model. Our method exhibited superior accuracy in defining the Applicability Domain compared to previous methods, highlighting its potential in this regard.
Forecast reconciliation for vaccine supply chain optimization
May 02, 2023Vaccine supply chain optimization can benefit from hierarchical time series forecasting, when grouping the vaccines by type or location. However, forecasts of different hierarchy levels become incoherent when higher levels do not match the sum of the lower levels forecasts, which can be addressed by reconciliation methods. In this paper, we tackle the vaccine sale forecasting problem by modeling sales data from GSK between 2010 and 2021 as a hierarchical time series. After forecasting future values with several ARIMA models, we systematically compare the performance of various reconciliation methods, using statistical tests. We also compare the performance of the forecast before and after COVID. The results highlight Minimum Trace and Weighted Least Squares with Structural scaling as the best performing methods, which provided a coherent forecast while reducing the forecast error of the baseline ARIMA.
A study of parameters affecting visual saliency assessment
Jul 22, 2013

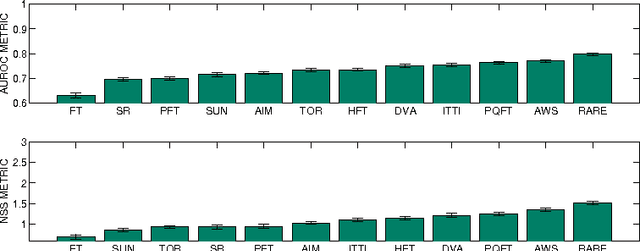

Since the early 2000s, computational visual saliency has been a very active research area. Each year, more and more new models are published in the main computer vision conferences. Nowadays, one of the big challenges is to find a way to fairly evaluate all of these models. In this paper, a new framework is proposed to assess models of visual saliency. This evaluation is divided into three experiments leading to the proposition of a new evaluation framework. Each experiment is based on a basic question: 1) there are two ground truths for saliency evaluation: what are the differences between eye fixations and manually segmented salient regions?, 2) the properties of the salient regions: for example, do large, medium and small salient regions present different difficulties for saliency models? and 3) the metrics used to assess saliency models: what advantages would there be to mix them with PCA? Statistical analysis is used here to answer each of these three questions.