 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Temporally Object-based Video Co-Segmentation
Feb 09, 2018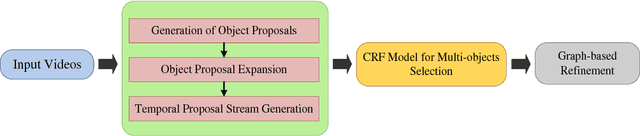
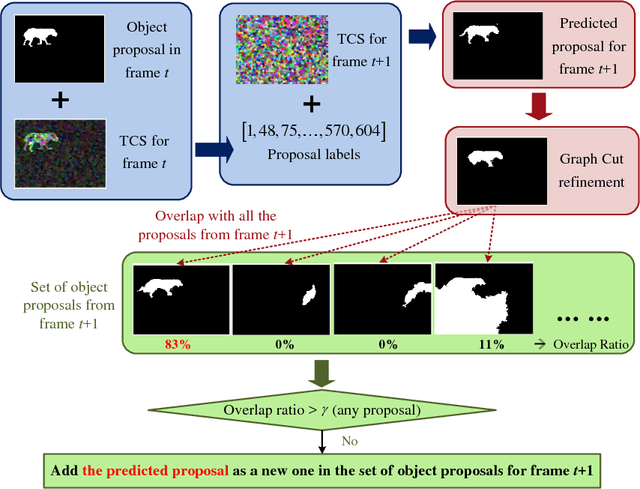

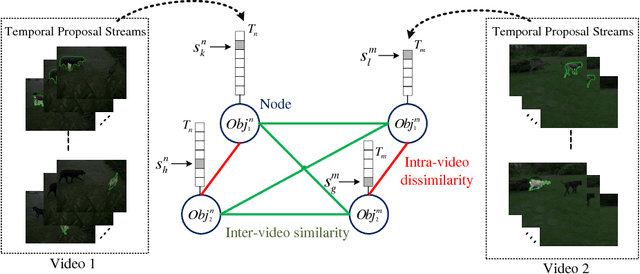
In this paper, we propose an unsupervised video object co-segmentation framework based on the primary object proposals to extract the common foreground object(s) from a given video set. In addition to the objectness attributes and motion coherence our framework exploits the temporal consistency of the object-like regions between adjacent frames to enrich the set of original object proposals. We call the enriched proposal sets temporal proposal streams, as they are composed of the most similar proposals from each frame augmented with predicted proposals using temporally consistent superpixel information. The temporal proposal streams represent all the possible region tubes of the objects. Therefore, we formulate a graphical model to select a proposal stream for each object in which the pairwise potentials consist of the appearance dissimilarity between different streams in the same video and also the similarity between the streams in different videos. This model is suitable for single (multiple) foreground objects in two (more) videos, which can be solved by any existing energy minimization method. We evaluate our proposed framework by comparing it to other video co-segmentation algorithms. Our method achieves improved performance on state-of-the-art benchmark datasets.