 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models and Control Mechanisms Improve Text Readability of Biomedical Abstracts
Sep 22, 2023Biomedical literature often uses complex language and inaccessible professional terminologies. That is why simplification plays an important role in improving public health literacy. Applying Natural Language Processing (NLP) models to automate such tasks allows for quick and direct accessibility for lay readers. In this work, we investigate the ability of state-of-the-art large language models (LLMs) on the task of biomedical abstract simplification, using the publicly available dataset for plain language adaptation of biomedical abstracts (\textbf{PLABA}). The methods applied include domain fine-tuning and prompt-based learning (PBL) on: 1) Encoder-decoder models (T5, SciFive, and BART), 2) Decoder-only GPT models (GPT-3.5 and GPT-4) from OpenAI and BioGPT, and 3) Control-token mechanisms on BART-based models. We used a range of automatic evaluation metrics, including BLEU, ROUGE, SARI, and BERTscore, and also conducted human evaluations. BART-Large with Control Token (BART-L-w-CT) mechanisms reported the highest SARI score of 46.54 and T5-base reported the highest BERTscore 72.62. In human evaluation, BART-L-w-CTs achieved a better simplicity score over T5-Base (2.9 vs. 2.2), while T5-Base achieved a better meaning preservation score over BART-L-w-CTs (3.1 vs. 2.6). We also categorised the system outputs with examples, hoping this will shed some light for future research on this task. Our code, fine-tuned models, and data splits are available at \url{https://github.com/HECTA-UoM/PLABA-MU}
Deep Learning Approaches to Lexical Simplification: A Survey
May 19, 2023Lexical Simplification (LS) is the task of replacing complex for simpler words in a sentence whilst preserving the sentence's original meaning. LS is the lexical component of Text Simplification (TS) with the aim of making texts more accessible to various target populations. A past survey (Paetzold and Specia, 2017) has provided a detailed overview of LS. Since this survey, however, the AI/NLP community has been taken by storm by recent advances in deep learning, particularly with the introduction of large language models (LLM) and prompt learning. The high performance of these models sparked renewed interest in LS. To reflect these recent advances, we present a comprehensive survey of papers published between 2017 and 2023 on LS and its sub-tasks with a special focus on deep learning. We also present benchmark datasets for the future development of LS systems.
Natural language processing on customer note data
May 03, 2023



Automatic analysis of customer data for businesses is an area that is of interest to companies. Business to business data is studied rarely in academia due to the sensitive nature of such information. Applying natural language processing can speed up the analysis of prohibitively large sets of data. This paper addresses this subject and applies sentiment analysis, topic modelling and keyword extraction to a B2B data set. We show that accurate sentiment can be extracted from the notes automatically and the notes can be sorted by relevance into different topics. We see that without clear separation topics can lack relevance to a business context.
Lexical Complexity Prediction: An Overview
Mar 08, 2023



The occurrence of unknown words in texts significantly hinders reading comprehension. To improve accessibility for specific target populations, computational modelling has been applied to identify complex words in texts and substitute them for simpler alternatives. In this paper, we present an overview of computational approaches to lexical complexity prediction focusing on the work carried out on English data. We survey relevant approaches to this problem which include traditional machine learning classifiers (e.g. SVMs, logistic regression) and deep neural networks as well as a variety of features, such as those inspired by literature in psycholinguistics as well as word frequency, word length, and many others. Furthermore, we introduce readers to past competitions and available datasets created on this topic. Finally, we include brief sections on applications of lexical complexity prediction, such as readability and text simplification, together with related studies on languages other than English.
Findings of the TSAR-2022 Shared Task on Multilingual Lexical Simplification
Feb 06, 2023



We report findings of the TSAR-2022 shared task on multilingual lexical simplification, organized as part of the Workshop on Text Simplification, Accessibility, and Readability TSAR-2022 held in conjunction with EMNLP 2022. The task called the Natural Language Processing research community to contribute with methods to advance the state of the art in multilingual lexical simplification for English, Portuguese, and Spanish. A total of 14 teams submitted the results of their lexical simplification systems for the provided test data. Results of the shared task indicate new benchmarks in Lexical Simplification with English lexical simplification quantitative results noticeably higher than those obtained for Spanish and (Brazilian) Portuguese.
Deanthropomorphising NLP: Can a Language Model Be Conscious?
Nov 21, 2022

This work is intended as a voice in the discussion over the recent claims that LaMDA, a pretrained language model based on the Transformer model architecture, is sentient. This claim, if confirmed, would have serious ramifications in the Natural Language Processing (NLP) community due to wide-spread use of similar models. However, here we take the position that such a language model cannot be sentient, or conscious, and that LaMDA in particular exhibits no advances over other similar models that would qualify it. We justify this by analysing the Transformer architecture through Integrated Information Theory. We see the claims of consciousness as part of a wider tendency to use anthropomorphic language in NLP reporting. Regardless of the veracity of the claims, we consider this an opportune moment to take stock of progress in language modelling and consider the ethical implications of the task. In order to make this work helpful for readers outside the NLP community, we also present the necessary background in language modelling.
Lexical Simplification Benchmarks for English, Portuguese, and Spanish
Sep 12, 2022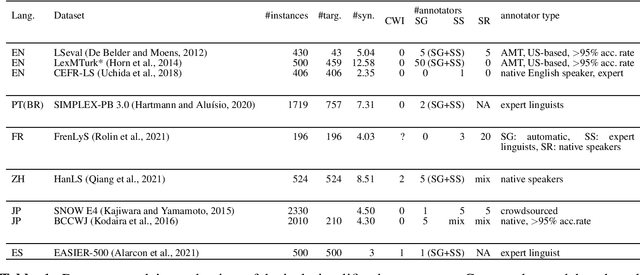
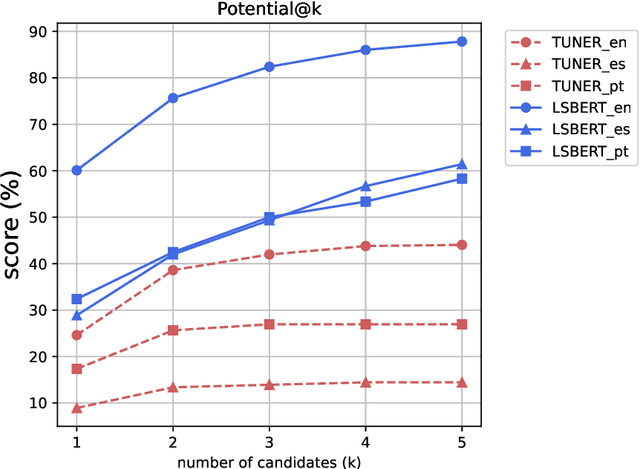
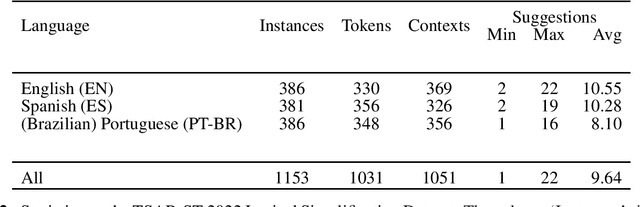
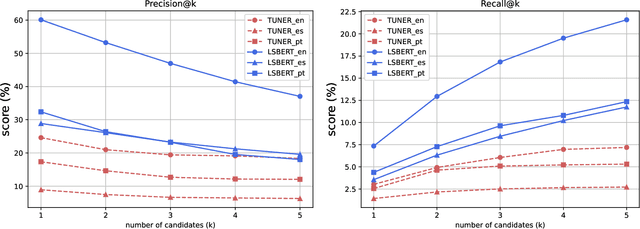
Even in highly-developed countries, as many as 15-30\% of the population can only understand texts written using a basic vocabulary. Their understanding of everyday texts is limited, which prevents them from taking an active role in society and making informed decisions regarding healthcare, legal representation, or democratic choice. Lexical simplification is a natural language processing task that aims to make text understandable to everyone by replacing complex vocabulary and expressions with simpler ones, while preserving the original meaning. It has attracted considerable attention in the last 20 years, and fully automatic lexical simplification systems have been proposed for various languages. The main obstacle for the progress of the field is the absence of high-quality datasets for building and evaluating lexical simplification systems. We present a new benchmark dataset for lexical simplification in English, Spanish, and (Brazilian) Portuguese, and provide details about data selection and annotation procedures. This is the first dataset that offers a direct comparison of lexical simplification systems for three languages. To showcase the usability of the dataset, we adapt two state-of-the-art lexical simplification systems with differing architectures (neural vs.\ non-neural) to all three languages (English, Spanish, and Brazilian Portuguese) and evaluate their performances on our new dataset. For a fairer comparison, we use several evaluation measures which capture varied aspects of the systems' efficacy, and discuss their strengths and weaknesses. We find a state-of-the-art neural lexical simplification system outperforms a state-of-the-art non-neural lexical simplification system in all three languages. More importantly, we find that the state-of-the-art neural lexical simplification systems perform significantly better for English than for Spanish and Portuguese.
Investigating Text Simplification Evaluation
Jul 28, 2021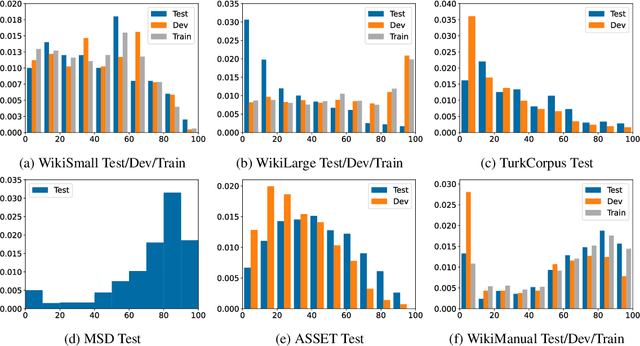
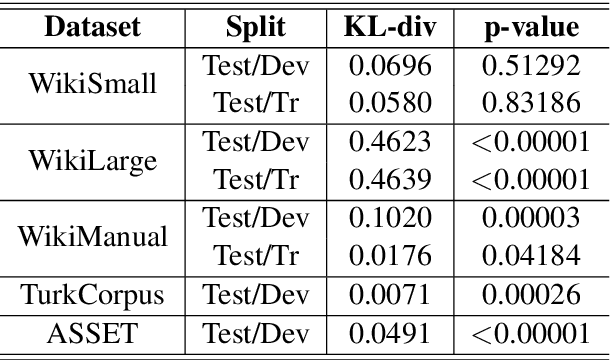
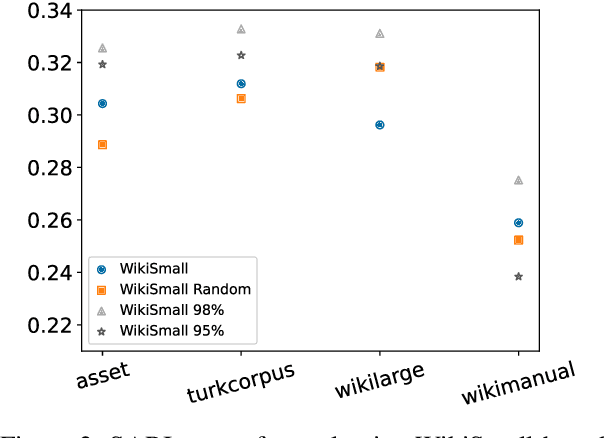
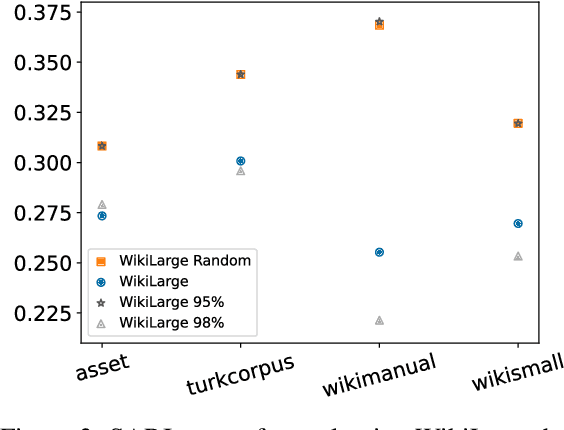
Modern text simplification (TS) heavily relies on the availability of gold standard data to build machine learning models. However, existing studies show that parallel TS corpora contain inaccurate simplifications and incorrect alignments. Additionally, evaluation is usually performed by using metrics such as BLEU or SARI to compare system output to the gold standard. A major limitation is that these metrics do not match human judgements and the performance on different datasets and linguistic phenomena vary greatly. Furthermore, our research shows that the test and training subsets of parallel datasets differ significantly. In this work, we investigate existing TS corpora, providing new insights that will motivate the improvement of existing state-of-the-art TS evaluation methods. Our contributions include the analysis of TS corpora based on existing modifications used for simplification and an empirical study on TS models performance by using better-distributed datasets. We demonstrate that by improving the distribution of TS datasets, we can build more robust TS models.
* 7 pages, 3 figures, 1 table
SemEval-2021 Task 1: Lexical Complexity Prediction
Jun 01, 2021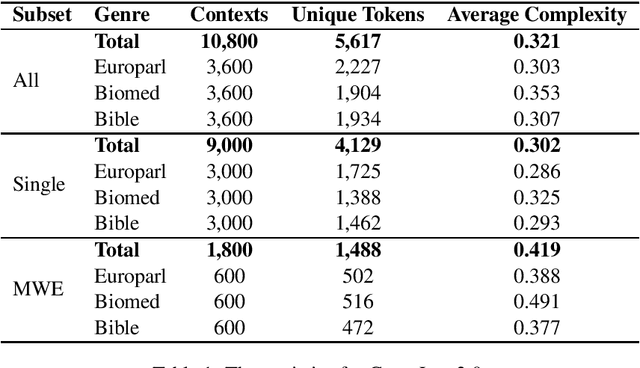
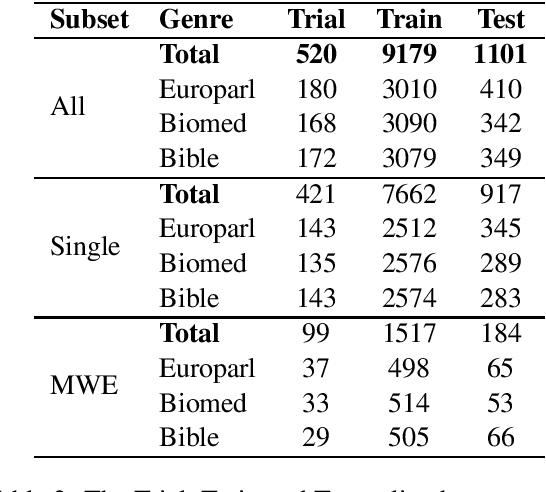
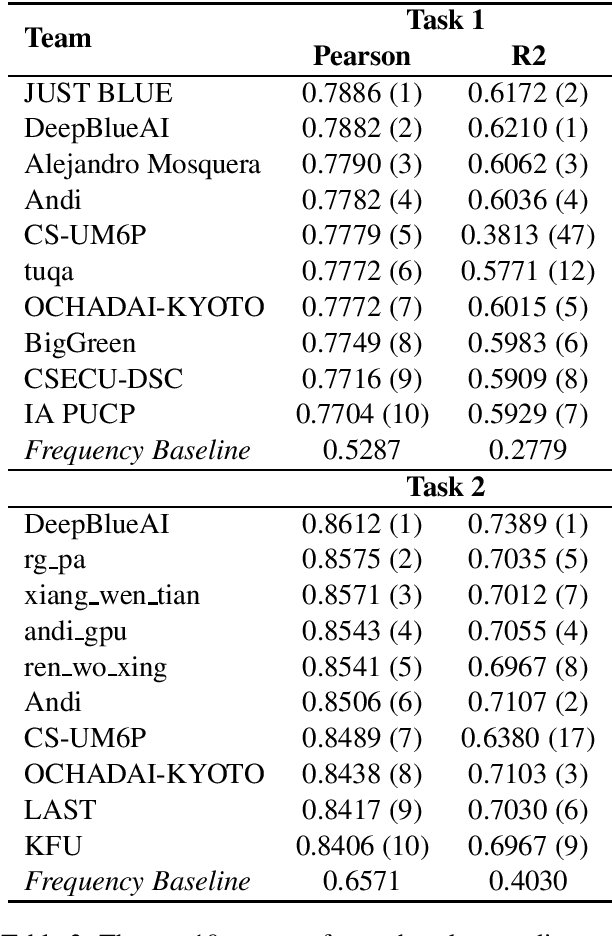
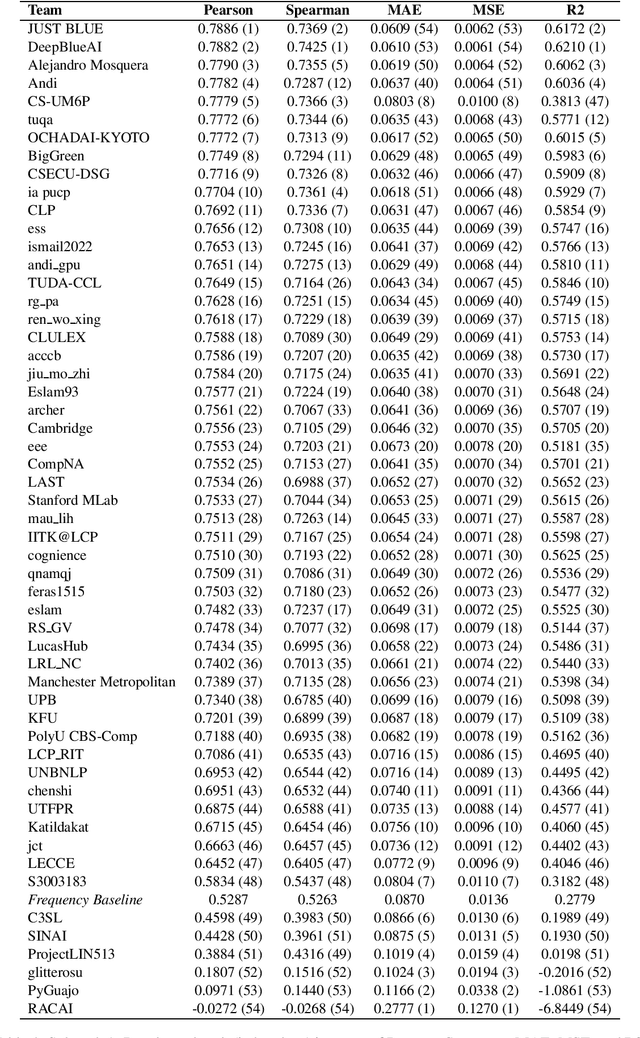
This paper presents the results and main findings of SemEval-2021 Task 1 - Lexical Complexity Prediction. We provided participants with an augmented version of the CompLex Corpus (Shardlow et al 2020). CompLex is an English multi-domain corpus in which words and multi-word expressions (MWEs) were annotated with respect to their complexity using a five point Likert scale. SemEval-2021 Task 1 featured two Sub-tasks: Sub-task 1 focused on single words and Sub-task 2 focused on MWEs. The competition attracted 198 teams in total, of which 54 teams submitted official runs on the test data to Sub-task 1 and 37 to Sub-task 2.
Predicting Lexical Complexity in English Texts
Feb 17, 2021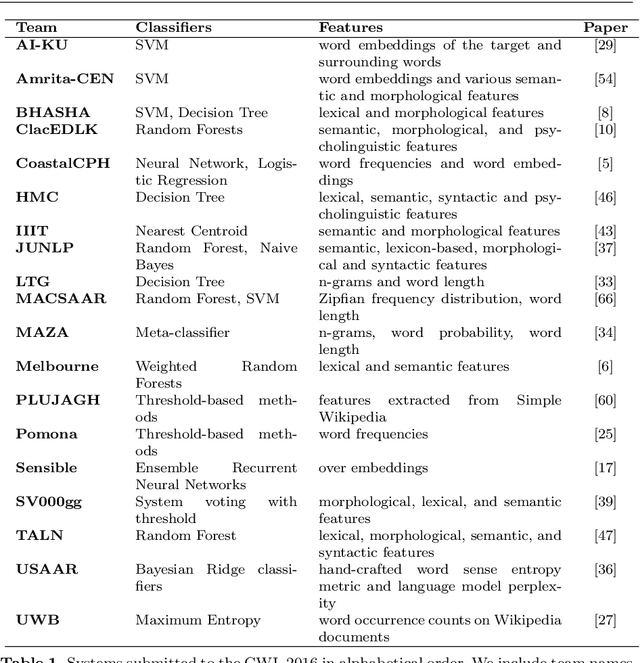
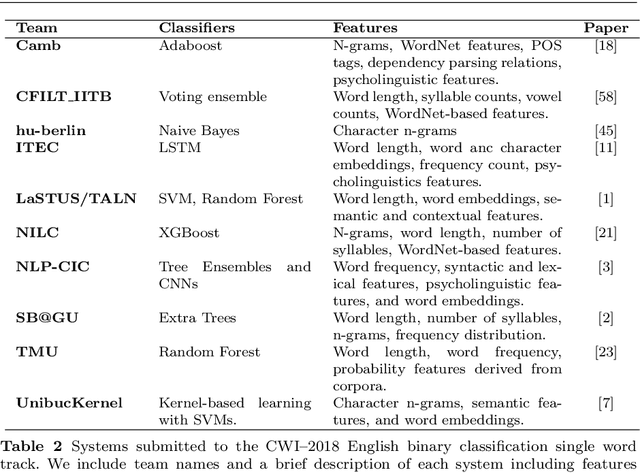
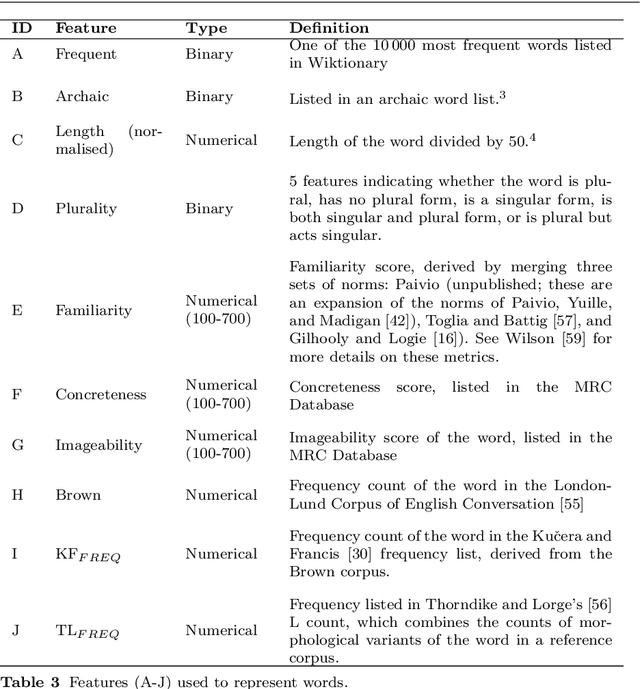
The first step in most text simplification is to predict which words are considered complex for a given target population before carrying out lexical substitution. This task is commonly referred to as Complex Word Identification (CWI) and it is often modelled as a supervised classification problem. For training such systems, annotated datasets in which words and sometimes multi-word expressions are labelled regarding complexity are required. In this paper we analyze previous work carried out in this task and investigate the properties of complex word identification datasets for English.