 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Abstract Options
Nov 06, 2018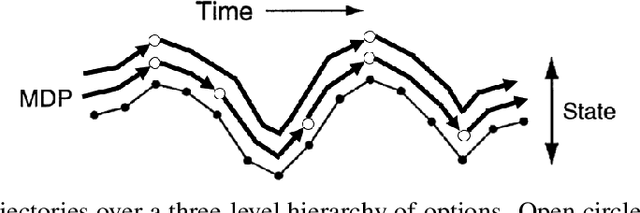

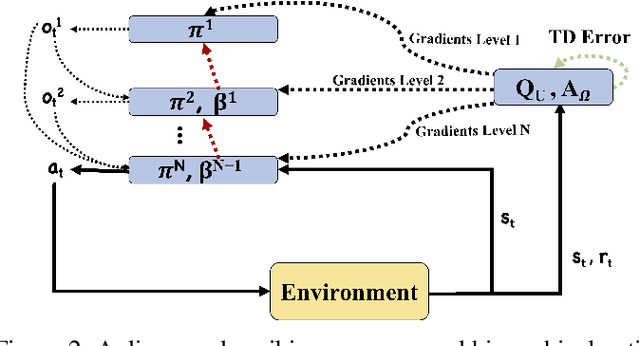
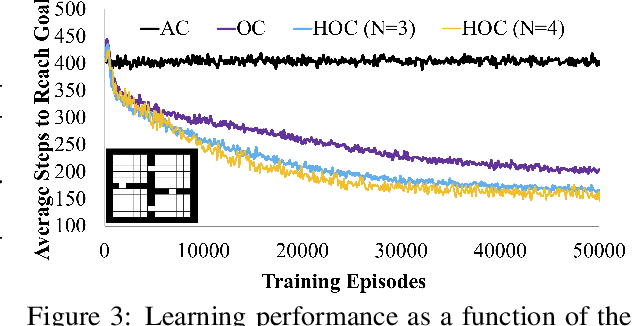
Building systems that autonomously create temporal abstractions from data is a key challenge in scaling learning and planning in reinforcement learning. One popular approach for addressing this challenge is the options framework (Sutton et al., 1999). However, only recently in (Bacon et al., 2017) was a policy gradient theorem derived for online learning of general purpose options in an end to end fashion. In this work, we extend previous work on this topic that only focuses on learning a two-level hierarchy including options and primitive actions to enable learning simultaneously at multiple resolutions in time. We achieve this by considering an arbitrarily deep hierarchy of options where high level temporally extended options are composed of lower level options with finer resolutions in time. We extend results from (Bacon et al., 2017) and derive policy gradient theorems for a deep hierarchy of options. Our proposed hierarchical option-critic architecture is capable of learning internal policies, termination conditions, and hierarchical compositions over options without the need for any intrinsic rewards or subgoals. Our empirical results in both discrete and continuous environments demonstrate the efficiency of our framework.
Learning to Learn without Forgetting By Maximizing Transfer and Minimizing Interference
Oct 29, 2018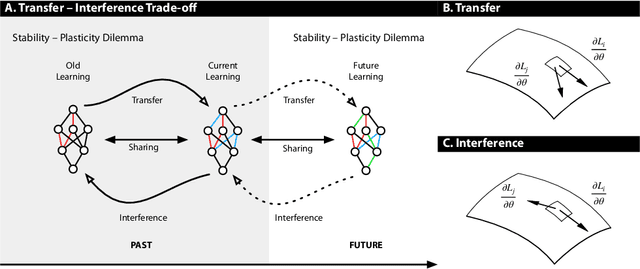
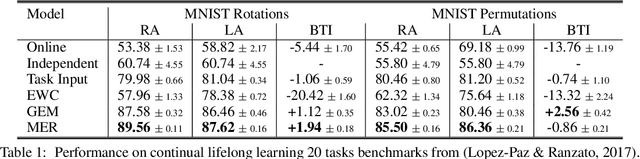
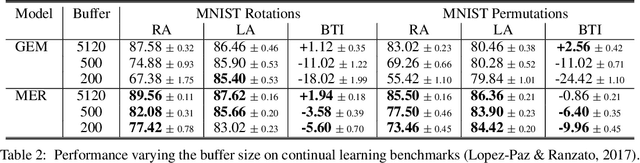
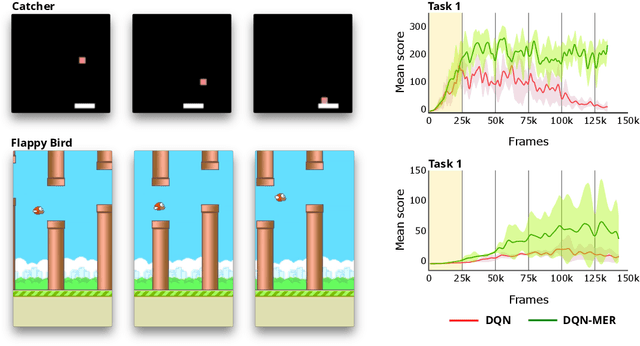
Lack of performance when it comes to continual learning over non-stationary distributions of data remains a major challenge in scaling neural network learning to more human realistic settings. In this work we propose a new conceptualization of the continual learning problem in terms of a trade-off between transfer and interference. We then propose a new algorithm, Meta-Experience Replay (MER), that directly exploits this view by combining experience replay with optimization based meta-learning. This method learns parameters that make interference based on future gradients less likely and transfer based on future gradients more likely. We conduct experiments across continual lifelong supervised learning benchmarks and non-stationary reinforcement learning environments demonstrating that our approach consistently outperforms recently proposed baselines for continual learning. Our experiments show that the gap between the performance of MER and baseline algorithms grows both as the environment gets more non-stationary and as the fraction of the total experiences stored gets smaller.
PepCVAE: Semi-Supervised Targeted Design of Antimicrobial Peptide Sequences
Oct 22, 2018

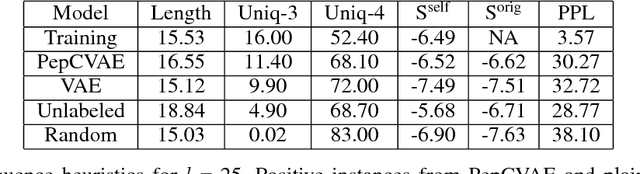
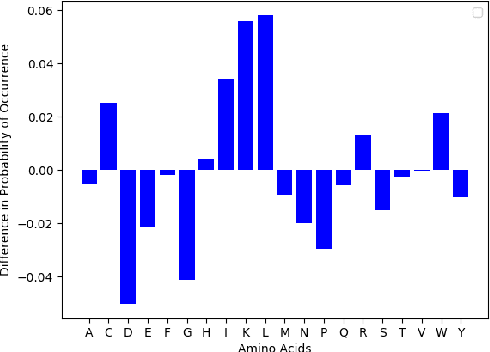
Given the emerging global threat of antimicrobial resistance, new methods for next-generation antimicrobial design are urgently needed. We report a peptide generation framework PepCVAE, based on a semi-supervised variational autoencoder (VAE) model, for designing novel antimicrobial peptide (AMP) sequences. Our model learns a rich latent space of the biological peptide context by taking advantage of abundant, unlabeled peptide sequences. The model further learns a disentangled antimicrobial attribute space by using the feedback from a jointly trained AMP classifier that uses limited labeled instances. The disentangled representation allows for controllable generation of AMPs. Extensive analysis of the PepCVAE-generated sequences reveals superior performance of our model in comparison to a plain VAE, as PepCVAE generates novel AMP sequences with higher long-range diversity, while being closer to the training distribution of biological peptides. These features are highly desired in next-generation antimicrobial design.
Learning to Teach in Cooperative Multiagent Reinforcement Learning
Aug 31, 2018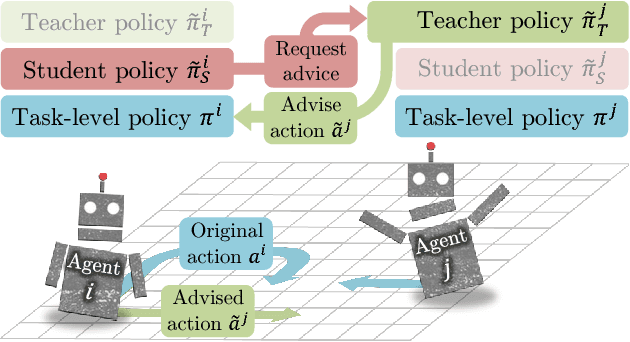

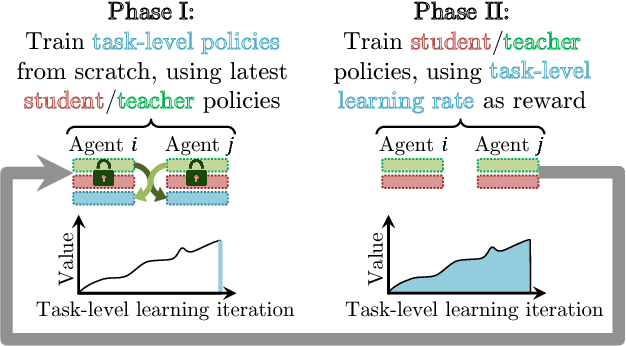
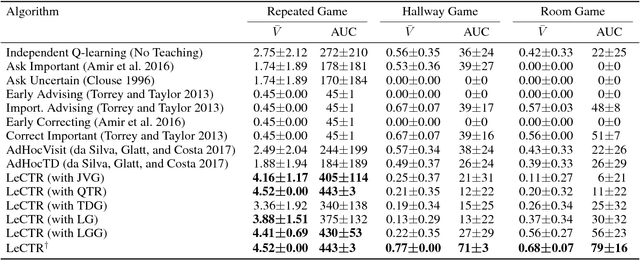
Collective human knowledge has clearly benefited from the fact that innovations by individuals are taught to others through communication. Similar to human social groups, agents in distributed learning systems would likely benefit from communication to share knowledge and teach skills. The problem of teaching to improve agent learning has been investigated by prior works, but these approaches make assumptions that prevent application of teaching to general multiagent problems, or require domain expertise for problems they can apply to. This learning to teach problem has inherent complexities related to measuring long-term impacts of teaching that compound the standard multiagent coordination challenges. In contrast to existing works, this paper presents the first general framework and algorithm for intelligent agents to learn to teach in a multiagent environment. Our algorithm, Learning to Coordinate and Teach Reinforcement (LeCTR), addresses peer-to-peer teaching in cooperative multiagent reinforcement learning. Each agent in our approach learns both when and what to advise, then uses the received advice to improve local learning. Importantly, these roles are not fixed; these agents learn to assume the role of student and/or teacher at the appropriate moments, requesting and providing advice in order to improve teamwide performance and learning. Empirical comparisons against state-of-the-art teaching methods show that our teaching agents not only learn significantly faster, but also learn to coordinate in tasks where existing methods fail.
Scalable Recollections for Continual Lifelong Learning
Feb 26, 2018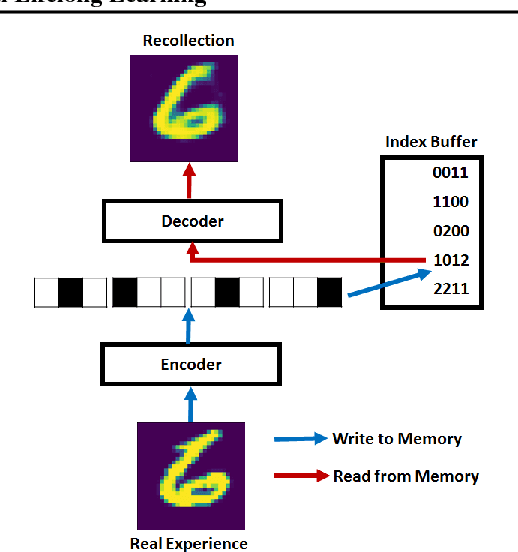

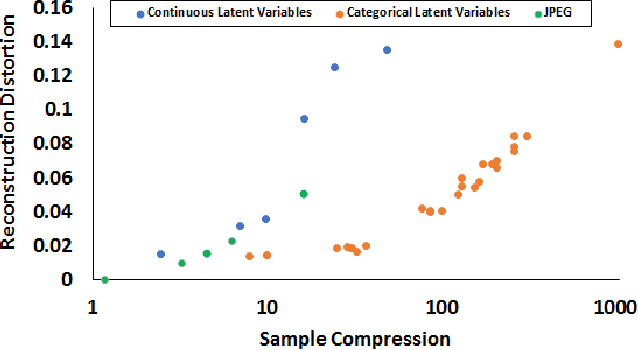
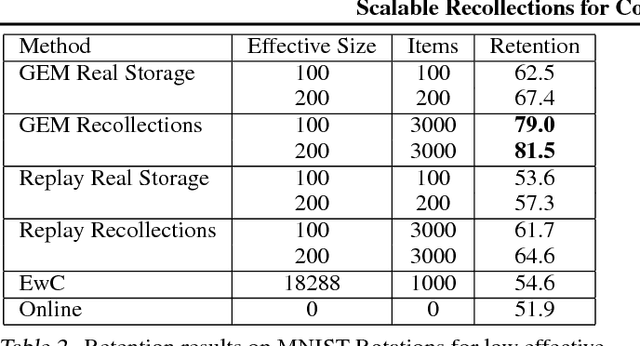
Given the recent success of Deep Learning applied to a variety of single tasks, it is natural to consider more human-realistic settings. Perhaps the most difficult of these settings is that of continual lifelong learning, where the model must learn online over a continuous stream of non-stationary data. A continual lifelong learning system must have three primary capabilities to succeed: it must learn and adapt over time, it must not forget what it has learned, and it must be efficient in both training time and memory. Recent techniques have focused their efforts largely on the first two capabilities while the third capability remains largely unexplored. In this paper, we consider the problem of efficient and effective storage of experiences over very large time-frames. In particular we consider the case where typical experiences are n bits and memories are limited to k bits for k << n. We present a novel scalable architecture and training algorithm in this challenging domain and provide an extensive evaluation of its performance. Our results show that we can achieve considerable gains on top of state-of-the-art methods such as GEM.
Routing Networks: Adaptive Selection of Non-linear Functions for Multi-Task Learning
Dec 31, 2017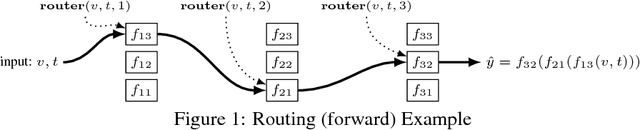
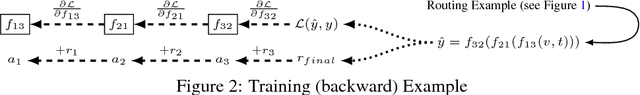
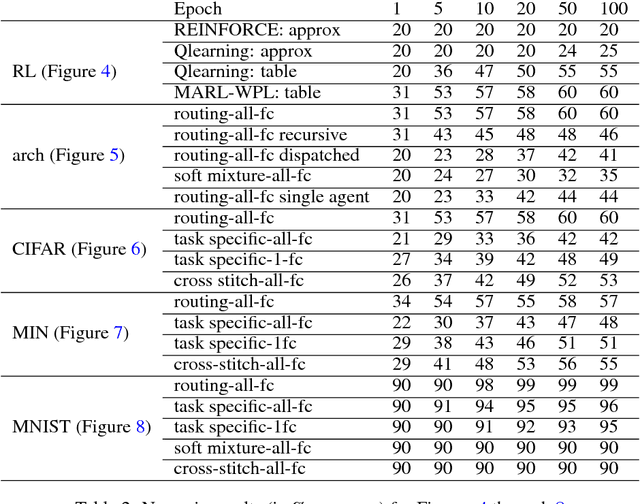
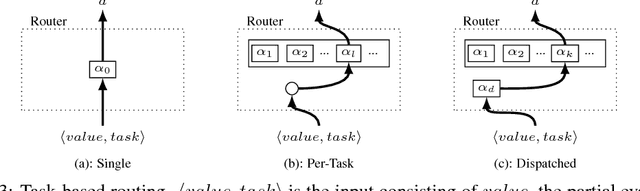
Multi-task learning (MTL) with neural networks leverages commonalities in tasks to improve performance, but often suffers from task interference which reduces the benefits of transfer. To address this issue we introduce the routing network paradigm, a novel neural network and training algorithm. A routing network is a kind of self-organizing neural network consisting of two components: a router and a set of one or more function blocks. A function block may be any neural network - for example a fully-connected or a convolutional layer. Given an input the router makes a routing decision, choosing a function block to apply and passing the output back to the router recursively, terminating when a fixed recursion depth is reached. In this way the routing network dynamically composes different function blocks for each input. We employ a collaborative multi-agent reinforcement learning (MARL) approach to jointly train the router and function blocks. We evaluate our model against cross-stitch networks and shared-layer baselines on multi-task settings of the MNIST, mini-imagenet, and CIFAR-100 datasets. Our experiments demonstrate a significant improvement in accuracy, with sharper convergence. In addition, routing networks have nearly constant per-task training cost while cross-stitch networks scale linearly with the number of tasks. On CIFAR-100 (20 tasks) we obtain cross-stitch performance levels with an 85% reduction in training time.
Representation Stability as a Regularizer for Improved Text Analytics Transfer Learning
Apr 12, 2017


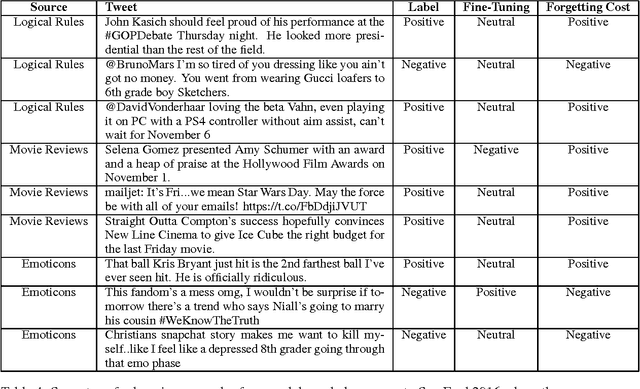
Although neural networks are well suited for sequential transfer learning tasks, the catastrophic forgetting problem hinders proper integration of prior knowledge. In this work, we propose a solution to this problem by using a multi-task objective based on the idea of distillation and a mechanism that directly penalizes forgetting at the shared representation layer during the knowledge integration phase of training. We demonstrate our approach on a Twitter domain sentiment analysis task with sequential knowledge transfer from four related tasks. We show that our technique outperforms networks fine-tuned to the target task. Additionally, we show both through empirical evidence and examples that it does not forget useful knowledge from the source task that is forgotten during standard fine-tuning. Surprisingly, we find that first distilling a human made rule based sentiment engine into a recurrent neural network and then integrating the knowledge with the target task data leads to a substantial gain in generalization performance. Our experiments demonstrate the power of multi-source transfer techniques in practical text analytics problems when paired with distillation. In particular, for the SemEval 2016 Task 4 Subtask A (Nakov et al., 2016) dataset we surpass the state of the art established during the competition with a comparatively simple model architecture that is not even competitive when trained on only the labeled task specific data.