 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the challenges of learning with inference networks on sparse, high-dimensional data
Oct 17, 2017
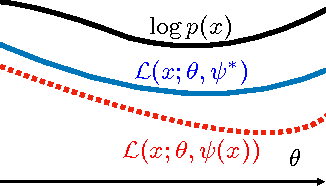
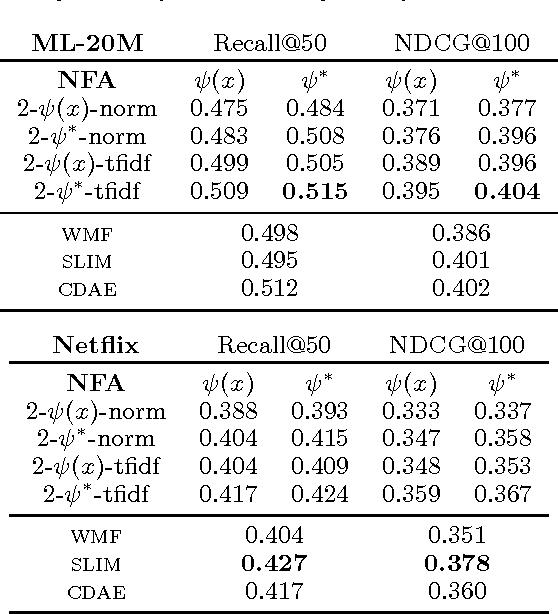
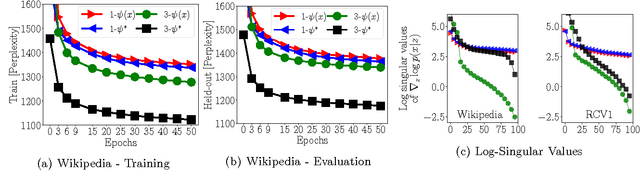
We study parameter estimation in Nonlinear Factor Analysis (NFA) where the generative model is parameterized by a deep neural network. Recent work has focused on learning such models using inference (or recognition) networks; we identify a crucial problem when modeling large, sparse, high-dimensional datasets -- underfitting. We study the extent of underfitting, highlighting that its severity increases with the sparsity of the data. We propose methods to tackle it via iterative optimization inspired by stochastic variational inference \citep{hoffman2013stochastic} and improvements in the sparse data representation used for inference. The proposed techniques drastically improve the ability of these powerful models to fit sparse data, achieving state-of-the-art results on a benchmark text-count dataset and excellent results on the task of top-N recommendation.
The Segmented iHMM: A Simple, Efficient Hierarchical Infinite HMM
Feb 20, 2016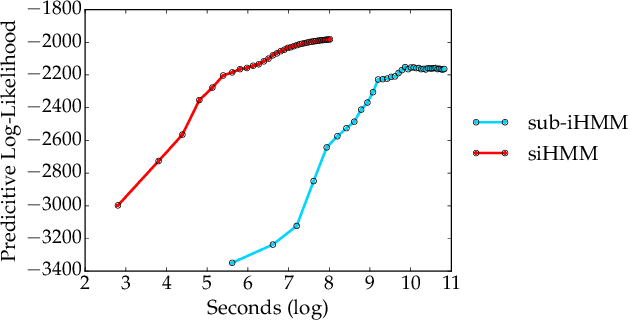
We propose the segmented iHMM (siHMM), a hierarchical infinite hidden Markov model (iHMM) that supports a simple, efficient inference scheme. The siHMM is well suited to segmentation problems, where the goal is to identify points at which a time series transitions from one relatively stable regime to a new regime. Conventional iHMMs often struggle with such problems, since they have no mechanism for distinguishing between high- and low-level dynamics. Hierarchical HMMs (HHMMs) can do better, but they require much more complex and expensive inference algorithms. The siHMM retains the simplicity and efficiency of the iHMM, but outperforms it on a variety of segmentation problems, achieving performance that matches or exceeds that of a more complicated HHMM.
Learning Activation Functions to Improve Deep Neural Networks
Apr 21, 2015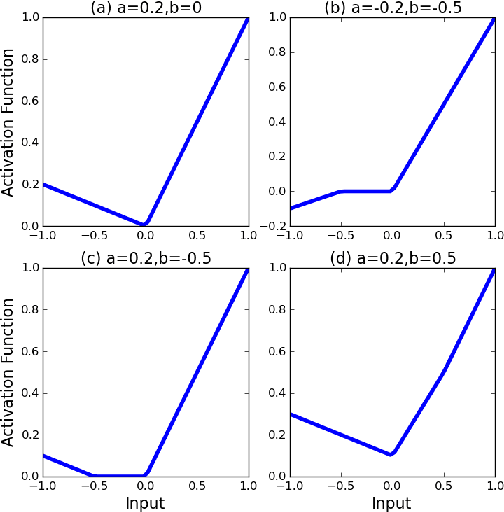
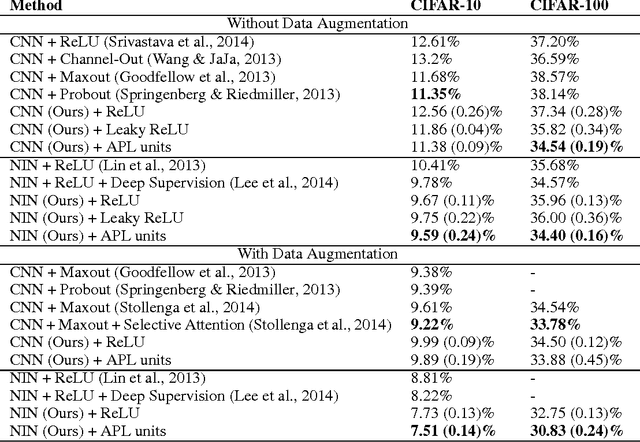

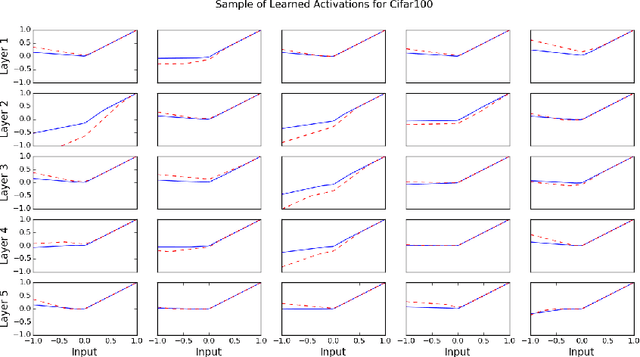
Artificial neural networks typically have a fixed, non-linear activation function at each neuron. We have designed a novel form of piecewise linear activation function that is learned independently for each neuron using gradient descent. With this adaptive activation function, we are able to improve upon deep neural network architectures composed of static rectified linear units, achieving state-of-the-art performance on CIFAR-10 (7.51%), CIFAR-100 (30.83%), and a benchmark from high-energy physics involving Higgs boson decay modes.