 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeta Process Non-negative Matrix Factorization with Stochastic Structured Mean-Field Variational Inference
Dec 02, 2014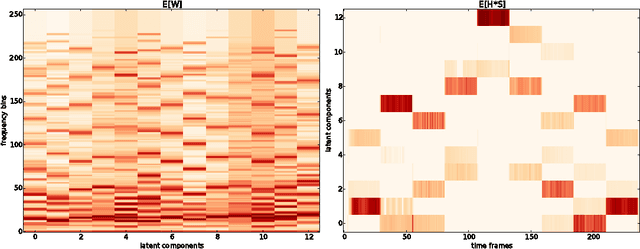

Beta process is the standard nonparametric Bayesian prior for latent factor model. In this paper, we derive a structured mean-field variational inference algorithm for a beta process non-negative matrix factorization (NMF) model with Poisson likelihood. Unlike the linear Gaussian model, which is well-studied in the nonparametric Bayesian literature, NMF model with beta process prior does not enjoy the conjugacy. We leverage the recently developed stochastic structured mean-field variational inference to relax the conjugacy constraint and restore the dependencies among the latent variables in the approximating variational distribution. Preliminary results on both synthetic and real examples demonstrate that the proposed inference algorithm can reasonably recover the hidden structure of the data.
Structured Stochastic Variational Inference
Nov 26, 2014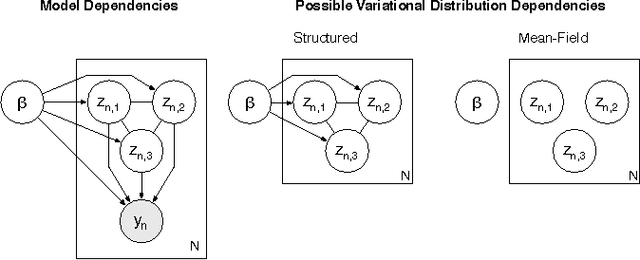
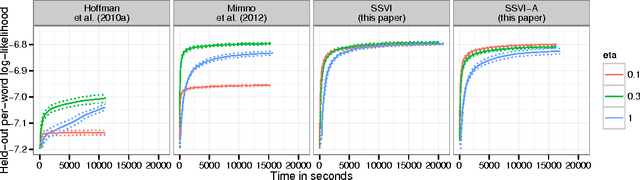
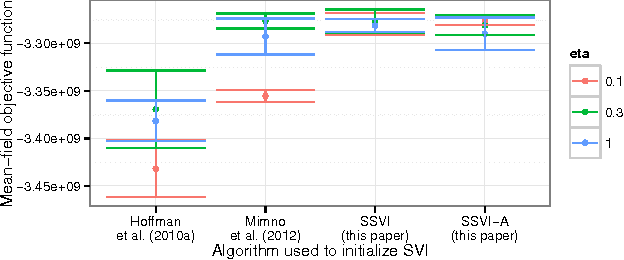
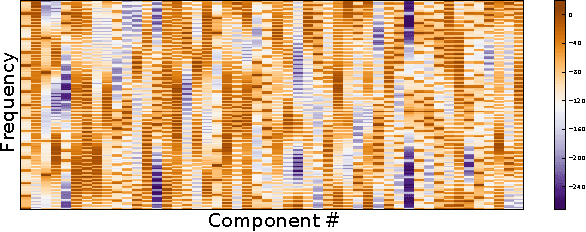
Stochastic variational inference makes it possible to approximate posterior distributions induced by large datasets quickly using stochastic optimization. The algorithm relies on the use of fully factorized variational distributions. However, this "mean-field" independence approximation limits the fidelity of the posterior approximation, and introduces local optima. We show how to relax the mean-field approximation to allow arbitrary dependencies between global parameters and local hidden variables, producing better parameter estimates by reducing bias, sensitivity to local optima, and sensitivity to hyperparameters.
A Generative Product-of-Filters Model of Audio
Nov 25, 2014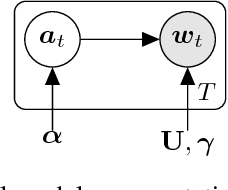
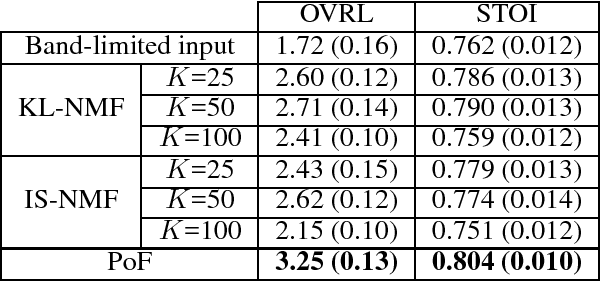
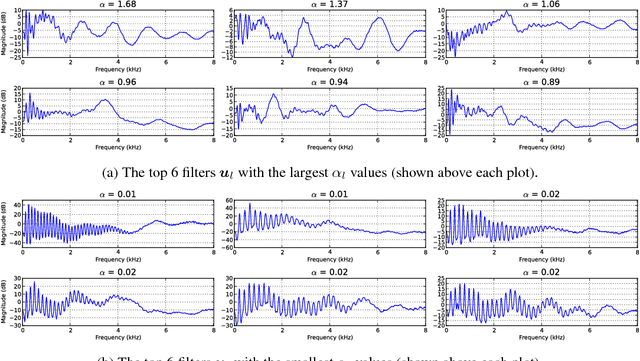

We propose the product-of-filters (PoF) model, a generative model that decomposes audio spectra as sparse linear combinations of "filters" in the log-spectral domain. PoF makes similar assumptions to those used in the classic homomorphic filtering approach to signal processing, but replaces hand-designed decompositions built of basic signal processing operations with a learned decomposition based on statistical inference. This paper formulates the PoF model and derives a mean-field method for posterior inference and a variational EM algorithm to estimate the model's free parameters. We demonstrate PoF's potential for audio processing on a bandwidth expansion task, and show that PoF can serve as an effective unsupervised feature extractor for a speaker identification task.
Image Classification and Retrieval from User-Supplied Tags
Nov 25, 2014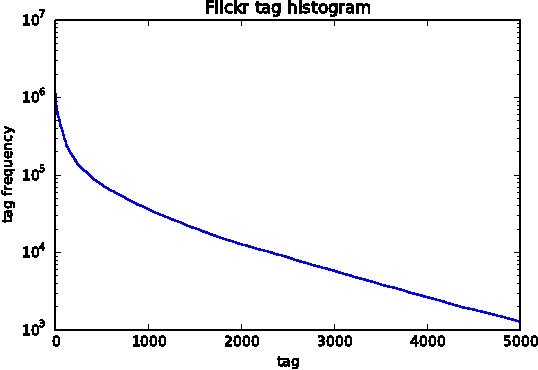
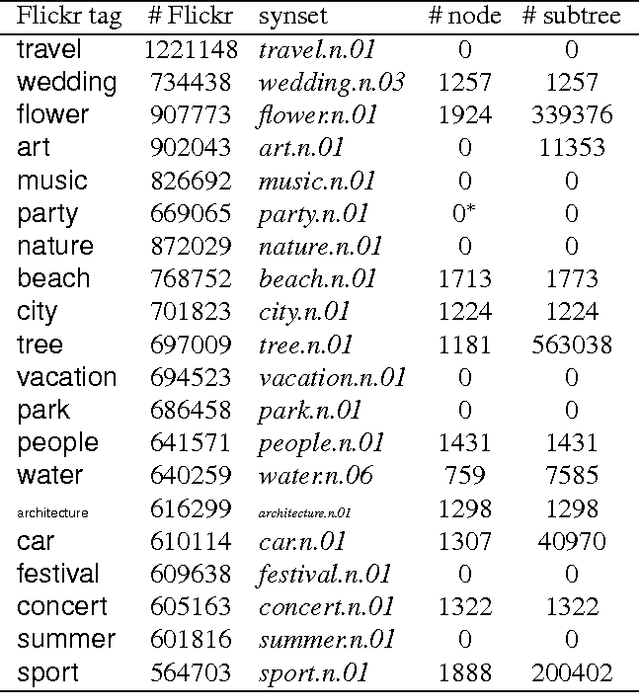
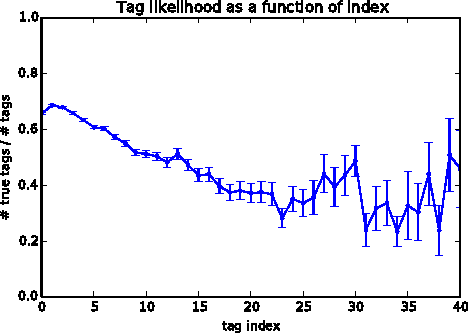
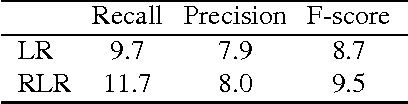
This paper proposes direct learning of image classification from user-supplied tags, without filtering. Each tag is supplied by the user who shared the image online. Enormous numbers of these tags are freely available online, and they give insight about the image categories important to users and to image classification. Our approach is complementary to the conventional approach of manual annotation, which is extremely costly. We analyze of the Flickr 100 Million Image dataset, making several useful observations about the statistics of these tags. We introduce a large-scale robust classification algorithm, in order to handle the inherent noise in these tags, and a calibration procedure to better predict objective annotations. We show that freely available, user-supplied tags can obtain similar or superior results to large databases of costly manual annotations.
The No-U-Turn Sampler: Adaptively Setting Path Lengths in Hamiltonian Monte Carlo
Nov 18, 2011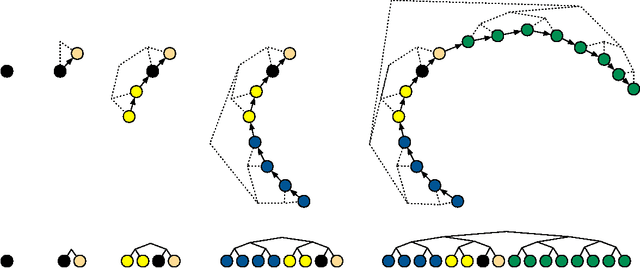
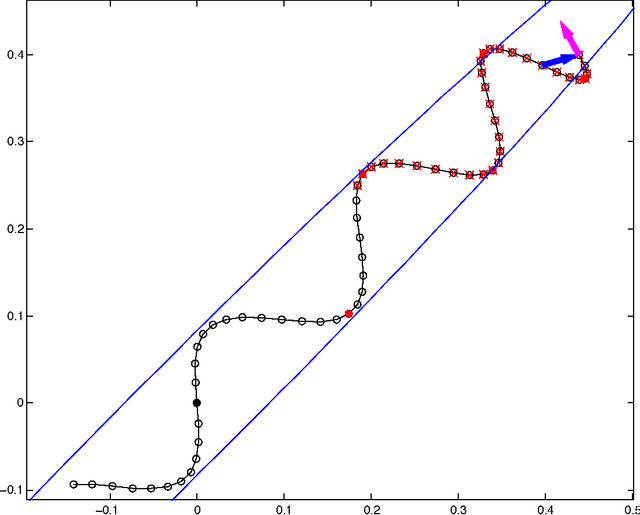
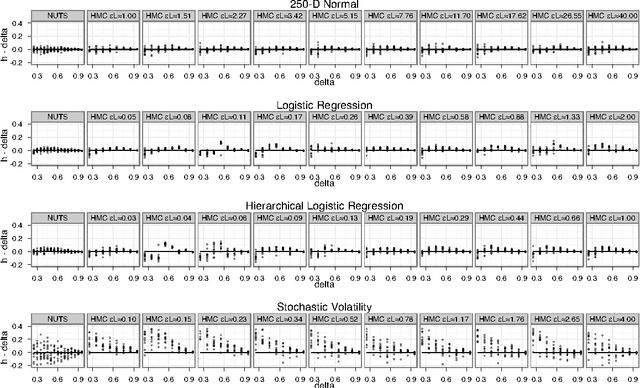
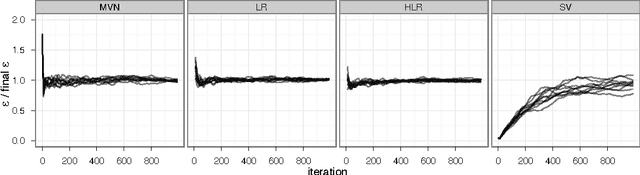
Hamiltonian Monte Carlo (HMC) is a Markov chain Monte Carlo (MCMC) algorithm that avoids the random walk behavior and sensitivity to correlated parameters that plague many MCMC methods by taking a series of steps informed by first-order gradient information. These features allow it to converge to high-dimensional target distributions much more quickly than simpler methods such as random walk Metropolis or Gibbs sampling. However, HMC's performance is highly sensitive to two user-specified parameters: a step size {\epsilon} and a desired number of steps L. In particular, if L is too small then the algorithm exhibits undesirable random walk behavior, while if L is too large the algorithm wastes computation. We introduce the No-U-Turn Sampler (NUTS), an extension to HMC that eliminates the need to set a number of steps L. NUTS uses a recursive algorithm to build a set of likely candidate points that spans a wide swath of the target distribution, stopping automatically when it starts to double back and retrace its steps. Empirically, NUTS perform at least as efficiently as and sometimes more efficiently than a well tuned standard HMC method, without requiring user intervention or costly tuning runs. We also derive a method for adapting the step size parameter {\epsilon} on the fly based on primal-dual averaging. NUTS can thus be used with no hand-tuning at all. NUTS is also suitable for applications such as BUGS-style automatic inference engines that require efficient "turnkey" sampling algorithms.
Approximate Maximum A Posteriori Inference with Entropic Priors
Sep 29, 2010In certain applications it is useful to fit multinomial distributions to observed data with a penalty term that encourages sparsity. For example, in probabilistic latent audio source decomposition one may wish to encode the assumption that only a few latent sources are active at any given time. The standard heuristic of applying an L1 penalty is not an option when fitting the parameters to a multinomial distribution, which are constrained to sum to 1. An alternative is to use a penalty term that encourages low-entropy solutions, which corresponds to maximum a posteriori (MAP) parameter estimation with an entropic prior. The lack of conjugacy between the entropic prior and the multinomial distribution complicates this approach. In this report I propose a simple iterative algorithm for MAP estimation of multinomial distributions with sparsity-inducing entropic priors.