 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDerandomized Novelty Detection with FDR Control via Conformal E-values
Feb 14, 2023



Conformal prediction and other randomized model-free inference techniques are gaining increasing attention as general solutions to rigorously calibrate the output of any machine learning algorithm for novelty detection. This paper contributes to the field by developing a novel method for mitigating their algorithmic randomness, leading to an even more interpretable and reliable framework for powerful novelty detection under false discovery rate control. The idea is to leverage suitable conformal e-values instead of p-values to quantify the significance of each finding, which allows the evidence gathered from multiple mutually dependent analyses of the same data to be seamlessly aggregated. Further, the proposed method can reduce randomness without much loss of power, partly thanks to an innovative way of weighting conformal e-values based on additional side information carefully extracted from the same data. Simulations with synthetic and real data confirm this solution can be effective at eliminating random noise in the inferences obtained with state-of-the-art alternative techniques, sometimes also leading to higher power.
Conformal inference is (almost) free for neural networks trained with early stopping
Jan 27, 2023Early stopping based on hold-out data is a popular regularization technique designed to mitigate overfitting and increase the predictive accuracy of neural networks. Models trained with early stopping often provide relatively accurate predictions, but they generally still lack precise statistical guarantees unless they are further calibrated using independent hold-out data. This paper addresses the above limitation with conformalized early stopping: a novel method that combines early stopping with conformal calibration while efficiently recycling the same hold-out data. This leads to models that are both accurate and able to provide exact predictive inferences without multiple data splits nor overly conservative adjustments. Practical implementations are developed for different learning tasks -- outlier detection, multi-class classification, regression -- and their competitive performance is demonstrated on real data.
Conformal Frequency Estimation with Sketched Data under Relaxed Exchangeability
Nov 09, 2022A flexible method is developed to construct a confidence interval for the frequency of a queried object in a very large data set, based on a much smaller sketch of the data. The approach requires no knowledge of the data distribution or of the details of the sketching algorithm; instead, it constructs provably valid frequentist confidence intervals for random queries using a conformal inference approach. After achieving marginal coverage for random queries under the assumption of data exchangeability, the proposed method is extended to provide stronger inferences accounting for possibly heterogeneous frequencies of different random queries, redundant queries, and distribution shifts. While the presented methods are broadly applicable, this paper focuses on use cases involving the count-min sketch algorithm and a non-linear variation thereof, to facilitate comparison to prior work. In particular, the developed methods are compared empirically to frequentist and Bayesian alternatives, through simulations and experiments with data sets of SARS-CoV-2 DNA sequences and classic English literature.
Bayesian nonparametric estimation of coverage probabilities and distinct counts from sketched data
Sep 05, 2022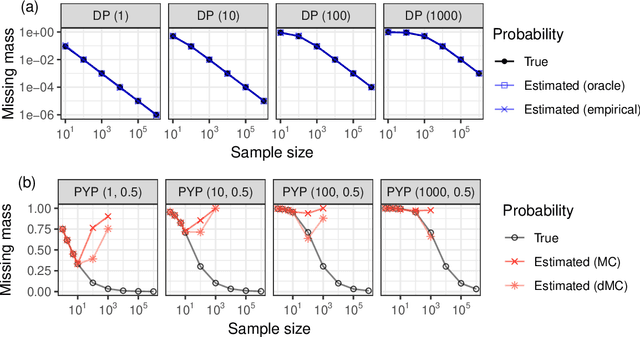
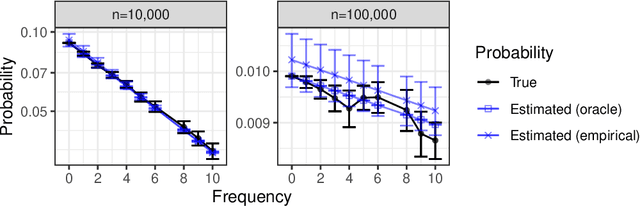
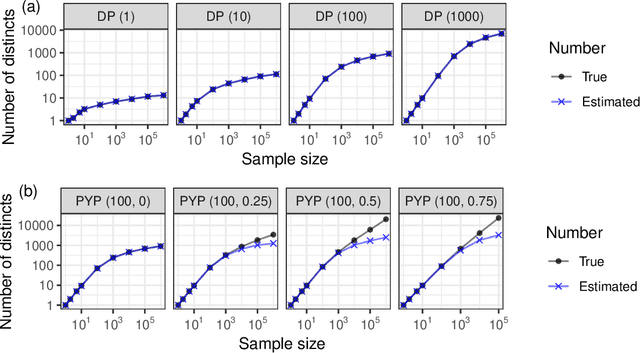
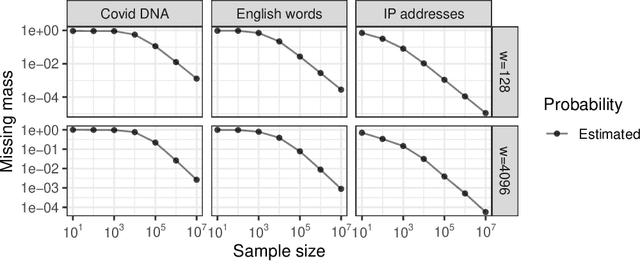
The estimation of coverage probabilities, and in particular of the missing mass, is a classical statistical problem with applications in numerous scientific fields. In this paper, we study this problem in relation to randomized data compression, or sketching. This is a novel but practically relevant perspective, and it refers to situations in which coverage probabilities must be estimated based on a compressed and imperfect summary, or sketch, of the true data, because neither the full data nor the empirical frequencies of distinct symbols can be observed directly. Our contribution is a Bayesian nonparametric methodology to estimate coverage probabilities from data sketched through random hashing, which also solves the challenging problems of recovering the numbers of distinct counts in the true data and of distinct counts with a specified empirical frequency of interest. The proposed Bayesian estimators are shown to be easily applicable to large-scale analyses in combination with a Dirichlet process prior, although they involve some open computational challenges under the more general Pitman-Yor process prior. The empirical effectiveness of our methodology is demonstrated through numerical experiments and applications to real data sets of Covid DNA sequences, classic English literature, and IP addresses.
Integrative conformal p-values for powerful out-of-distribution testing with labeled outliers
Aug 23, 2022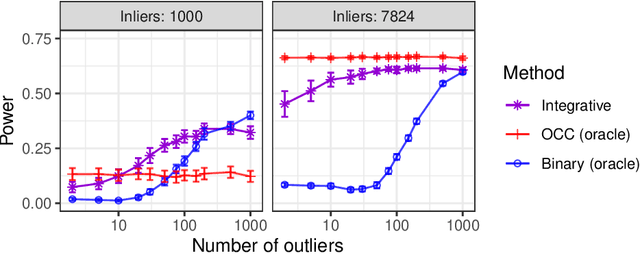
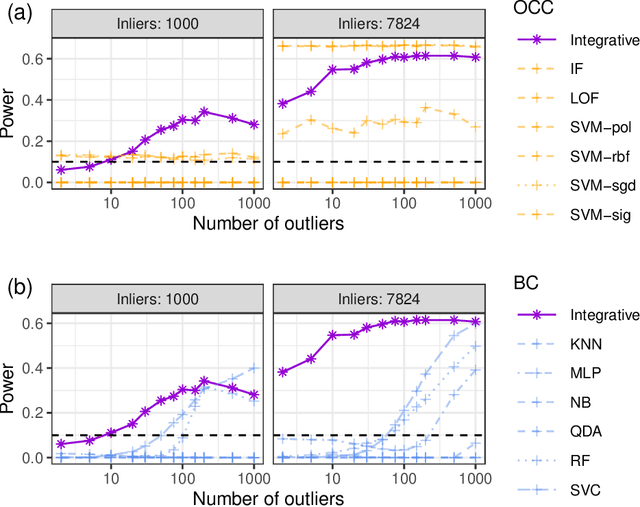
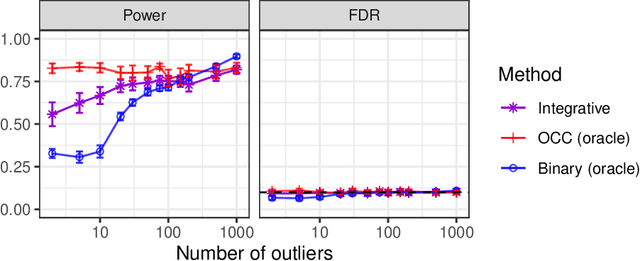
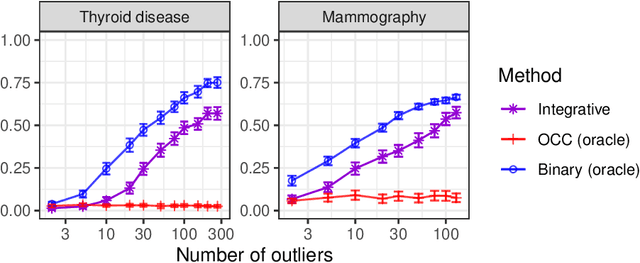
This paper develops novel conformal methods to test whether a new observation was sampled from the same distribution as a reference set. Blending inductive and transductive conformal inference in an innovative way, the described methods can re-weight standard conformal p-values based on dependent side information from known out-of-distribution data in a principled way, and can automatically take advantage of the most powerful model from any collection of one-class and binary classifiers. The solution can be implemented either through sample splitting or via a novel transductive cross-validation+ scheme which may also be useful in other applications of conformal inference, due to tighter guarantees compared to existing cross-validation approaches. After studying false discovery rate control and power within a multiple testing framework with several possible outliers, the proposed solution is shown to outperform standard conformal p-values through simulations as well as applications to image recognition and tabular data.
Coordinated Double Machine Learning
Jun 02, 2022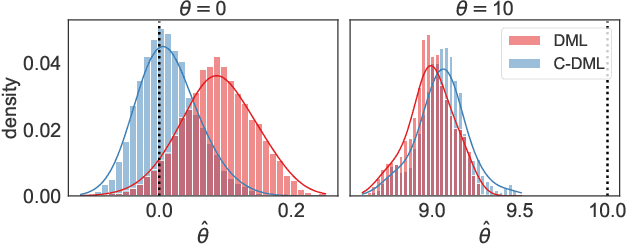
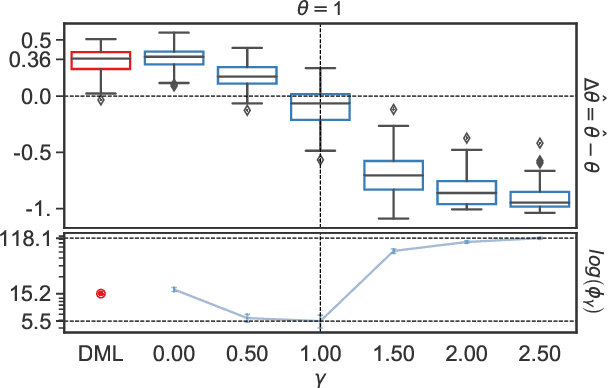
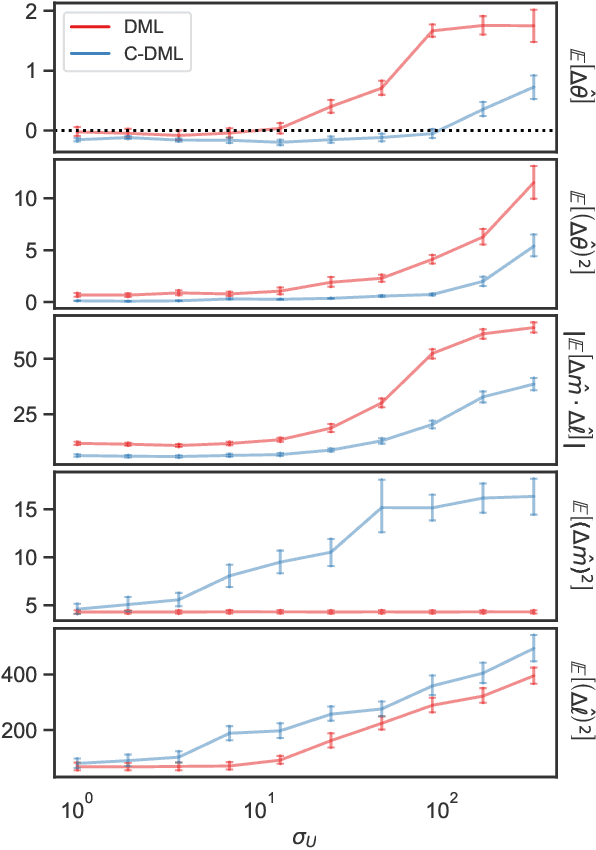
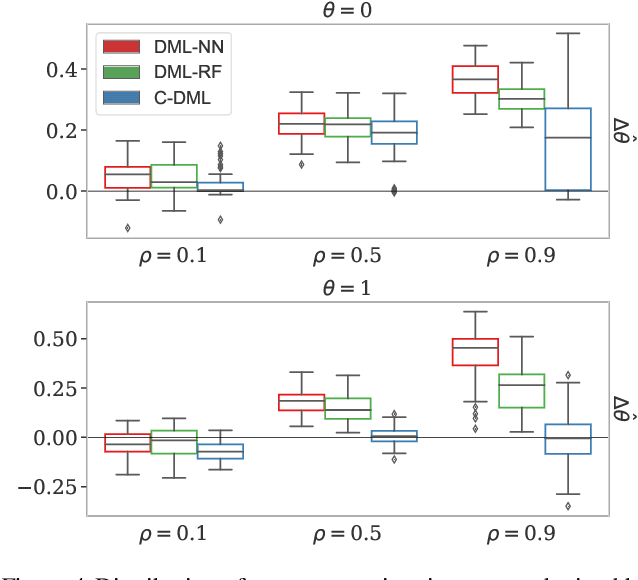
Double machine learning is a statistical method for leveraging complex black-box models to construct approximately unbiased treatment effect estimates given observational data with high-dimensional covariates, under the assumption of a partially linear model. The idea is to first fit on a subset of the samples two non-linear predictive models, one for the continuous outcome of interest and one for the observed treatment, and then to estimate a linear coefficient for the treatment using the remaining samples through a simple orthogonalized regression. While this methodology is flexible and can accommodate arbitrary predictive models, typically trained independently of one another, this paper argues that a carefully coordinated learning algorithm for deep neural networks may reduce the estimation bias. The improved empirical performance of the proposed method is demonstrated through numerical experiments on both simulated and real data.
Training Uncertainty-Aware Classifiers with Conformalized Deep Learning
May 12, 2022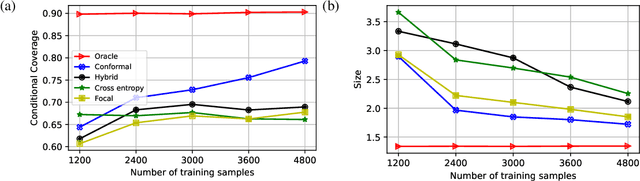
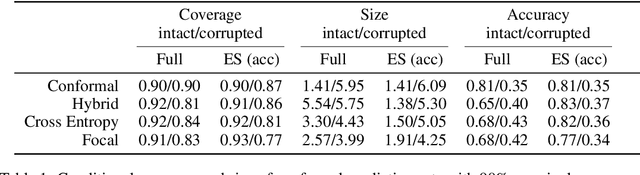

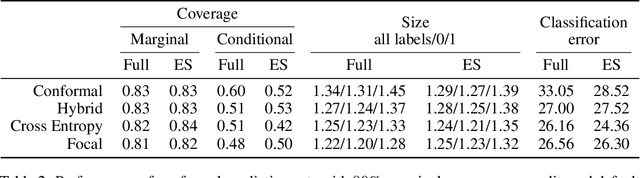
Deep neural networks are powerful tools to detect hidden patterns in data and leverage them to make predictions, but they are not designed to understand uncertainty and estimate reliable probabilities. In particular, they tend to be overconfident. We address this problem by developing a novel training algorithm that can lead to more dependable uncertainty estimates, without sacrificing predictive power. The idea is to mitigate overconfidence by minimizing a loss function, inspired by advances in conformal inference, that quantifies model uncertainty by carefully leveraging hold-out data. Experiments with synthetic and real data demonstrate this method leads to smaller conformal prediction sets with higher conditional coverage, after exact calibration with hold-out data, compared to state-of-the-art alternatives.
Conformalized Frequency Estimation from Sketched Data
Apr 08, 2022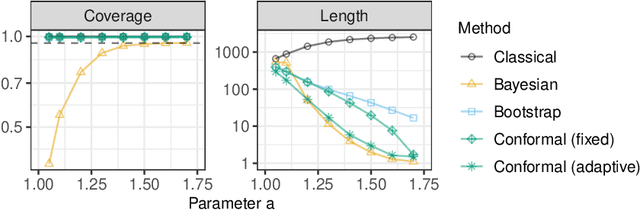
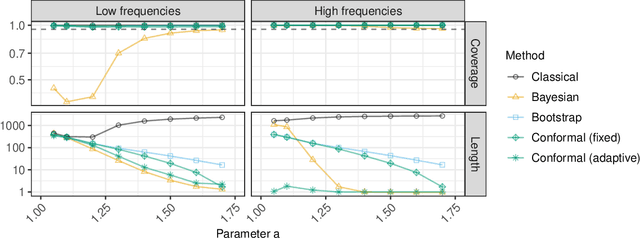
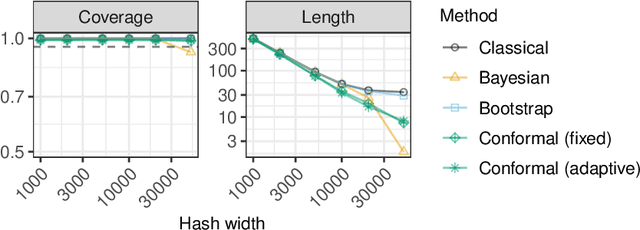
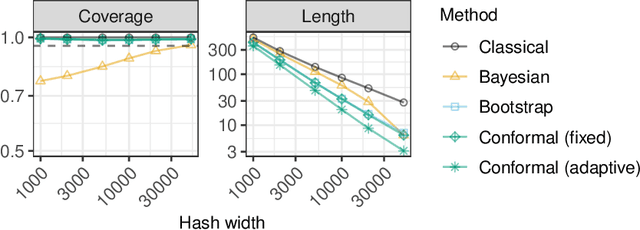
A flexible conformal inference method is developed to construct confidence intervals for the frequencies of queried objects in a very large data set, based on the information contained in a much smaller sketch of those data. The approach is completely data-adaptive and makes no use of any knowledge of the population distribution or of the inner workings of the sketching algorithm; instead, it constructs provably valid frequentist confidence intervals under the sole assumption of data exchangeability. Although the proposed solution is much more broadly applicable, this paper explicitly demonstrates its use in combination with the famous count-min sketch algorithm and a non-linear variation thereof to facilitate the exposition. The performance is compared to that of existing frequentist and Bayesian alternatives through several experiments with synthetic data as well as with real data sets consisting of SARS-CoV-2 DNA sequences and classic English literature.
Conformal histogram regression
May 18, 2021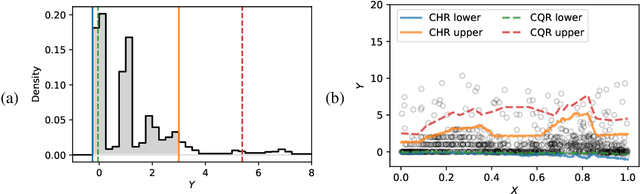
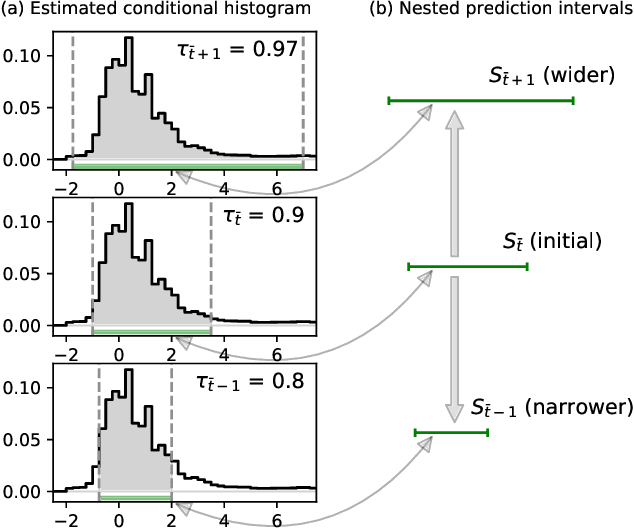
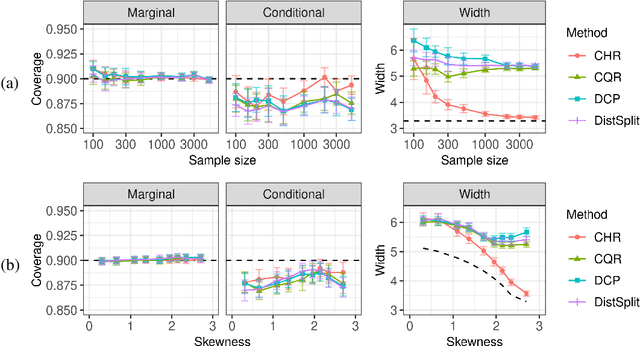
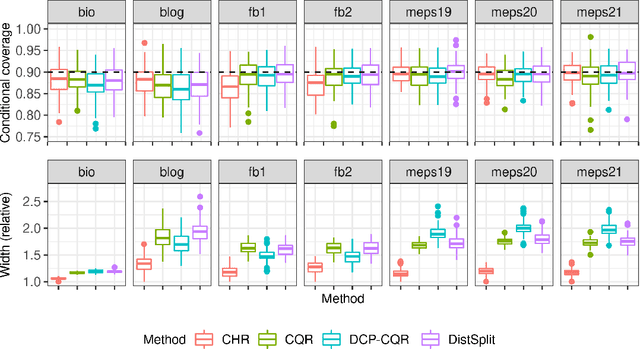
This paper develops a conformal method to compute prediction intervals for non-parametric regression that can automatically adapt to skewed data. Leveraging black-box machine learning algorithms to estimate the conditional distribution of the outcome using histograms, it translates their output into the shortest prediction intervals with approximate conditional coverage. The resulting prediction intervals provably have marginal coverage in finite samples, while asymptotically achieving conditional coverage and optimal length if the black-box model is consistent. Numerical experiments with simulated and real data demonstrate improved performance compared to state-of-the-art alternatives, including conformalized quantile regression and other distributional conformal prediction approaches.
Testing for Outliers with Conformal p-values
Apr 19, 2021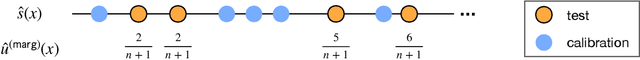

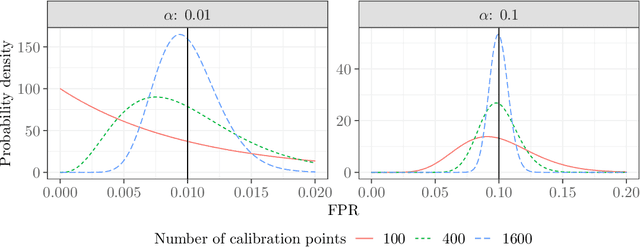
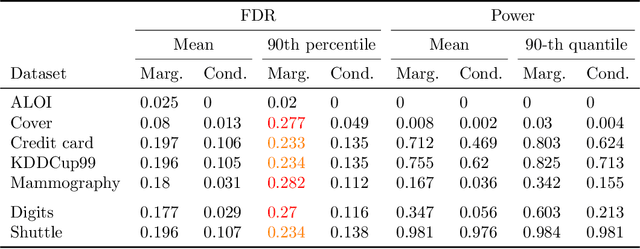
This paper studies the construction of p-values for nonparametric outlier detection, taking a multiple-testing perspective. The goal is to test whether new independent samples belong to the same distribution as a reference data set or are outliers. We propose a solution based on conformal inference, a broadly applicable framework which yields p-values that are marginally valid but mutually dependent for different test points. We prove these p-values are positively dependent and enable exact false discovery rate control, although in a relatively weak marginal sense. We then introduce a new method to compute p-values that are both valid conditionally on the training data and independent of each other for different test points; this paves the way to stronger type-I error guarantees. Our results depart from classical conformal inference as we leverage concentration inequalities rather than combinatorial arguments to establish our finite-sample guarantees. Furthermore, our techniques also yield a uniform confidence bound for the false positive rate of any outlier detection algorithm, as a function of the threshold applied to its raw statistics. Finally, the relevance of our results is demonstrated by numerical experiments on real and simulated data.