 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent-space Field Tension for Astrophysical Component Detection An application to X-ray imaging
Jun 25, 2025Modern observatories are designed to deliver increasingly detailed views of astrophysical signals. To fully realize the potential of these observations, principled data-analysis methods are required to effectively separate and reconstruct the underlying astrophysical components from data corrupted by noise and instrumental effects. In this work, we introduce a novel multi-frequency Bayesian model of the sky emission field that leverages latent-space tension as an indicator of model misspecification, enabling automated separation of diffuse, point-like, and extended astrophysical emission components across wavelength bands. Deviations from latent-space prior expectations are used as diagnostics for model misspecification, thus systematically guiding the introduction of new sky components, such as point-like and extended sources. We demonstrate the effectiveness of this method on synthetic multi-frequency imaging data and apply it to observational X-ray data from the eROSITA Early Data Release (EDR) of the SN1987A region in the Large Magellanic Cloud (LMC). Our results highlight the method's capability to reconstruct astrophysical components with high accuracy, achieving sub-pixel localization of point sources, robust separation of extended emission, and detailed uncertainty quantification. The developed methodology offers a general and well-founded framework applicable to a wide variety of astronomical datasets, and is therefore well suited to support the analysis needs of next-generation multi-wavelength and multi-messenger surveys.
Re-Envisioning Numerical Information Field Theory (NIFTy.re): A Library for Gaussian Processes and Variational Inference
Feb 26, 2024Imaging is the process of transforming noisy, incomplete data into a space that humans can interpret. NIFTy is a Bayesian framework for imaging and has already successfully been applied to many fields in astrophysics. Previous design decisions held the performance and the development of methods in NIFTy back. We present a rewrite of NIFTy, coined NIFTy.re, which reworks the modeling principle, extends the inference strategies, and outsources much of the heavy lifting to JAX. The rewrite dramatically accelerates models written in NIFTy, lays the foundation for new types of inference machineries, improves maintainability, and enables interoperability between NIFTy and the JAX machine learning ecosystem.
Non-parametric Bayesian Causal Modeling of the SARS-CoV-2 Viral Load Distribution vs. Patient's Age
May 27, 2021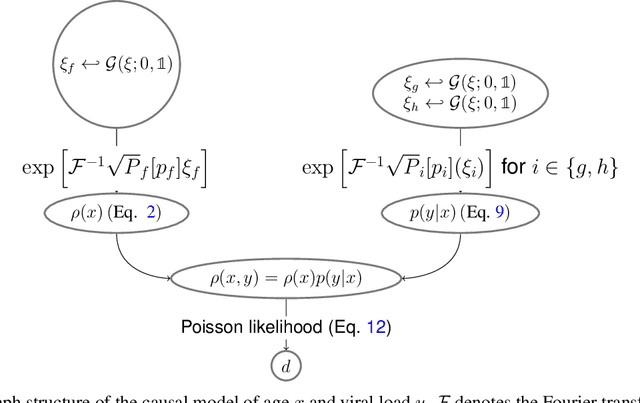
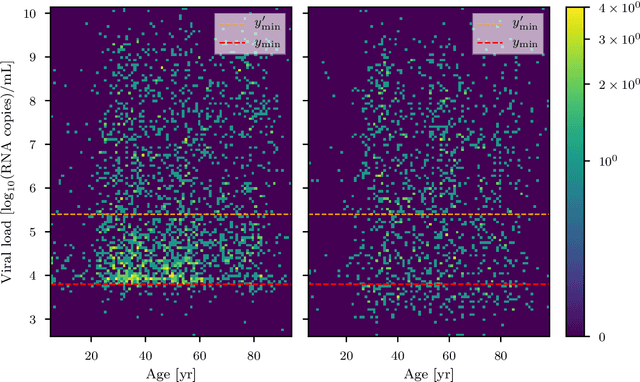
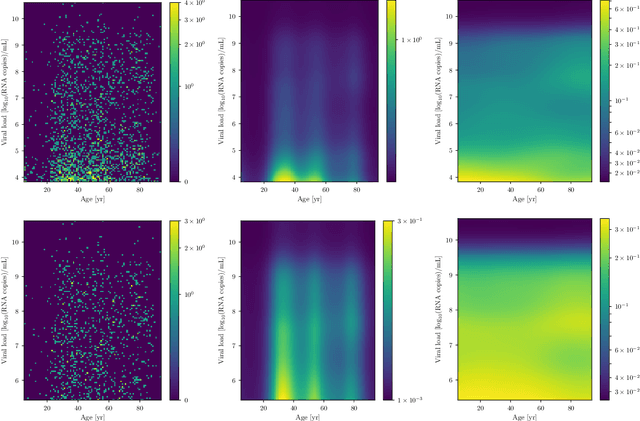
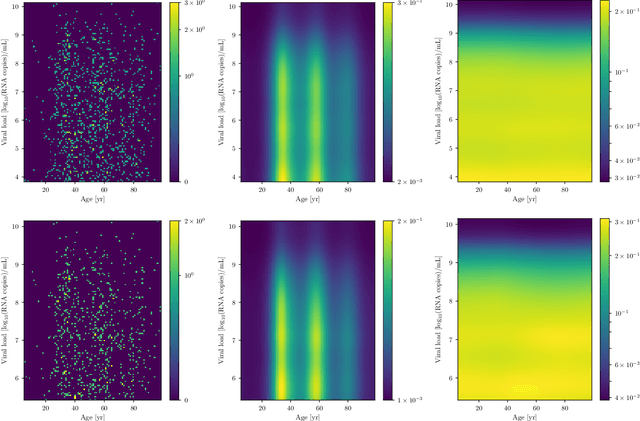
The viral load of patients infected with SARS-CoV-2 varies on logarithmic scales and possibly with age. Controversial claims have been made in the literature regarding whether the viral load distribution actually depends on the age of the patients. Such a dependence would have implications for the COVID-19 spreading mechanism, the age-dependent immune system reaction, and thus for policymaking. We hereby develop a method to analyze viral-load distribution data as a function of the patients' age within a flexible, non-parametric, hierarchical, Bayesian, and causal model. This method can be applied to other contexts as well, and for this purpose, it is made freely available. The developed reconstruction method also allows testing for bias in the data. This could be due to, e.g., bias in patient-testing and data collection or systematic errors in the measurement of the viral load. We perform these tests by calculating the Bayesian evidence for each implied possible causal direction. When applying these tests to publicly available age and SARS-CoV-2 viral load data, we find a statistically significant increase in the viral load with age, but only for one of the two analyzed datasets. If we consider this dataset, and based on the current understanding of viral load's impact on patients' infectivity, we expect a non-negligible difference in the infectivity of different age groups. This difference is nonetheless too small to justify considering any age group as noninfectious.