 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe VVAD-LRS3 Dataset for Visual Voice Activity Detection
Sep 28, 2021
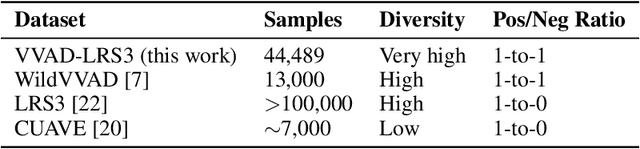


Robots are becoming everyday devices, increasing their interaction with humans. To make human-machine interaction more natural, cognitive features like Visual Voice Activity Detection (VVAD), which can detect whether a person is speaking or not, given visual input of a camera, need to be implemented. Neural networks are state of the art for tasks in Image Processing, Time Series Prediction, Natural Language Processing and other domains. Those Networks require large quantities of labeled data. Currently there are not many datasets for the task of VVAD. In this work we created a large scale dataset called the VVAD-LRS3 dataset, derived by automatic annotations from the LRS3 dataset. The VVAD-LRS3 dataset contains over 44K samples, over three times the next competitive dataset (WildVVAD). We evaluate different baselines on four kinds of features: facial and lip images, and facial and lip landmark features. With a Convolutional Neural Network Long Short Term Memory (CNN LSTM) on facial images an accuracy of 92% was reached on the test set. A study with humans showed that they reach an accuracy of 87.93% on the test set.
Teaching Uncertainty Quantification in Machine Learning through Use Cases
Aug 19, 2021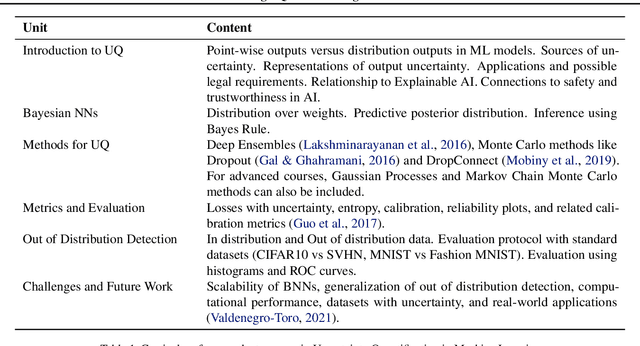
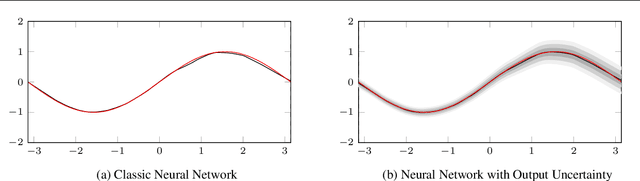
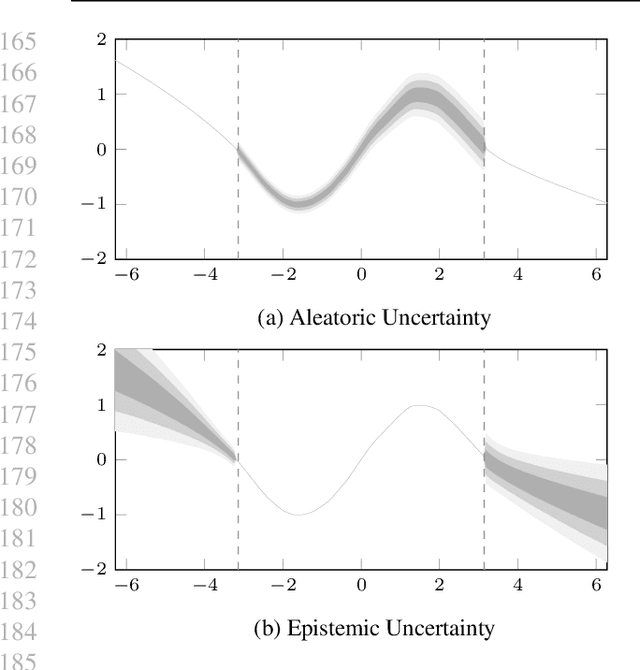
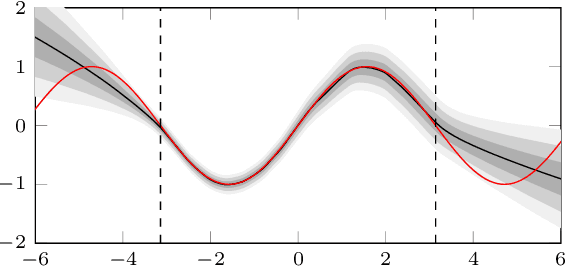
Uncertainty in machine learning is not generally taught as general knowledge in Machine Learning course curricula. In this paper we propose a short curriculum for a course about uncertainty in machine learning, and complement the course with a selection of use cases, aimed to trigger discussion and let students play with the concepts of uncertainty in a programming setting. Our use cases cover the concept of output uncertainty, Bayesian neural networks and weight distributions, sources of uncertainty, and out of distribution detection. We expect that this curriculum and set of use cases motivates the community to adopt these important concepts into courses for safety in AI.
The Marine Debris Dataset for Forward-Looking Sonar Semantic Segmentation
Aug 15, 2021


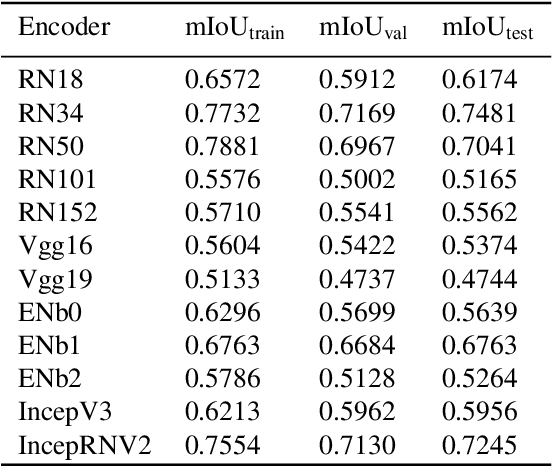
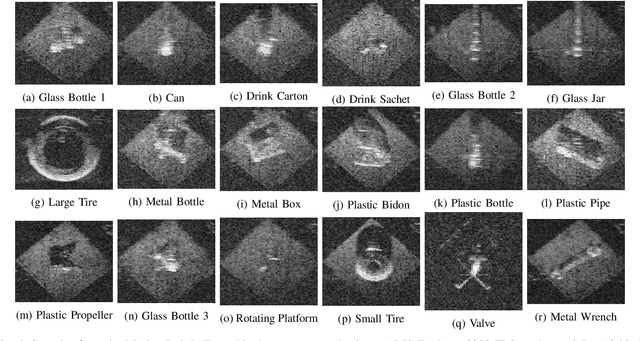
Accurate detection and segmentation of marine debris is important for keeping the water bodies clean. This paper presents a novel dataset for marine debris segmentation collected using a Forward Looking Sonar (FLS). The dataset consists of 1868 FLS images captured using ARIS Explorer 3000 sensor. The objects used to produce this dataset contain typical house-hold marine debris and distractor marine objects (tires, hooks, valves,etc), divided in 11 classes plus a background class. Performance of state of the art semantic segmentation architectures with a variety of encoders have been analyzed on this dataset and presented as baseline results. Since the images are grayscale, no pretrained weights have been used. Comparisons are made using Intersection over Union (IoU). The best performing model is Unet with ResNet34 backbone at 0.7481 mIoU. The dataset is available at https://github.com/mvaldenegro/marine-debris-fls-datasets/
Deep Reinforcement Learning for Continuous Docking Control of Autonomous Underwater Vehicles: A Benchmarking Study
Aug 05, 2021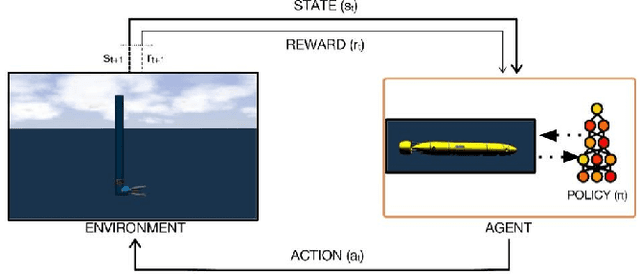
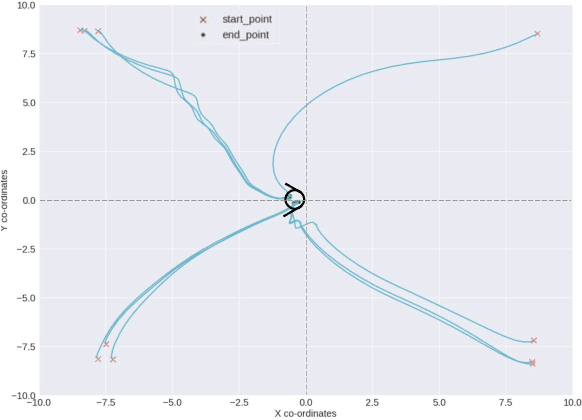
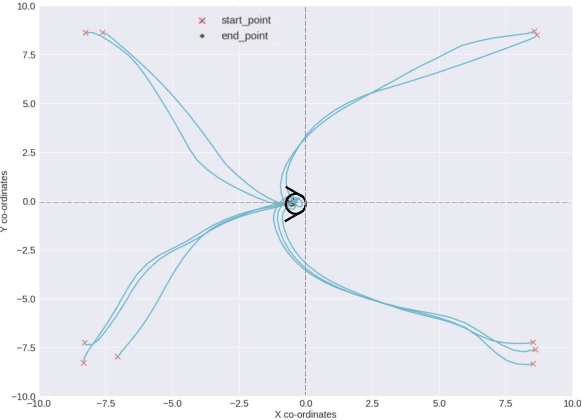
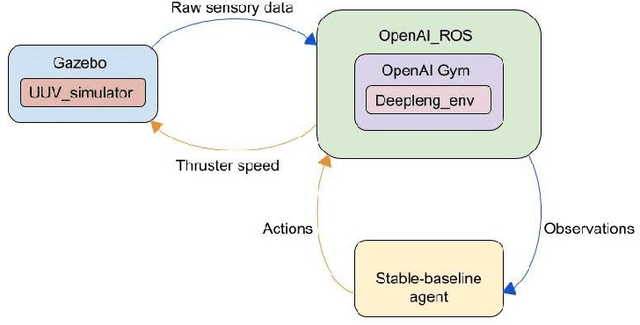
Docking control of an autonomous underwater vehicle (AUV) is a task that is integral to achieving persistent long term autonomy. This work explores the application of state-of-the-art model-free deep reinforcement learning (DRL) approaches to the task of AUV docking in the continuous domain. We provide a detailed formulation of the reward function, utilized to successfully dock the AUV onto a fixed docking platform. A major contribution that distinguishes our work from the previous approaches is the usage of a physics simulator to define and simulate the underwater environment as well as the DeepLeng AUV. We propose a new reward function formulation for the docking task, incorporating several components, that outperforms previous reward formulations. We evaluate proximal policy optimization (PPO), twin delayed deep deterministic policy gradients (TD3) and soft actor-critic (SAC) in combination with our reward function. Our evaluation yielded results that conclusively show the TD3 agent to be most efficient and consistent in terms of docking the AUV, over multiple evaluation runs it achieved a 100% success rate and episode return of 10667.1 +- 688.8. We also show how our reward function formulation improves over the state of the art.
Pre-trained Models for Sonar Images
Aug 02, 2021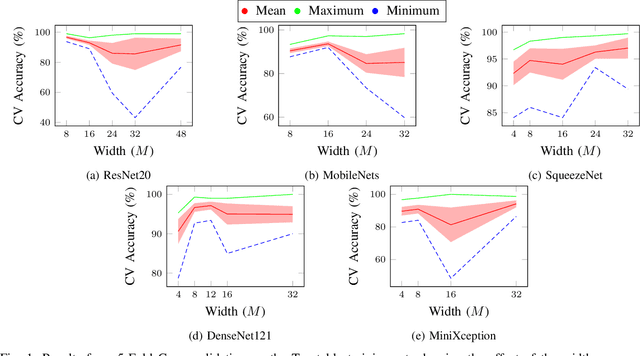
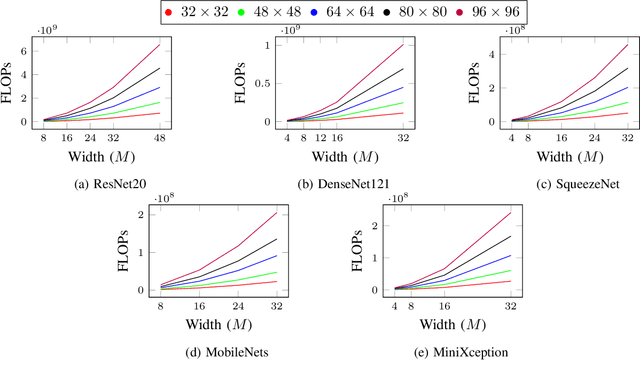

Machine learning and neural networks are now ubiquitous in sonar perception, but it lags behind the computer vision field due to the lack of data and pre-trained models specifically for sonar images. In this paper we present the Marine Debris Turntable dataset and produce pre-trained neural networks trained on this dataset, meant to fill the gap of missing pre-trained models for sonar images. We train Resnet 20, MobileNets, DenseNet121, SqueezeNet, MiniXception, and an Autoencoder, over several input image sizes, from 32 x 32 to 96 x 96, on the Marine Debris turntable dataset. We evaluate these models using transfer learning for low-shot classification in the Marine Debris Watertank and another dataset captured using a Gemini 720i sonar. Our results show that in both datasets the pre-trained models produce good features that allow good classification accuracy with low samples (10-30 samples per class). The Gemini dataset validates that the features transfer to other kinds of sonar sensors. We expect that the community benefits from the public release of our pre-trained models and the turntable dataset.
Forward-Looking Sonar Patch Matching: Modern CNNs, Ensembling, and Uncertainty
Aug 02, 2021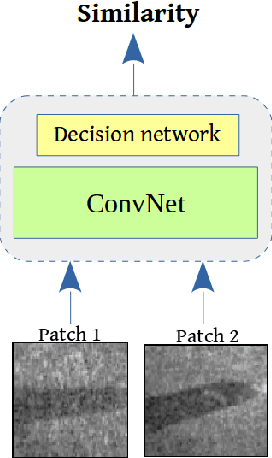
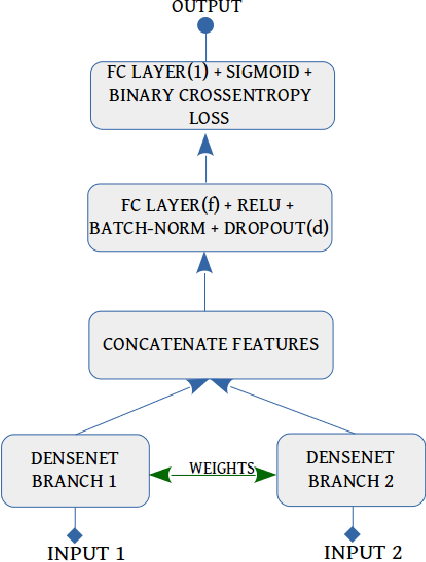
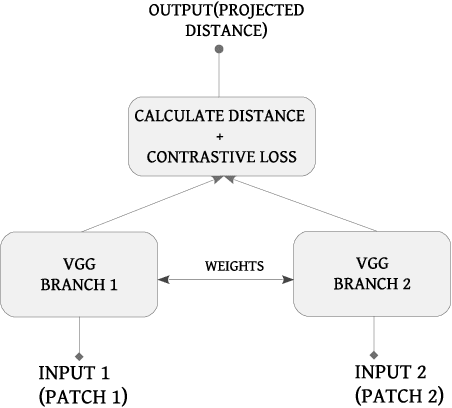
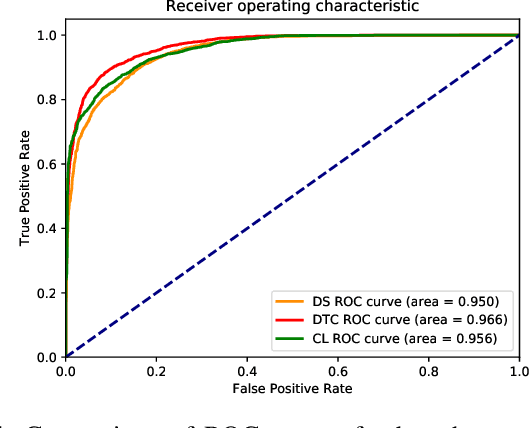
Application of underwater robots are on the rise, most of them are dependent on sonar for underwater vision, but the lack of strong perception capabilities limits them in this task. An important issue in sonar perception is matching image patches, which can enable other techniques like localization, change detection, and mapping. There is a rich literature for this problem in color images, but for acoustic images, it is lacking, due to the physics that produce these images. In this paper we improve on our previous results for this problem (Valdenegro-Toro et al, 2017), instead of modeling features manually, a Convolutional Neural Network (CNN) learns a similarity function and predicts if two input sonar images are similar or not. With the objective of improving the sonar image matching problem further, three state of the art CNN architectures are evaluated on the Marine Debris dataset, namely DenseNet, and VGG, with a siamese or two-channel architecture, and contrastive loss. To ensure a fair evaluation of each network, thorough hyper-parameter optimization is executed. We find that the best performing models are DenseNet Two-Channel network with 0.955 AUC, VGG-Siamese with contrastive loss at 0.949 AUC and DenseNet Siamese with 0.921 AUC. By ensembling the top performing DenseNet two-channel and DenseNet-Siamese models overall highest prediction accuracy obtained is 0.978 AUC, showing a large improvement over the 0.91 AUC in the state of the art.
I Find Your Lack of Uncertainty in Computer Vision Disturbing
Apr 16, 2021
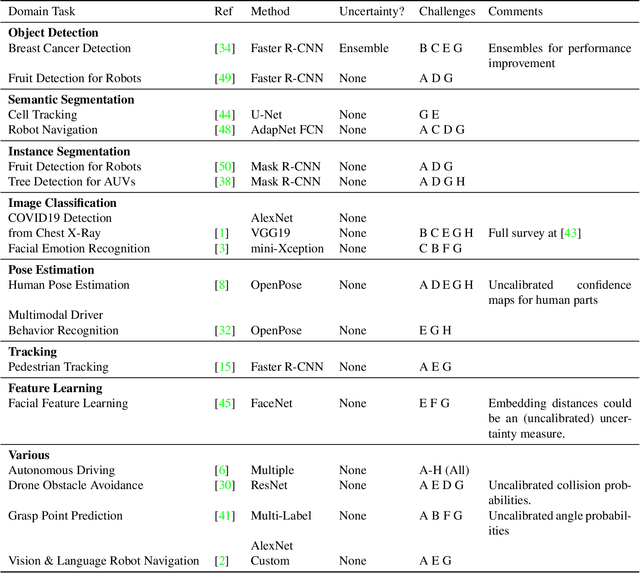
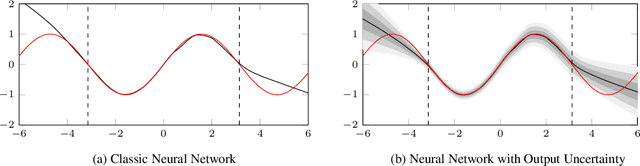
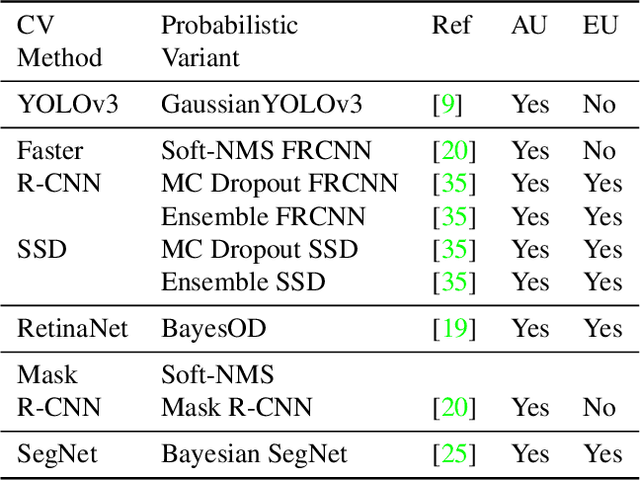
Neural networks are used for many real world applications, but often they have problems estimating their own confidence. This is particularly problematic for computer vision applications aimed at making high stakes decisions with humans and their lives. In this paper we make a meta-analysis of the literature, showing that most if not all computer vision applications do not use proper epistemic uncertainty quantification, which means that these models ignore their own limitations. We describe the consequences of using models without proper uncertainty quantification, and motivate the community to adopt versions of the models they use that have proper calibrated epistemic uncertainty, in order to enable out of distribution detection. We close the paper with a summary of challenges on estimating uncertainty for computer vision applications and recommendations.
Are Gradient-based Saliency Maps Useful in Deep Reinforcement Learning?
Dec 02, 2020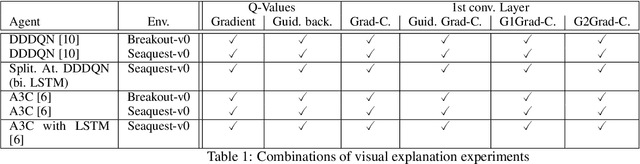


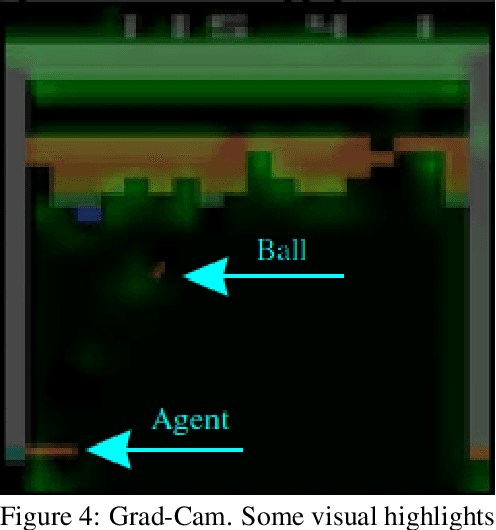
Deep Reinforcement Learning (DRL) connects the classic Reinforcement Learning algorithms with Deep Neural Networks. A problem in DRL is that CNNs are black-boxes and it is hard to understand the decision-making process of agents. In order to be able to use RL agents in highly dangerous environments for humans and machines, the developer needs a debugging tool to assure that the agent does what is expected. Currently, rewards are primarily used to interpret how well an agent is learning. However, this can lead to deceptive conclusions if the agent receives more rewards by memorizing a policy and not learning to respond to the environment. In this work, it is shown that this problem can be recognized with the help of gradient visualization techniques. This work brings some of the best-known visualization methods from the field of image classification to the area of Deep Reinforcement Learning. Furthermore, two new visualization techniques have been developed, one of which provides particularly good results. It is being proven to what extent the algorithms can be used in the area of Reinforcement learning. Also, the question arises on how well the DRL algorithms can be visualized across different environments with varying visualization techniques.
Unsupervised Difficulty Estimation with Action Scores
Nov 23, 2020



Evaluating difficulty and biases in machine learning models has become of extreme importance as current models are now being applied in real-world situations. In this paper we present a simple method for calculating a difficulty score based on the accumulation of losses for each sample during training. We call this the action score. Our proposed method does not require any modification of the model neither any external supervision, as it can be implemented as callback that gathers information from the training process. We test and analyze our approach in two different settings: image classification, and object detection, and we show that in both settings the action score can provide insights about model and dataset biases.
Automatic Detection and Classification of Tick-borne Skin Lesions using Deep Learning
Nov 23, 2020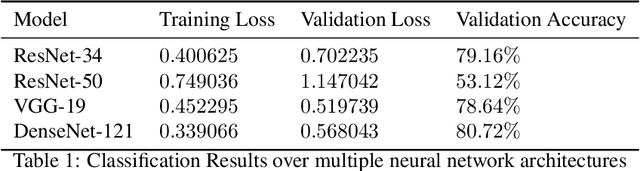
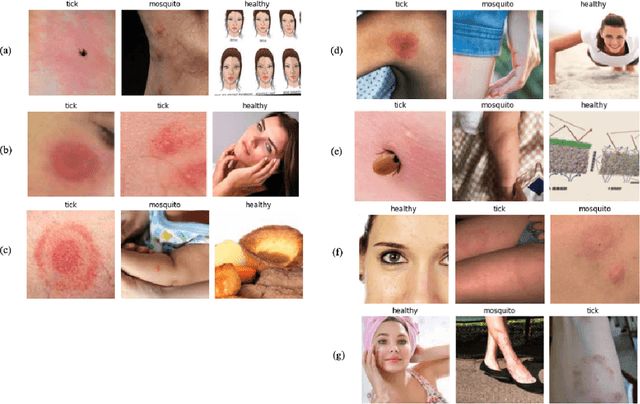
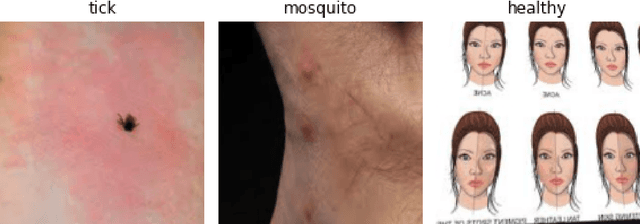

Around the globe, ticks are the culprit of transmitting a variety of bacterial, viral and parasitic diseases. The incidence of tick-borne diseases has drastically increased within the last decade, with annual cases of Lyme disease soaring to an estimated 300,000 in the United States alone. As a result, more efforts in improving lesion identification approaches and diagnostics for tick-borne illnesses is critical. The objective for this study is to build upon the approach used by Burlina et al. by using a variety of convolutional neural network models to detect tick-borne skin lesions. We expanded the data inputs by acquiring images from Google in seven different languages to test if this would diversify training data and improve the accuracy of skin lesion detection. The final dataset included nearly 6,080 images and was trained on a combination of architectures (ResNet 34, ResNet 50, VGG 19, and Dense Net 121). We obtained an accuracy of 80.72% with our model trained on the DenseNet 121 architecture.