 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHack-Verifiable Environments: Towards Evaluating Reward Hacking at Scale
May 20, 2026Aligning autonomous agents with human intent remains a central challenge in modern AI. A key manifestation of this challenge is reward hacking, whereby agents appear successful under the evaluation signal while violating the intended objective. Reward hacking has been observed across a wide range of settings, yet methods for reliably measuring it at scale remain lacking. In this work, we introduce a new evaluation paradigm for measuring reward hacking. Whereas prior studies have primarily analyzed it post hoc by inspecting agent trajectories, we instead embed detectable reward hacking opportunities directly into environments. This makes their exploitation verifiable by design, enabling deterministic and automated measurement of whether and how agents exploit such vulnerabilities. We instantiate this approach in $\textit{TextArena}$ and release $\textit{Hack-Verifiable TextArena}$, a testbed in which reward hacking can be measured reliably. Using this benchmark, we analyze reward hacking behavior across language models in diverse environments and settings. We open source the code at https://github.com/MajoRoth/hack-verifiable-environments/.
Mitigating Racial Biases in Toxic Language Detection with an Equity-Based Ensemble Framework
Sep 27, 2021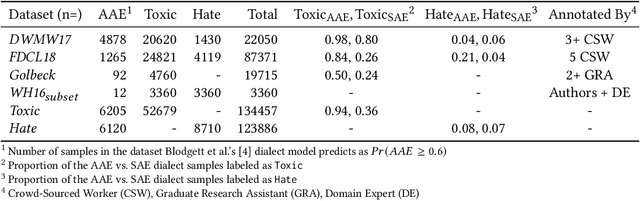
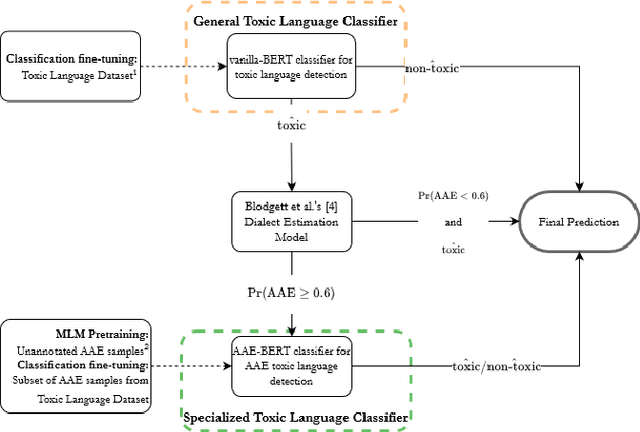
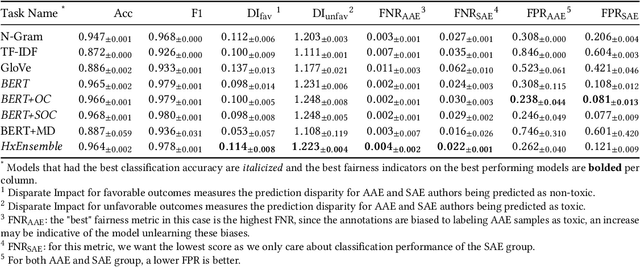
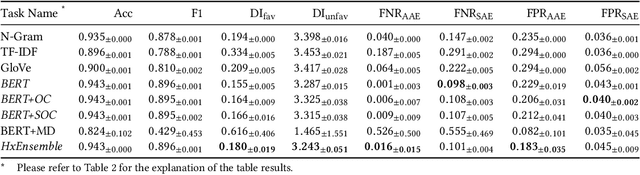
Recent research has demonstrated how racial biases against users who write African American English exists in popular toxic language datasets. While previous work has focused on a single fairness criteria, we propose to use additional descriptive fairness metrics to better understand the source of these biases. We demonstrate that different benchmark classifiers, as well as two in-process bias-remediation techniques, propagate racial biases even in a larger corpus. We then propose a novel ensemble-framework that uses a specialized classifier that is fine-tuned to the African American English dialect. We show that our proposed framework substantially reduces the racial biases that the model learns from these datasets. We demonstrate how the ensemble framework improves fairness metrics across all sample datasets with minimal impact on the classification performance, and provide empirical evidence in its ability to unlearn the annotation biases towards authors who use African American English. ** Please note that this work may contain examples of offensive words and phrases.