 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsk the Right Questions: Active Question Reformulation with Reinforcement Learning
Mar 02, 2018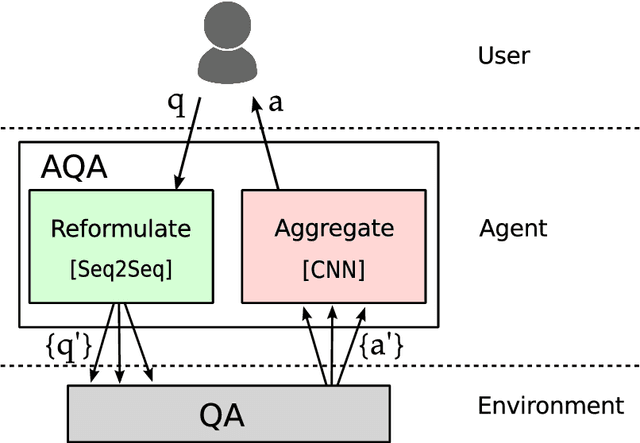
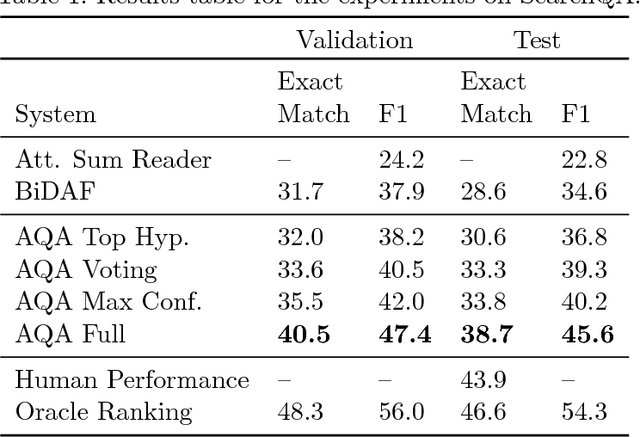
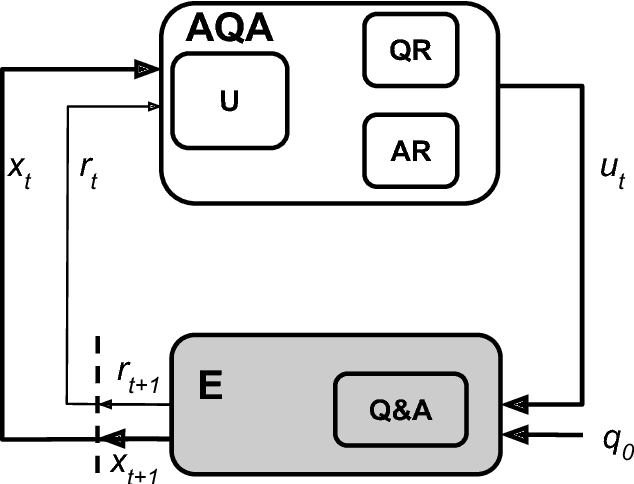
We frame Question Answering (QA) as a Reinforcement Learning task, an approach that we call Active Question Answering. We propose an agent that sits between the user and a black box QA system and learns to reformulate questions to elicit the best possible answers. The agent probes the system with, potentially many, natural language reformulations of an initial question and aggregates the returned evidence to yield the best answer. The reformulation system is trained end-to-end to maximize answer quality using policy gradient. We evaluate on SearchQA, a dataset of complex questions extracted from Jeopardy!. The agent outperforms a state-of-the-art base model, playing the role of the environment, and other benchmarks. We also analyze the language that the agent has learned while interacting with the question answering system. We find that successful question reformulations look quite different from natural language paraphrases. The agent is able to discover non-trivial reformulation strategies that resemble classic information retrieval techniques such as term re-weighting (tf-idf) and stemming.
Analyzing Language Learned by an Active Question Answering Agent
Jan 23, 2018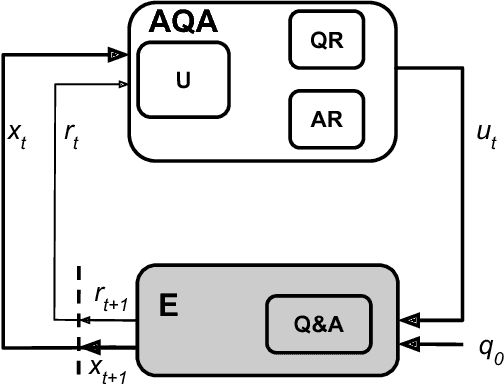
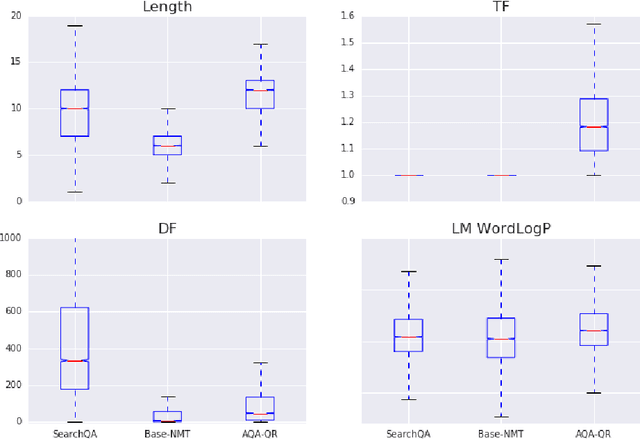
We analyze the language learned by an agent trained with reinforcement learning as a component of the ActiveQA system [Buck et al., 2017]. In ActiveQA, question answering is framed as a reinforcement learning task in which an agent sits between the user and a black box question-answering system. The agent learns to reformulate the user's questions to elicit the optimal answers. It probes the system with many versions of a question that are generated via a sequence-to-sequence question reformulation model, then aggregates the returned evidence to find the best answer. This process is an instance of \emph{machine-machine} communication. The question reformulation model must adapt its language to increase the quality of the answers returned, matching the language of the question answering system. We find that the agent does not learn transformations that align with semantic intuitions but discovers through learning classical information retrieval techniques such as tf-idf re-weighting and stemming.
Scalable Probabilistic Entity-Topic Modeling
Sep 02, 2013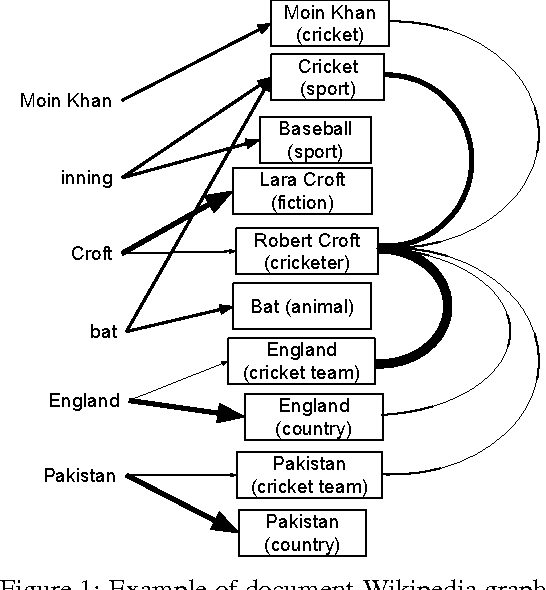
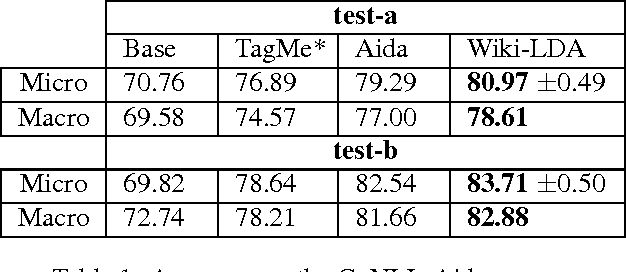
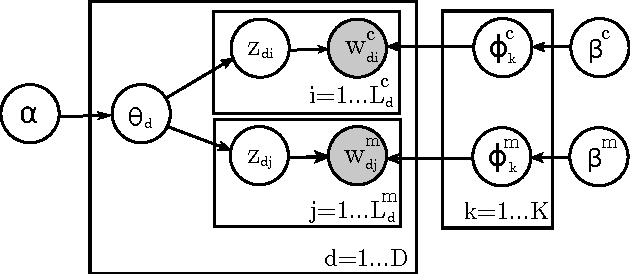
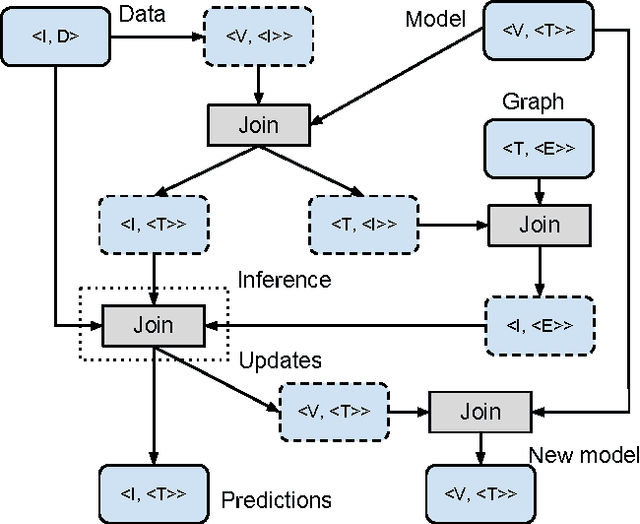
We present an LDA approach to entity disambiguation. Each topic is associated with a Wikipedia article and topics generate either content words or entity mentions. Training such models is challenging because of the topic and vocabulary size, both in the millions. We tackle these problems using a novel distributed inference and representation framework based on a parallel Gibbs sampler guided by the Wikipedia link graph, and pipelines of MapReduce allowing fast and memory-frugal processing of large datasets. We report state-of-the-art performance on a public dataset.
Explaining away ambiguity: Learning verb selectional preference with Bayesian networks
Aug 22, 2000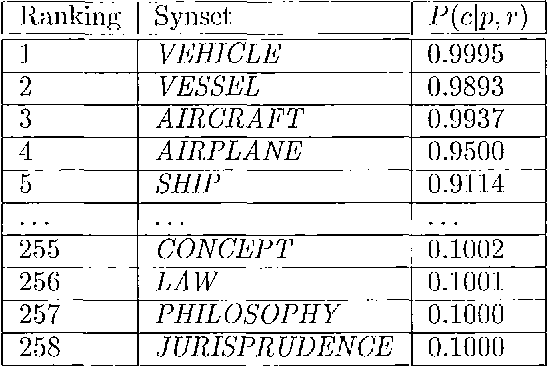
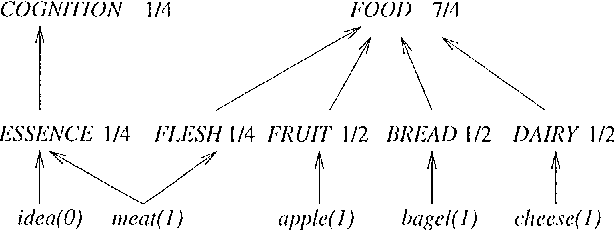

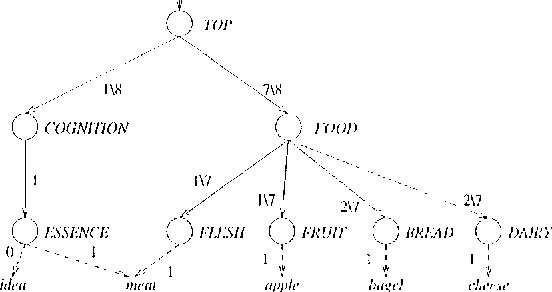
This paper presents a Bayesian model for unsupervised learning of verb selectional preferences. For each verb the model creates a Bayesian network whose architecture is determined by the lexical hierarchy of Wordnet and whose parameters are estimated from a list of verb-object pairs found from a corpus. ``Explaining away'', a well-known property of Bayesian networks, helps the model deal in a natural fashion with word sense ambiguity in the training data. On a word sense disambiguation test our model performed better than other state of the art systems for unsupervised learning of selectional preferences. Computational complexity problems, ways of improving this approach and methods for implementing ``explaining away'' in other graphical frameworks are discussed.