 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonochrome and Color Polarization Demosaicking Using Edge-Aware Residual Interpolation
Jul 28, 2020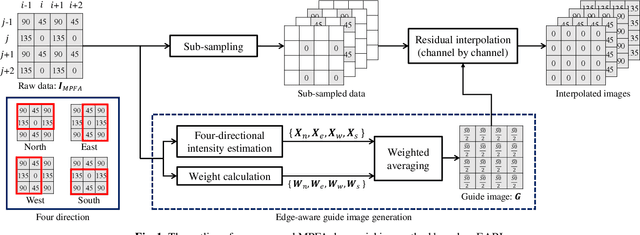
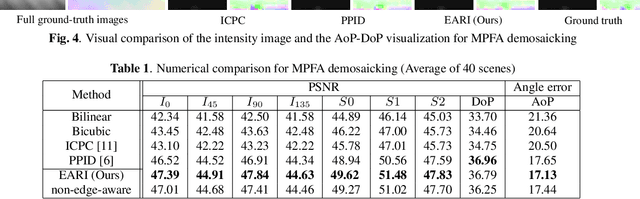
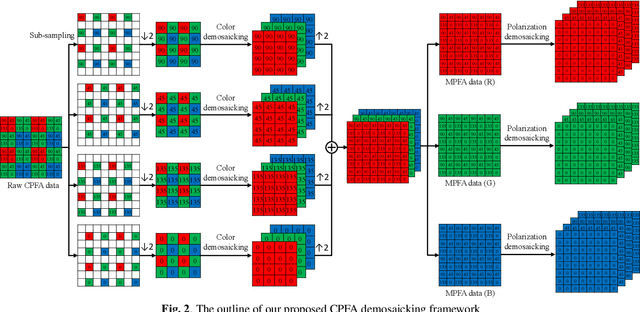
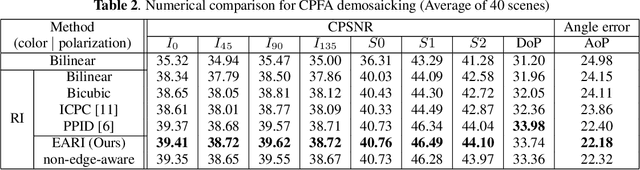
A division-of-focal-plane or microgrid image polarimeter enables us to acquire a set of polarization images in one shot. Since the polarimeter consists of an image sensor equipped with a monochrome or color polarization filter array (MPFA or CPFA), the demosaicking process to interpolate missing pixel values plays a crucial role in obtaining high-quality polarization images. In this paper, we propose a novel MPFA demosaicking method based on edge-aware residual interpolation (EARI) and also extend it to CPFA demosaicking. The key of EARI is a new edge detector for generating an effective guide image used to interpolate the missing pixel values. We also present a newly constructed full color-polarization image dataset captured using a 3-CCD camera and a rotating polarizer. Using the dataset, we experimentally demonstrate that our EARI-based method outperforms existing methods in MPFA and CPFA demosaicking.
Unsupervised Learning of Image Segmentation Based on Differentiable Feature Clustering
Jul 20, 2020



The usage of convolutional neural networks (CNNs) for unsupervised image segmentation was investigated in this study. In the proposed approach, label prediction and network parameter learning are alternately iterated to meet the following criteria: (a) pixels of similar features should be assigned the same label, (b) spatially continuous pixels should be assigned the same label, and (c) the number of unique labels should be large. Although these criteria are incompatible, the proposed approach minimizes the combination of similarity loss and spatial continuity loss to find a plausible solution of label assignment that balances the aforementioned criteria well. The contributions of this study are four-fold. First, we propose a novel end-to-end network of unsupervised image segmentation that consists of normalization and an argmax function for differentiable clustering. Second, we introduce a spatial continuity loss function that mitigates the limitations of fixed segment boundaries possessed by previous work. Third, we present an extension of the proposed method for segmentation with scribbles as user input, which showed better accuracy than existing methods while maintaining efficiency. Finally, we introduce another extension of the proposed method: unseen image segmentation by using networks pre-trained with a few reference images without re-training the networks. The effectiveness of the proposed approach was examined on several benchmark datasets of image segmentation.
Classifying degraded images over various levels of degradation
Jun 15, 2020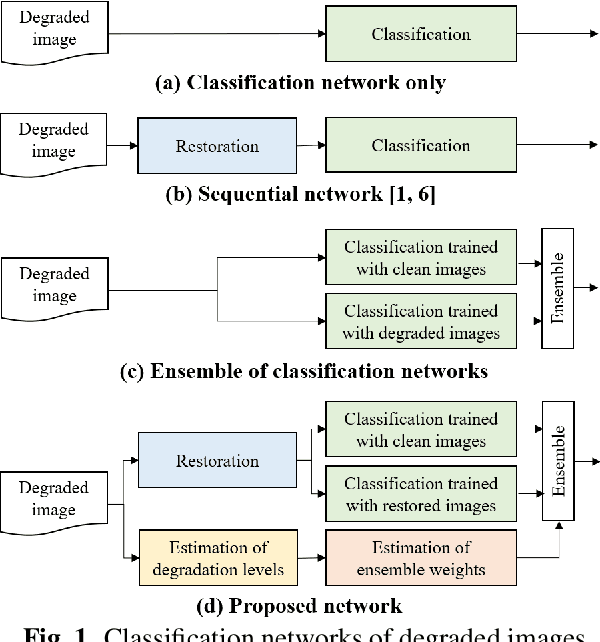
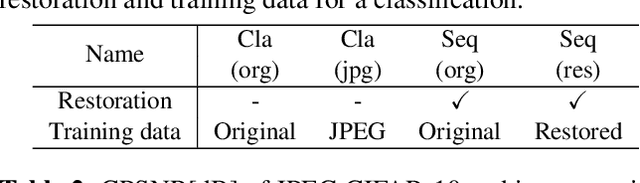
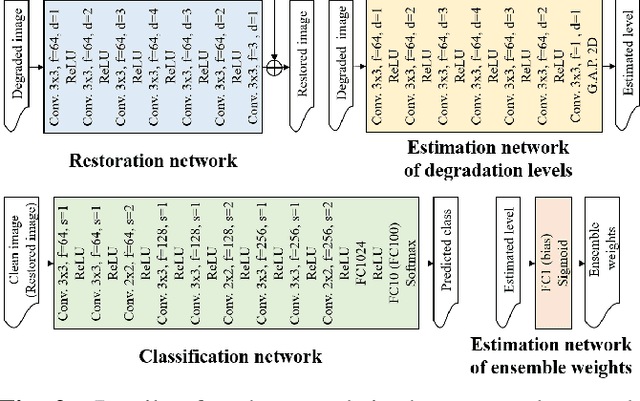
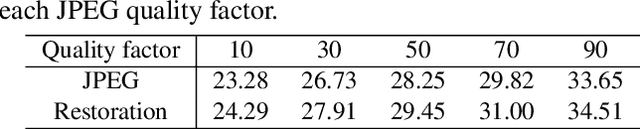
Classification for degraded images having various levels of degradation is very important in practical applications. This paper proposes a convolutional neural network to classify degraded images by using a restoration network and an ensemble learning. The results demonstrate that the proposed network can classify degraded images over various levels of degradation well. This paper also reveals how the image-quality of training data for a classification network affects the classification performance of degraded images.
Learning-Based Human Segmentation and Velocity Estimation Using Automatic Labeled LiDAR Sequence for Training
Mar 11, 2020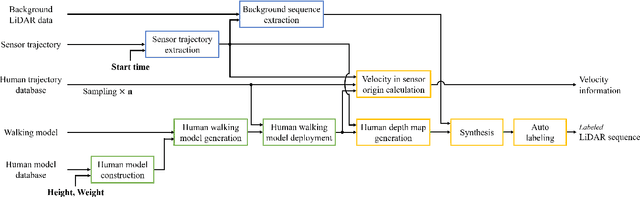

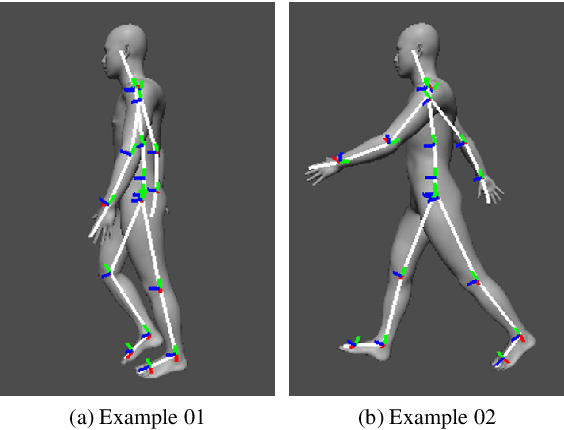

In this paper, we propose an automatic labeled sequential data generation pipeline for human segmentation and velocity estimation with point clouds. Considering the impact of deep neural networks, state-of-the-art network architectures have been proposed for human recognition using point clouds captured by Light Detection and Ranging (LiDAR). However, one disadvantage is that legacy datasets may only cover the image domain without providing important label information and this limitation has disturbed the progress of research to date. Therefore, we develop an automatic labeled sequential data generation pipeline, in which we can control any parameter or data generation environment with pixel-wise and per-frame ground truth segmentation and pixel-wise velocity information for human recognition. Our approach uses a precise human model and reproduces a precise motion to generate realistic artificial data. We present more than 7K video sequences which consist of 32 frames generated by the proposed pipeline. With the proposed sequence generator, we confirm that human segmentation performance is improved when using the video domain compared to when using the image domain. We also evaluate our data by comparing with data generated under different conditions. In addition, we estimate pedestrian velocity with LiDAR by only utilizing data generated by the proposed pipeline.
Block-wise Scrambled Image Recognition Using Adaptation Network
Jan 21, 2020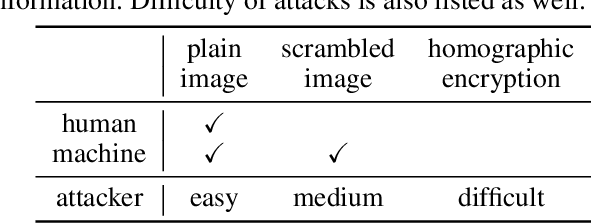
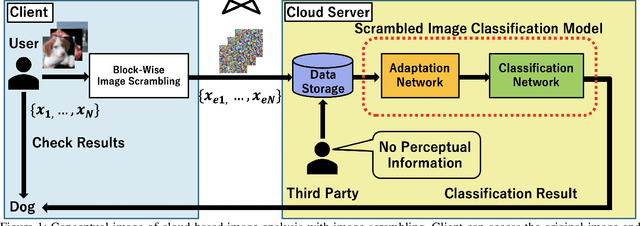


In this study, a perceptually hidden object-recognition method is investigated to generate secure images recognizable by humans but not machines. Hence, both the perceptual information hiding and the corresponding object recognition methods should be developed. Block-wise image scrambling is introduced to hide perceptual information from a third party. In addition, an adaptation network is proposed to recognize those scrambled images. Experimental comparisons conducted using CIFAR datasets demonstrated that the proposed adaptation network performed well in incorporating simple perceptual information hiding into DNN-based image classification.
New Perspective of Interpretability of Deep Neural Networks
Sep 12, 2019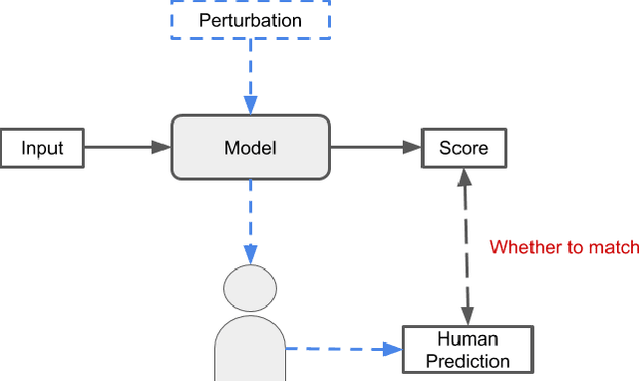


Deep neural networks (DNNs) are known as black-box models. In other words, it is difficult to interpret the internal state of the model. Improving the interpretability of DNNs is one of the hot research topics. However, at present, the definition of interpretability for DNNs is vague, and the question of what is a highly explanatory model is still controversial. To address this issue, we provide the definition of the human predictability of the model, as a part of the interpretability of the DNNs. The human predictability proposed in this paper is defined by easiness to predict the change of the inference when perturbating the model of the DNNs. In addition, we introduce one example of high human-predictable DNNs. We discuss that our definition will help to the research of the interpretability of the DNNs considering various types of applications.
Breaking Inter-Layer Co-Adaptation by Classifier Anonymization
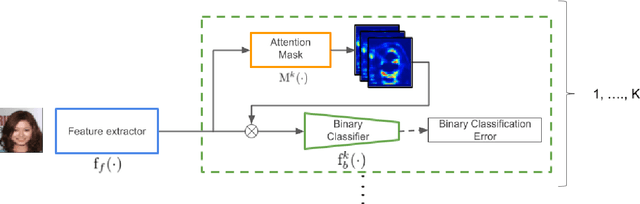
Jun 04, 2019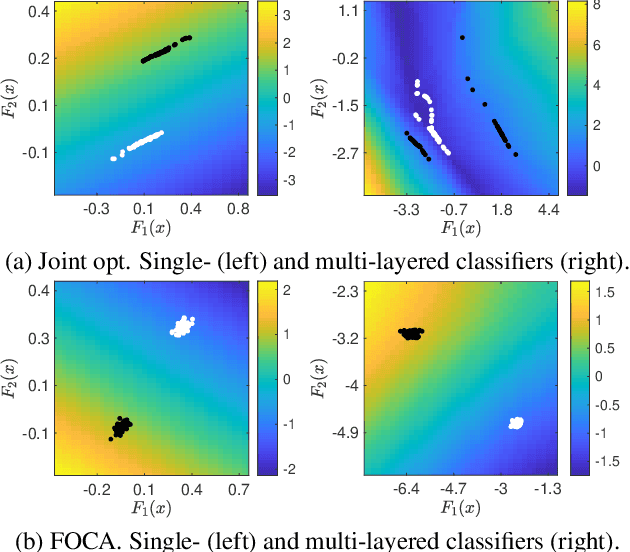
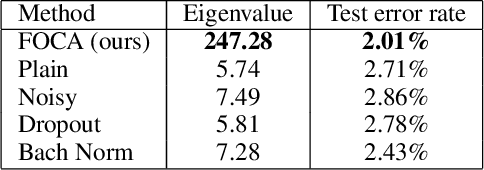
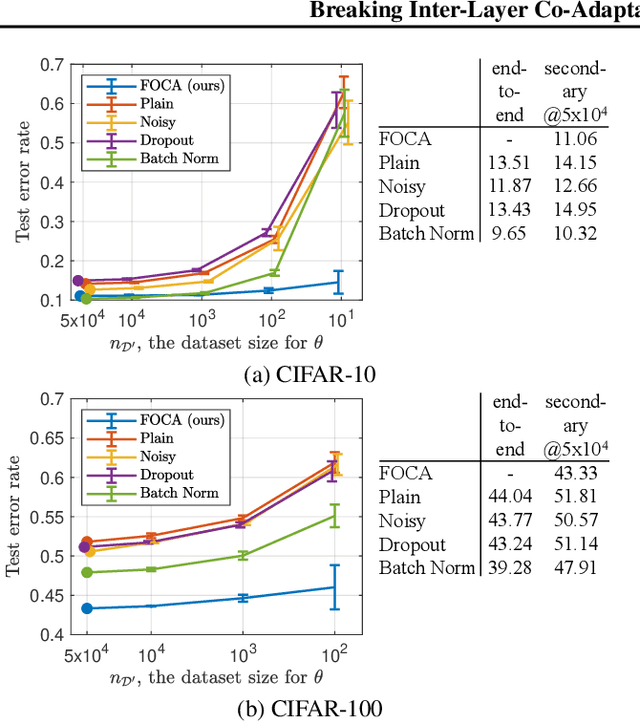
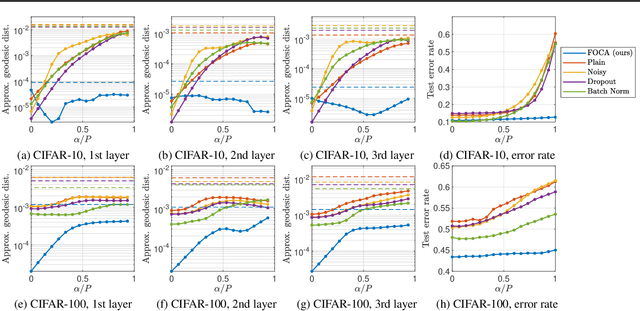
This study addresses an issue of co-adaptation between a feature extractor and a classifier in a neural network. A naive joint optimization of a feature extractor and a classifier often brings situations in which an excessively complex feature distribution adapted to a very specific classifier degrades the test performance. We introduce a method called Feature-extractor Optimization through Classifier Anonymization (FOCA), which is designed to avoid an explicit co-adaptation between a feature extractor and a particular classifier by using many randomly-generated, weak classifiers during optimization. We put forth a mathematical proposition that states the FOCA features form a point-like distribution within the same class in a class-separable fashion under special conditions. Real-data experiments under more general conditions provide supportive evidences.
Intentional Attention Mask Transformation for Robust CNN Classification
May 20, 2019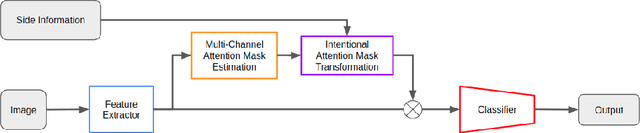

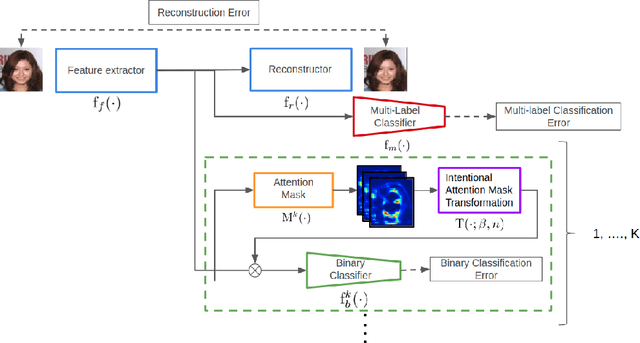

Convolutional Neural Networks have achieved impressive results in various tasks, but interpreting the internal mechanism is a challenging problem. To tackle this problem, we exploit a multi-channel attention mechanism in feature space. Our network architecture allows us to obtain an attention mask for each feature while existing CNN visualization methods provide only a common attention mask for all features. We apply the proposed multi-channel attention mechanism to multi-attribute recognition task. We can obtain different attention mask for each feature and for each attribute. Those analyses give us deeper insight into the feature space of CNNs. Furthermore, our proposed attention mechanism naturally derives a method for improving the robustness of CNNs. From the observation of feature space based on the proposed attention mask, we demonstrate that we can obtain robust CNNs by intentionally emphasizing features that are important for attributes. The experimental results for the benchmark dataset show that the proposed method gives high human interpretability while accurately grasping the attributes of the data, and improves network robustness.
Interpretation of Feature Space using Multi-Channel Attentional Sub-Networks
Apr 30, 2019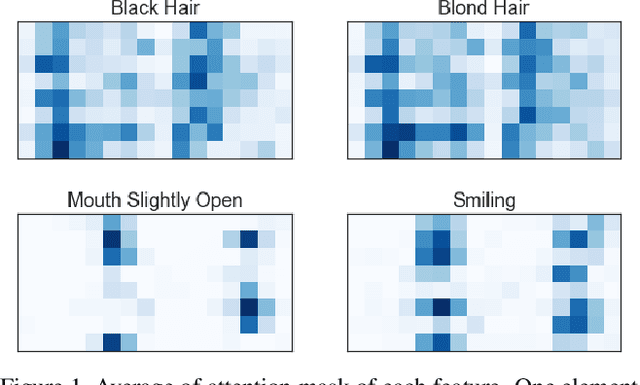
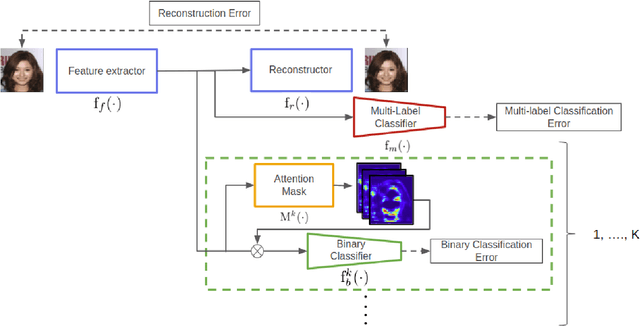
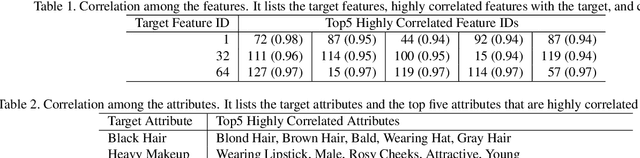

Convolutional Neural Networks have achieved impressive results in various tasks, but interpreting the internal mechanism is a challenging problem. To tackle this problem, we exploit a multi-channel attention mechanism in feature space. Our network architecture allows us to obtain an attention mask for each feature while existing CNN visualization methods provide only a common attention mask for all features. We apply the proposed multi-channel attention mechanism to multi-attribute recognition task. We can obtain different attention mask for each feature and for each attribute. Those analyses give us deeper insight into the feature space of CNNs. The experimental results for the benchmark dataset show that the proposed method gives high interpretability to humans while accurately grasping the attributes of the data.
Improving Transparency of Deep Neural Inference Process
Mar 13, 2019



Deep learning techniques are rapidly advanced recently, and becoming a necessity component for widespread systems. However, the inference process of deep learning is black-box, and not very suitable to safety-critical systems which must exhibit high transparency. In this paper, to address this black-box limitation, we develop a simple analysis method which consists of 1) structural feature analysis: lists of the features contributing to inference process, 2) linguistic feature analysis: lists of the natural language labels describing the visual attributes for each feature contributing to inference process, and 3) consistency analysis: measuring consistency among input data, inference (label), and the result of our structural and linguistic feature analysis. Our analysis is simplified to reflect the actual inference process for high transparency, whereas it does not include any additional black-box mechanisms such as LSTM for highly human readable results. We conduct experiments and discuss the results of our analysis qualitatively and quantitatively, and come to believe that our work improves the transparency of neural networks. Evaluated through 12,800 human tasks, 75% workers answer that input data and result of our feature analysis are consistent, and 70% workers answer that inference (label) and result of our feature analysis are consistent. In addition to the evaluation of the proposed analysis, we find that our analysis also provide suggestions, or possible next actions such as expanding neural network complexity or collecting training data to improve a neural network.