 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling the Knowledge of BERT for Sequence-to-Sequence ASR
Aug 09, 2020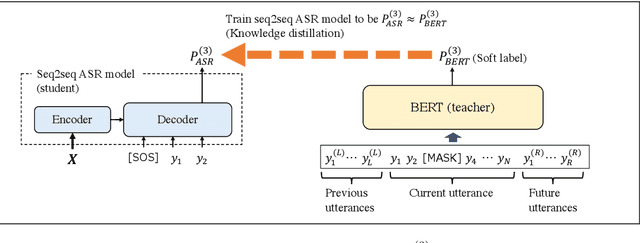
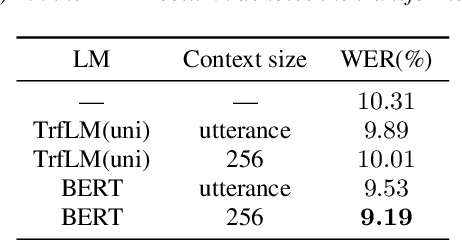
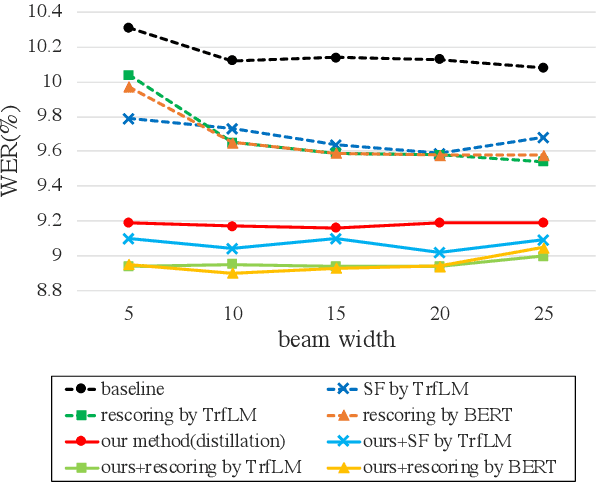
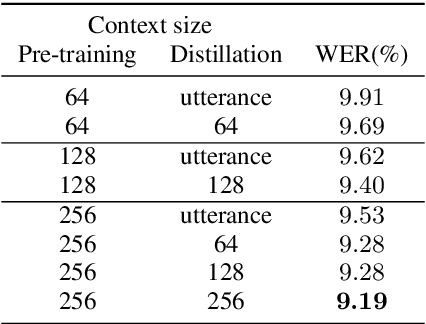
Attention-based sequence-to-sequence (seq2seq) models have achieved promising results in automatic speech recognition (ASR). However, as these models decode in a left-to-right way, they do not have access to context on the right. We leverage both left and right context by applying BERT as an external language model to seq2seq ASR through knowledge distillation. In our proposed method, BERT generates soft labels to guide the training of seq2seq ASR. Furthermore, we leverage context beyond the current utterance as input to BERT. Experimental evaluations show that our method significantly improves the ASR performance from the seq2seq baseline on the Corpus of Spontaneous Japanese (CSJ). Knowledge distillation from BERT outperforms that from a transformer LM that only looks at left context. We also show the effectiveness of leveraging context beyond the current utterance. Our method outperforms other LM application approaches such as n-best rescoring and shallow fusion, while it does not require extra inference cost.
Enhancing Monotonic Multihead Attention for Streaming ASR
May 23, 2020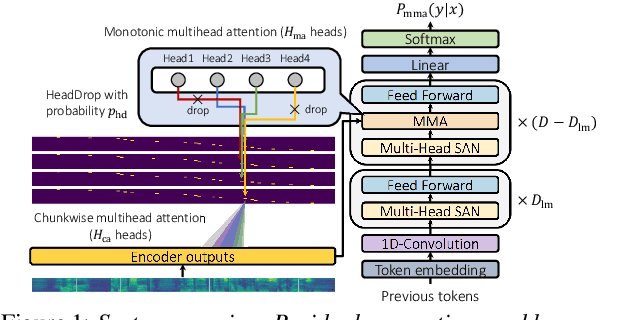
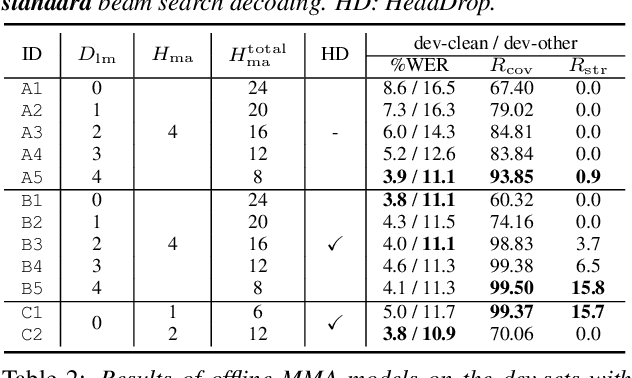
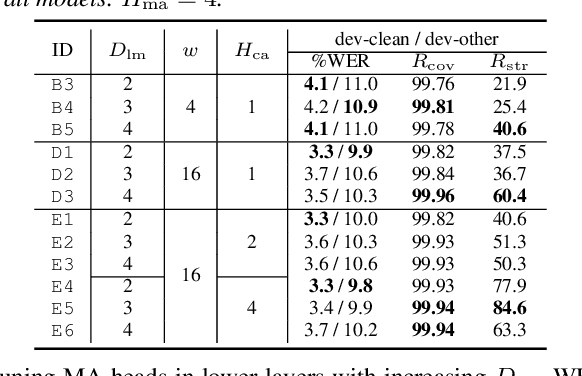
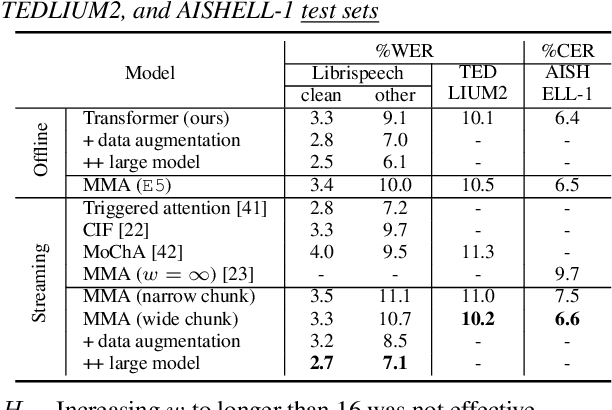
We investigate a monotonic multihead attention (MMA) by extending hard monotonic attention to Transformer-based automatic speech recognition (ASR) for online streaming applications. For streaming inference, all monotonic attention (MA) heads should learn proper alignments because the next token is not generated until all heads detect the corresponding token boundaries. However, we found not all MA heads learn alignments with a naive implementation. To encourage every head to learn alignments properly, we propose HeadDrop regularization by masking out a part of heads stochastically during training. Furthermore, we propose to prune redundant heads to improve consensus among heads for boundary detection and prevent delayed token generation caused by such heads. Chunkwise attention on each MA head is extended to the multihead counterpart. Finally, we propose head-synchronous beam search decoding to guarantee stable streaming inference.
Generative Adversarial Training Data Adaptation for Very Low-resource Automatic Speech Recognition
May 19, 2020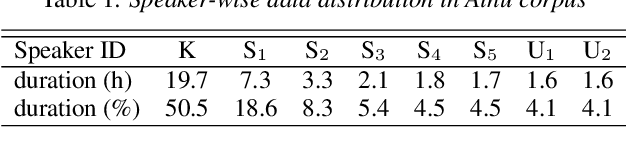
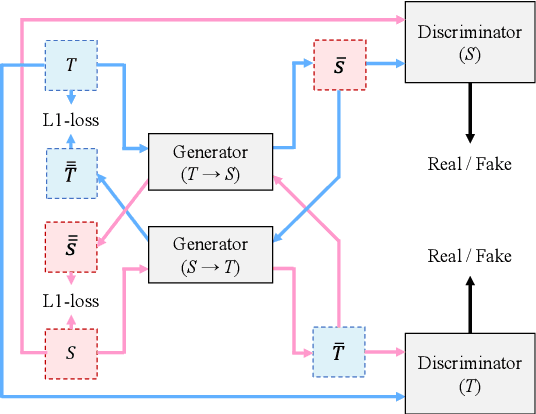
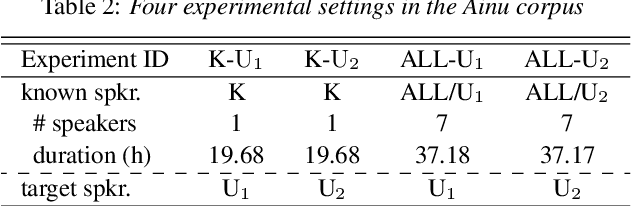
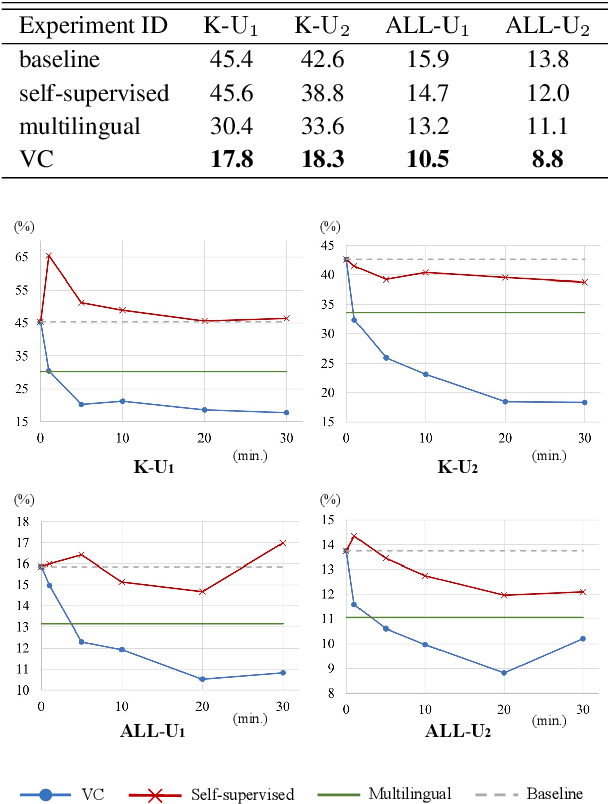
It is important to transcribe and archive speech data of endangered languages for preserving heritages of verbal culture and automatic speech recognition (ASR) is a powerful tool to facilitate this process. However, since endangered languages do not generally have large corpora with many speakers, the performance of ASR models trained on them are considerably poor in general. Nevertheless, we are often left with a lot of recordings of spontaneous speech data that have to be transcribed. In this work, for mitigating this speaker sparsity problem, we propose to convert the whole training speech data and make it sound like the test speaker in order to develop a highly accurate ASR system for this speaker. For this purpose, we utilize a CycleGAN-based non-parallel voice conversion technology to forge a labeled training data that is close to the test speaker's speech. We evaluated this speaker adaptation approach on two low-resource corpora, namely, Ainu and Mboshi. We obtained 35-60% relative improvement in phone error rate on the Ainu corpus, and 40% relative improvement was attained on the Mboshi corpus. This approach outperformed two conventional methods namely unsupervised adaptation and multilingual training with these two corpora.
CTC-synchronous Training for Monotonic Attention Model
May 17, 2020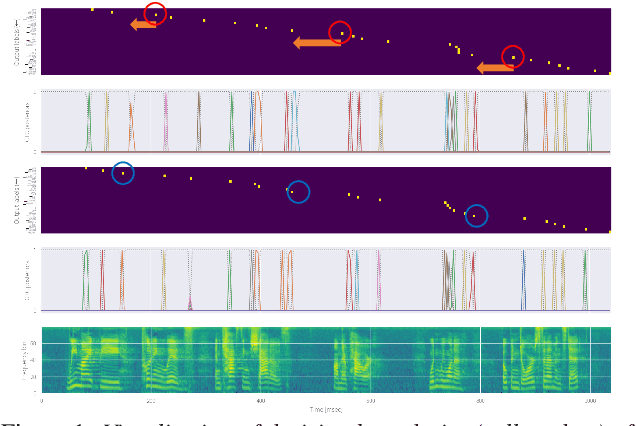

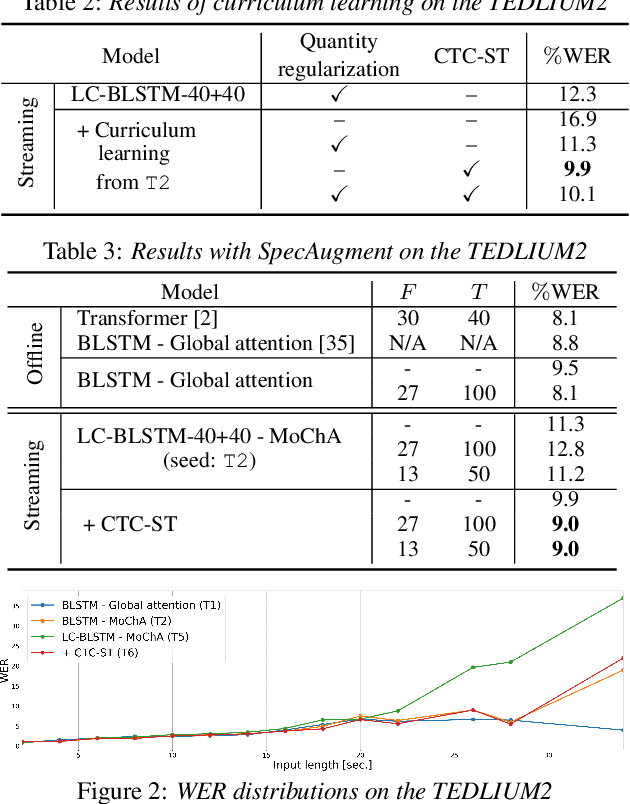
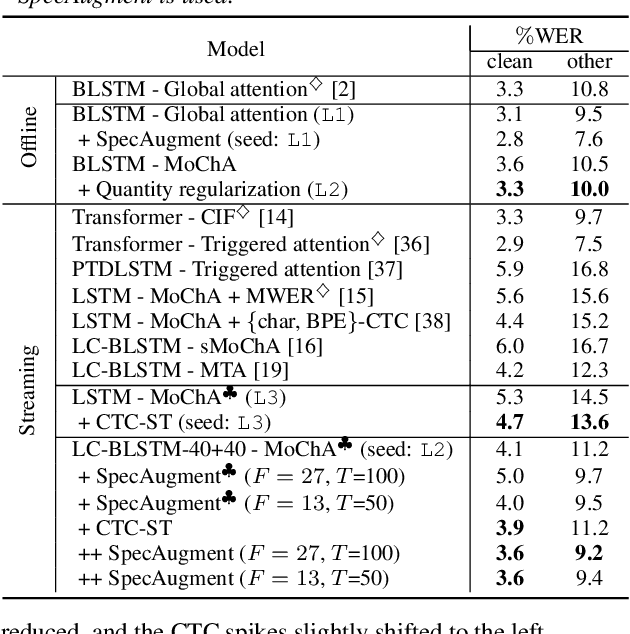
Monotonic chunkwise attention (MoChA) has been studied for the online streaming automatic speech recognition (ASR) based on a sequence-to-sequence framework. In contrast to connectionist temporal classification (CTC), backward probabilities cannot be leveraged in the alignment marginalization process during training due to left-to-right dependency in the decoder. This results in the error propagation of alignments to subsequent token generation. To address this problem, we propose CTC-synchronous training (CTC-ST), in which MoChA uses CTC alignments to learn optimal monotonic alignments. Reference CTC alignments are extracted from a CTC branch sharing the same encoder. The entire model is jointly optimized so that the expected boundaries from MoChA are synchronized with the alignments. Experimental evaluations of the TEDLIUM release-2 and Librispeech corpora show that the proposed method significantly improves recognition, especially for long utterances. We also show that CTC-ST can bring out the full potential of SpecAugment for MoChA.
Speech Corpus of Ainu Folklore and End-to-end Speech Recognition for Ainu Language
Feb 19, 2020
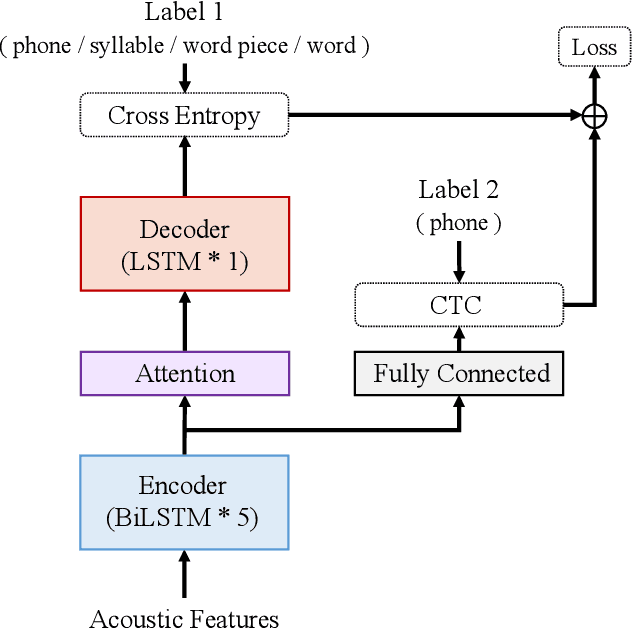
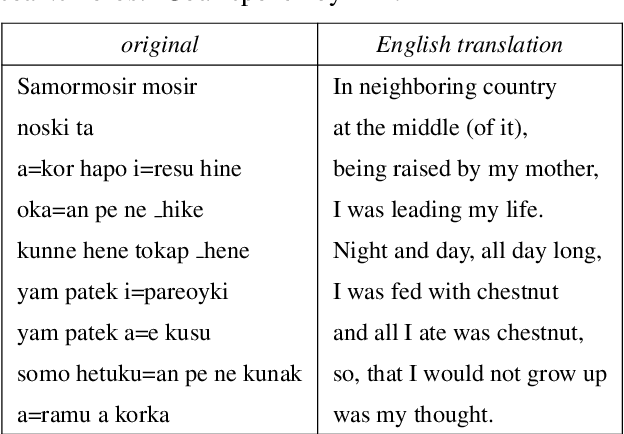
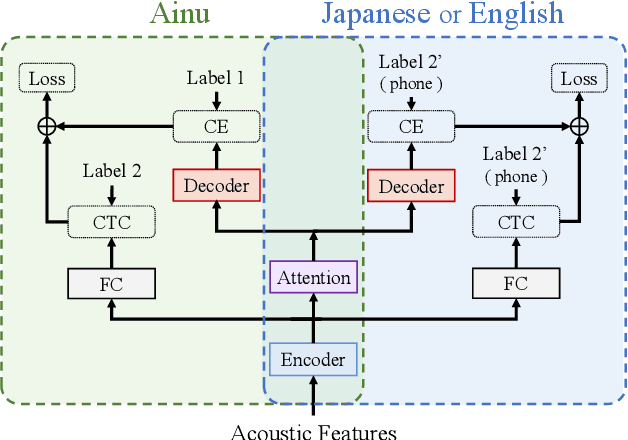
Ainu is an unwritten language that has been spoken by Ainu people who are one of the ethnic groups in Japan. It is recognized as critically endangered by UNESCO and archiving and documentation of its language heritage is of paramount importance. Although a considerable amount of voice recordings of Ainu folklore has been produced and accumulated to save their culture, only a quite limited parts of them are transcribed so far. Thus, we started a project of automatic speech recognition (ASR) for the Ainu language in order to contribute to the development of annotated language archives. In this paper, we report speech corpus development and the structure and performance of end-to-end ASR for Ainu. We investigated four modeling units (phone, syllable, word piece, and word) and found that the syllable-based model performed best in terms of both word and phone recognition accuracy, which were about 60% and over 85% respectively in speaker-open condition. Furthermore, word and phone accuracy of 80% and 90% has been achieved in a speaker-closed setting. We also found out that a multilingual ASR training with additional speech corpora of English and Japanese further improves the speaker-open test accuracy.
Improving OOV Detection and Resolution with External Language Models in Acoustic-to-Word ASR
Sep 22, 2019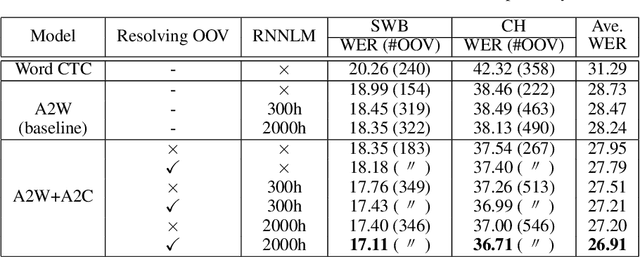
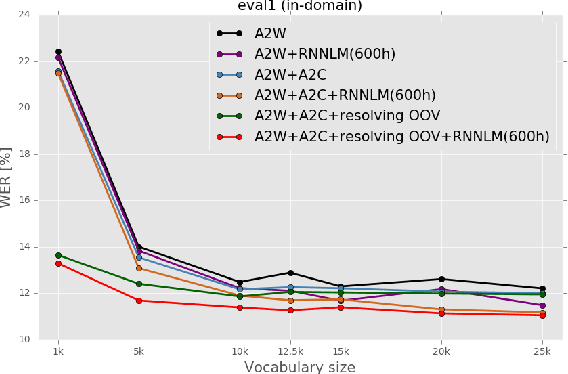
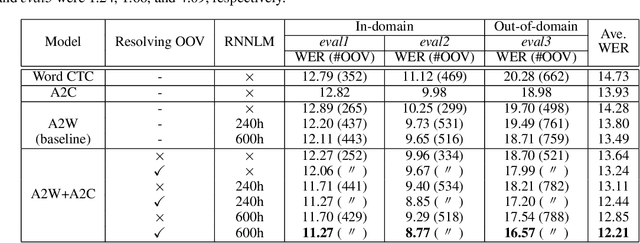
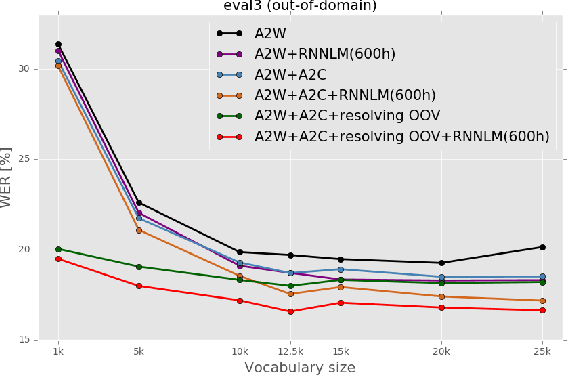
Acoustic-to-word (A2W) end-to-end automatic speech recognition (ASR) systems have attracted attention because of an extremely simplified architecture and fast decoding. To alleviate data sparseness issues due to infrequent words, the combination with an acoustic-to-character (A2C) model is investigated. Moreover, the A2C model can be used to recover out-of-vocabulary (OOV) words that are not covered by the A2W model, but this requires accurate detection of OOV words. A2W models learn contexts with both acoustic and transcripts; therefore they tend to falsely recognize OOV words as words in the vocabulary. In this paper, we tackle this problem by using external language models (LM), which are trained only with transcriptions and have better linguistic information to detect OOV words. The A2C model is used to resolve these OOV words. Experimental evaluations show that external LMs have the effects of not only reducing errors but also increasing the number of detected OOV words, and the proposed method significantly improves performances in English conversational and Japanese lecture corpora, especially for out-of-domain scenario. We also investigate the impact of the vocabulary size of A2W models and the data size for training LMs. Moreover, our approach can reduce the vocabulary size several times with marginal performance degradation.
Unsupervised Speech Enhancement Based on Multichannel NMF-Informed Beamforming for Noise-Robust Automatic Speech Recognition
Mar 31, 2019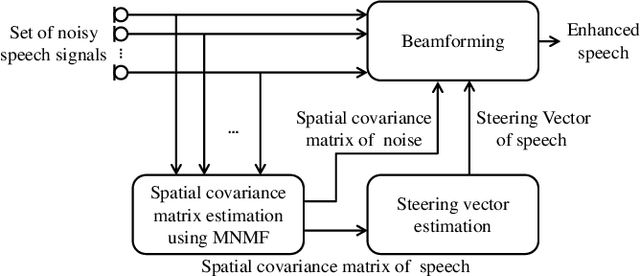

This paper describes multichannel speech enhancement for improving automatic speech recognition (ASR) in noisy environments. Recently, the minimum variance distortionless response (MVDR) beamforming has widely been used because it works well if the steering vector of speech and the spatial covariance matrix (SCM) of noise are given. To estimating such spatial information, conventional studies take a supervised approach that classifies each time-frequency (TF) bin into noise or speech by training a deep neural network (DNN). The performance of ASR, however, is degraded in an unknown noisy environment. To solve this problem, we take an unsupervised approach that decomposes each TF bin into the sum of speech and noise by using multichannel nonnegative matrix factorization (MNMF). This enables us to accurately estimate the SCMs of speech and noise not from observed noisy mixtures but from separated speech and noise components. In this paper we propose online MVDR beamforming by effectively initializing and incrementally updating the parameters of MNMF. Another main contribution is to comprehensively investigate the performances of ASR obtained by various types of spatial filters, i.e., time-invariant and variant versions of MVDR beamformers and those of rank-1 and full-rank multichannel Wiener filters, in combination with MNMF. The experimental results showed that the proposed method outperformed the state-of-the-art DNN-based beamforming method in unknown environments that did not match training data.
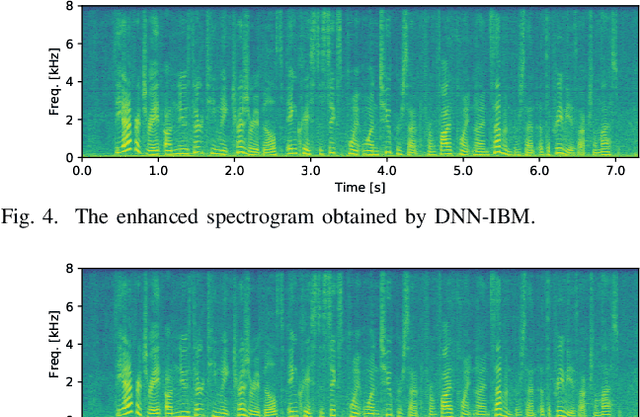
Statistical Speech Enhancement Based on Probabilistic Integration of Variational Autoencoder and Non-Negative Matrix Factorization
Mar 19, 2018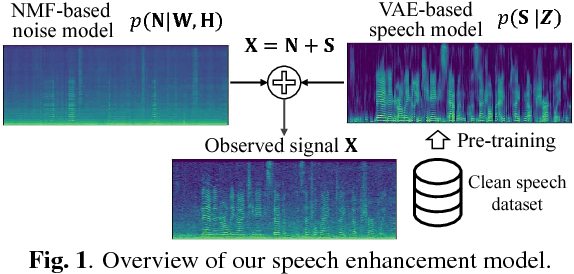
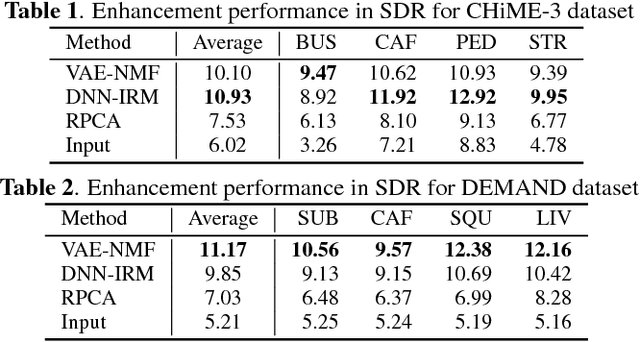
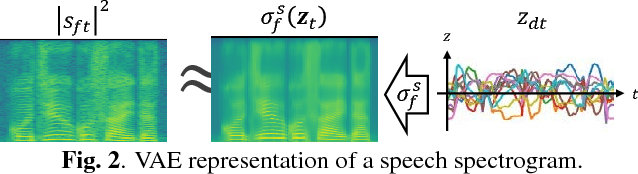

This paper presents a statistical method of single-channel speech enhancement that uses a variational autoencoder (VAE) as a prior distribution on clean speech. A standard approach to speech enhancement is to train a deep neural network (DNN) to take noisy speech as input and output clean speech. Although this supervised approach requires a very large amount of pair data for training, it is not robust against unknown environments. Another approach is to use non-negative matrix factorization (NMF) based on basis spectra trained on clean speech in advance and those adapted to noise on the fly. This semi-supervised approach, however, causes considerable signal distortion in enhanced speech due to the unrealistic assumption that speech spectrograms are linear combinations of the basis spectra. Replacing the poor linear generative model of clean speech in NMF with a VAE---a powerful nonlinear deep generative model---trained on clean speech, we formulate a unified probabilistic generative model of noisy speech. Given noisy speech as observed data, we can sample clean speech from its posterior distribution. The proposed method outperformed the conventional DNN-based method in unseen noisy environments.