 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Contact Model based on Denoising Diffusion to Learn Variable Impedance Control for Contact-rich Manipulation
Mar 20, 2024In this paper, a novel approach is proposed for learning robot control in contact-rich tasks such as wiping, by developing Diffusion Contact Model (DCM). Previous methods of learning such tasks relied on impedance control with time-varying stiffness tuning by performing Bayesian optimization by trial-and-error with robots. The proposed approach aims to reduce the cost of robot operation by predicting the robot contact trajectories from the variable stiffness inputs and using neural models. However, contact dynamics are inherently highly nonlinear, and their simulation requires iterative computations such as convex optimization. Moreover, approximating such computations by using finite-layer neural models is difficult. To overcome these limitations, the proposed DCM used the denoising diffusion models that could simulate the complex dynamics via iterative computations of multi-step denoising, thus improving the prediction accuracy. Stiffness tuning experiments conducted in simulated and real environments showed that the DCM achieved comparable performance to a conventional robot-based optimization method while reducing the number of robot trials.
Representation Synthesis by Probabilistic Many-Valued Logic Operation in Self-Supervised Learning
Sep 08, 2023Self-supervised learning (SSL) using mixed images has been studied to learn various image representations. Existing methods using mixed images learn a representation by maximizing the similarity between the representation of the mixed image and the synthesized representation of the original images. However, few methods consider the synthesis of representations from the perspective of mathematical logic. In this study, we focused on a synthesis method of representations. We proposed a new SSL with mixed images and a new representation format based on many-valued logic. This format can indicate the feature-possession degree, that is, how much of each image feature is possessed by a representation. This representation format and representation synthesis by logic operation realize that the synthesized representation preserves the remarkable characteristics of the original representations. Our method performed competitively with previous representation synthesis methods for image classification tasks. We also examined the relationship between the feature-possession degree and the number of classes of images in the multilabel image classification dataset to verify that the intended learning was achieved. In addition, we discussed image retrieval, which is an application of our proposed representation format using many-valued logic.
Learning Compliant Stiffness by Impedance Control-Aware Task Segmentation and Multi-objective Bayesian Optimization with Priors
Jul 28, 2023



Rather than traditional position control, impedance control is preferred to ensure the safe operation of industrial robots programmed from demonstrations. However, variable stiffness learning studies have focused on task performance rather than safety (or compliance). Thus, this paper proposes a novel stiffness learning method to satisfy both task performance and compliance requirements. The proposed method optimizes the task and compliance objectives (T/C objectives) simultaneously via multi-objective Bayesian optimization. We define the stiffness search space by segmenting a demonstration into task phases, each with constant responsible stiffness. The segmentation is performed by identifying impedance control-aware switching linear dynamics (IC-SLD) from the demonstration. We also utilize the stiffness obtained by proposed IC-SLD as priors for efficient optimization. Experiments on simulated tasks and a real robot demonstrate that IC-SLD-based segmentation and the use of priors improve the optimization efficiency compared to existing baseline methods.
Online Re-Planning and Adaptive Parameter Update for Multi-Agent Path Finding with Stochastic Travel Times
Feb 03, 2023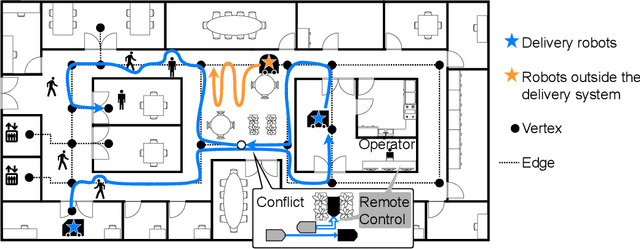
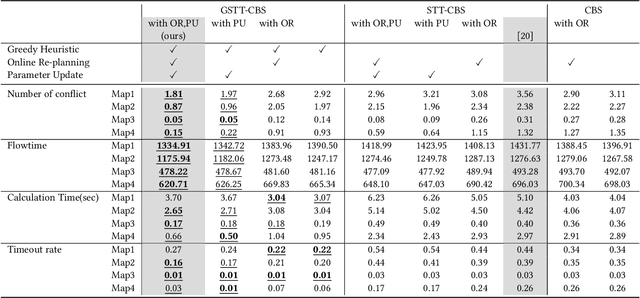
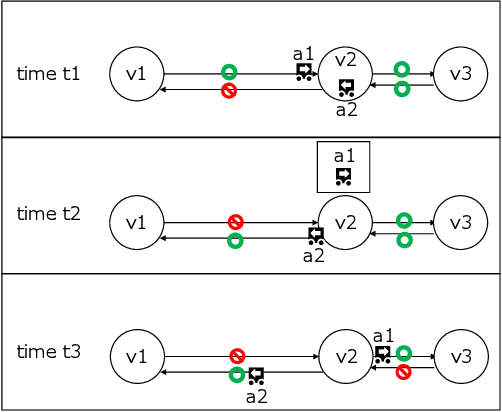
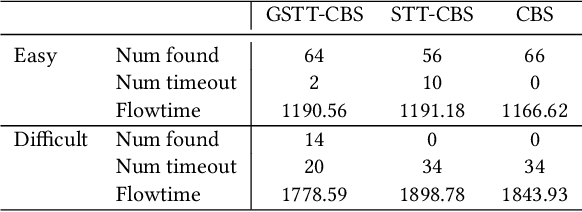
This study explores the problem of Multi-Agent Path Finding with continuous and stochastic travel times whose probability distribution is unknown. Our purpose is to manage a group of automated robots that provide package delivery services in a building where pedestrians and a wide variety of robots coexist, such as delivery services in office buildings, hospitals, and apartments. It is often the case with these real-world applications that the time required for the robots to traverse a corridor takes a continuous value and is randomly distributed, and the prior knowledge of the probability distribution of the travel time is limited. Multi-Agent Path Finding has been widely studied and applied to robot management systems; however, automating the robot operation in such environments remains difficult. We propose 1) online re-planning to update the action plan of robots while it is executed, and 2) parameter update to estimate the probability distribution of travel time using Bayesian inference as the delay is observed. We use a greedy heuristic to obtain solutions in a limited computation time. Through simulations, we empirically compare the performance of our method to those of existing methods in terms of the conflict probability and the actual travel time of robots. The simulation results indicate that the proposed method can find travel paths with at least 50% fewer conflicts and a shorter actual total travel time than existing methods. The proposed method requires a small number of trials to achieve the performance because the parameter update is prioritized on the important edges for path planning, thereby satisfying the requirements of quick implementation of robust planning of automated delivery services.
Self-Supervised Representation Learning as Multimodal Variational Inference
Mar 22, 2022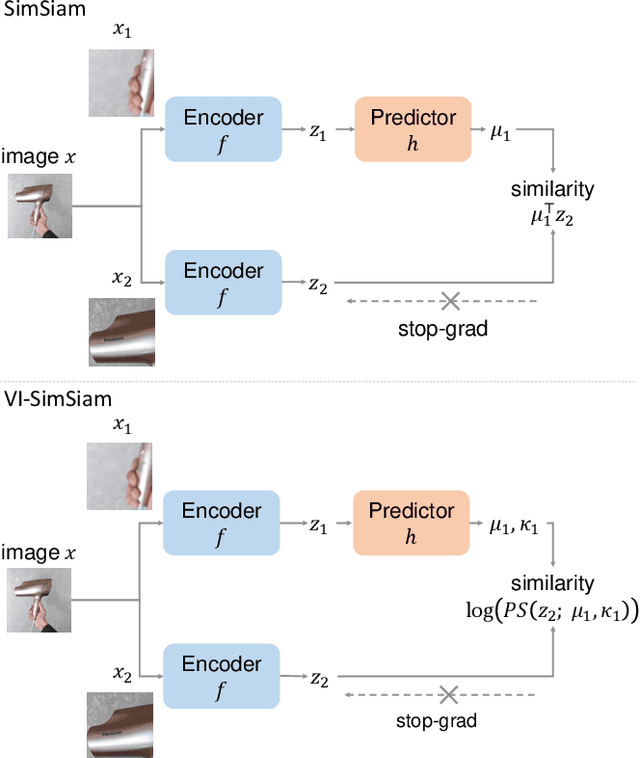

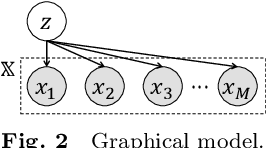
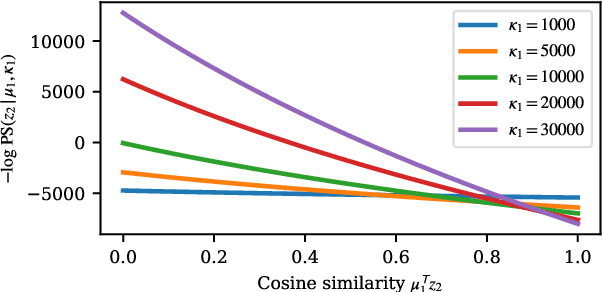
This paper proposes a probabilistic extension of SimSiam, a recent self-supervised learning (SSL) method. SimSiam trains a model by maximizing the similarity between image representations of different augmented views of the same image. Although uncertainty-aware machine learning has been getting general like deep variational inference, SimSiam and other SSL are insufficiently uncertainty-aware, which could lead to limitations on its potential. The proposed extension is to make SimSiam uncertainty-aware based on variational inference. Our main contributions are twofold: Firstly, we clarify the theoretical relationship between non-contrastive SSL and multimodal variational inference. Secondly, we introduce a novel SSL called variational inference SimSiam (VI-SimSiam), which incorporates the uncertainty by involving spherical posterior distributions. Our experiment shows that VI-SimSiam outperforms SimSiam in classification tasks in ImageNette and ImageWoof by successfully estimating the representation uncertainty.
Multi-View Dreaming: Multi-View World Model with Contrastive Learning
Mar 15, 2022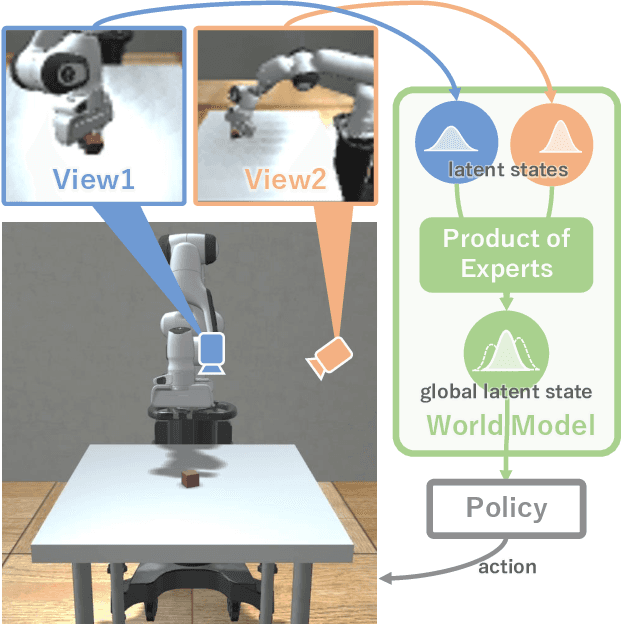
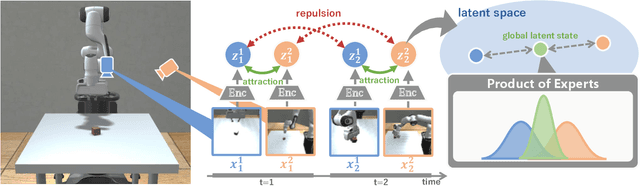
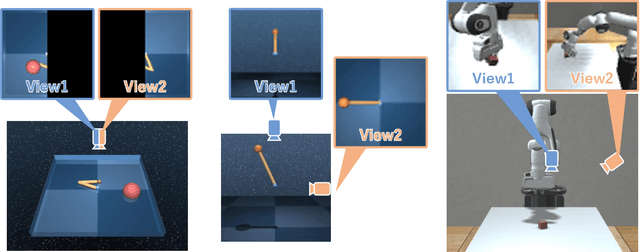
In this paper, we propose Multi-View Dreaming, a novel reinforcement learning agent for integrated recognition and control from multi-view observations by extending Dreaming. Most current reinforcement learning method assumes a single-view observation space, and this imposes limitations on the observed data, such as lack of spatial information and occlusions. This makes obtaining ideal observational information from the environment difficult and is a bottleneck for real-world robotics applications. In this paper, we use contrastive learning to train a shared latent space between different viewpoints, and show how the Products of Experts approach can be used to integrate and control the probability distributions of latent states for multiple viewpoints. We also propose Multi-View DreamingV2, a variant of Multi-View Dreaming that uses a categorical distribution to model the latent state instead of the Gaussian distribution. Experiments show that the proposed method outperforms simple extensions of existing methods in a realistic robot control task.
DreamingV2: Reinforcement Learning with Discrete World Models without Reconstruction
Mar 01, 2022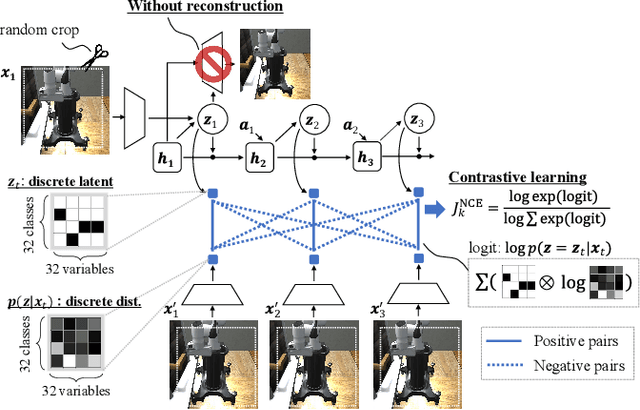
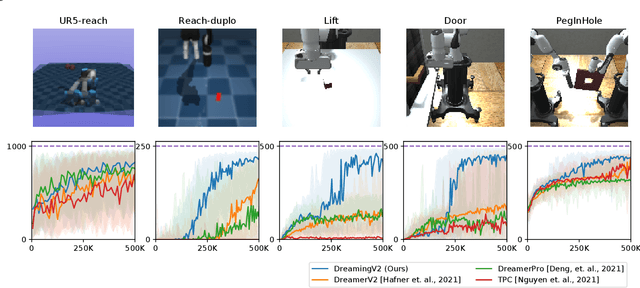
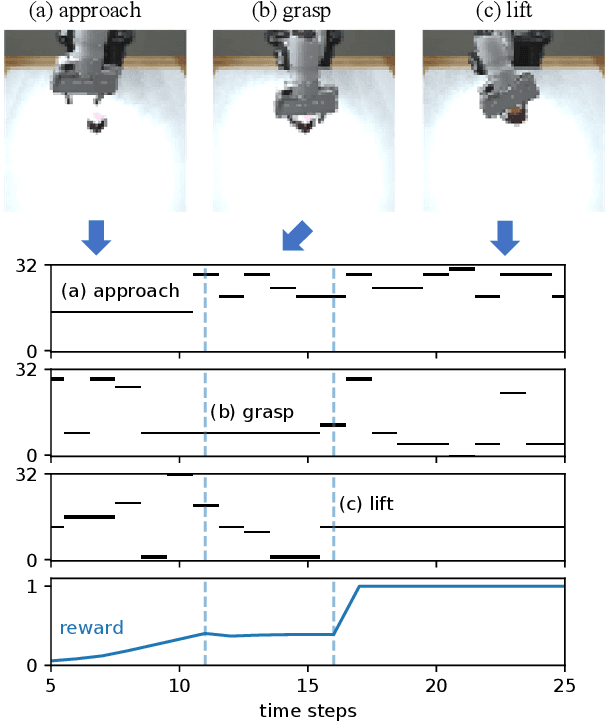
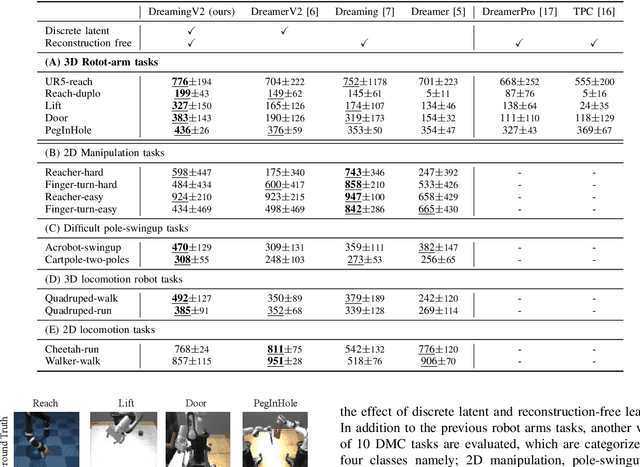
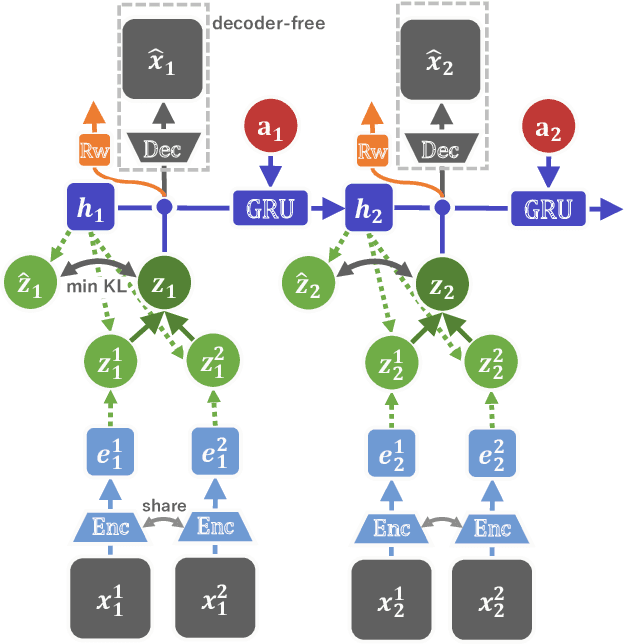
The present paper proposes a novel reinforcement learning method with world models, DreamingV2, a collaborative extension of DreamerV2 and Dreaming. DreamerV2 is a cutting-edge model-based reinforcement learning from pixels that uses discrete world models to represent latent states with categorical variables. Dreaming is also a form of reinforcement learning from pixels that attempts to avoid the autoencoding process in general world model training by involving a reconstruction-free contrastive learning objective. The proposed DreamingV2 is a novel approach of adopting both the discrete representation of DreamingV2 and the reconstruction-free objective of Dreaming. Compared to DreamerV2 and other recent model-based methods without reconstruction, DreamingV2 achieves the best scores on five simulated challenging 3D robot arm tasks. We believe that DreamingV2 will be a reliable solution for robot learning since its discrete representation is suitable to describe discontinuous environments, and the reconstruction-free fashion well manages complex vision observations.
Dreaming: Model-based Reinforcement Learning by Latent Imagination without Reconstruction
Jul 29, 2020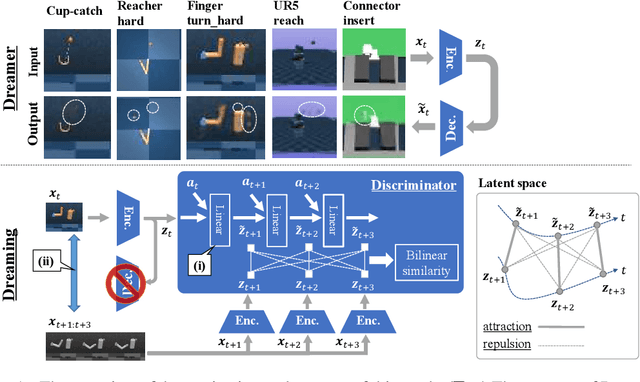
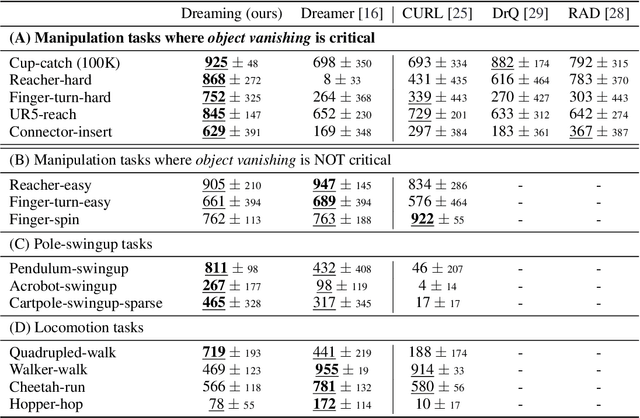

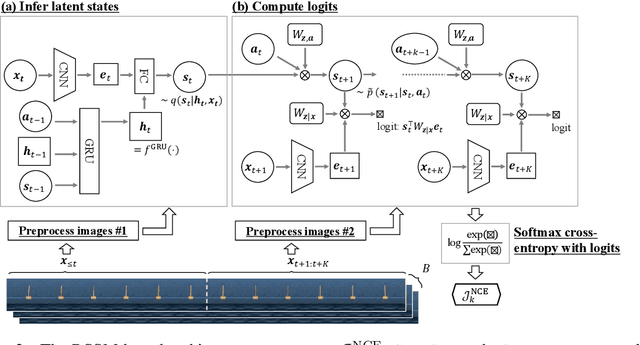
In the present paper, we propose a decoder-free extension of Dreamer, a leading model-based reinforcement learning (MBRL) method from pixels. Dreamer is a sample- and cost-efficient solution to robot learning, as it is used to train latent state-space models based on a variational autoencoder and to conduct policy optimization by latent trajectory imagination. However, this autoencoding based approach often causes object vanishing, in which the autoencoder fails to perceives key objects for solving control tasks, and thus significantly limiting Dreamer's potential. This work aims to relieve this Dreamer's bottleneck and enhance its performance by means of removing the decoder. For this purpose, we firstly derive a likelihood-free and InfoMax objective of contrastive learning from the evidence lower bound of Dreamer. Secondly, we incorporate two components, (i) independent linear dynamics and (ii) the random crop data augmentation, to the learning scheme so as to improve the training performance. In comparison to Dreamer and other recent model-free reinforcement learning methods, our newly devised Dreamer with InfoMax and without generative decoder (Dreaming) achieves the best scores on 5 difficult simulated robotics tasks, in which Dreamer suffers from object vanishing.
PlaNet of the Bayesians: Reconsidering and Improving Deep Planning Network by Incorporating Bayesian Inference
Mar 01, 2020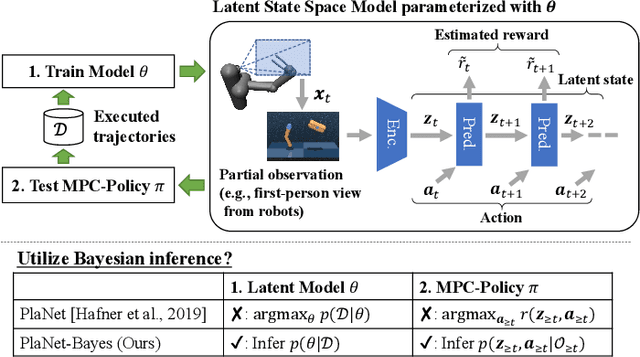
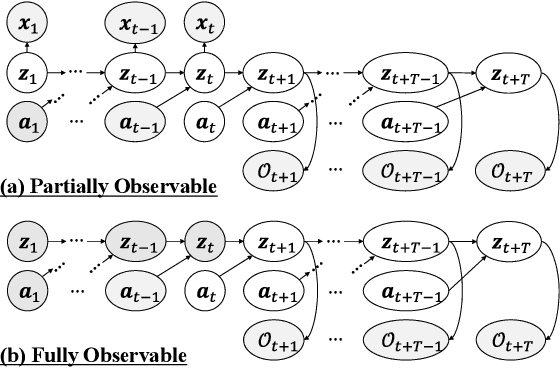
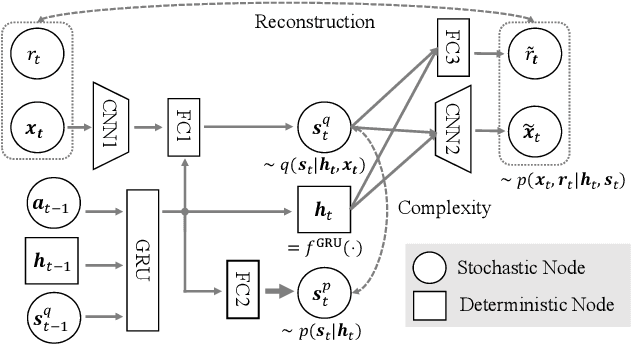
In the present paper, we propose an extension of the Deep Planning Network (PlaNet), also referred to as PlaNet of the Bayesians (PlaNet-Bayes). There has been a growing demand in model predictive control (MPC) in partially observable environments in which complete information is unavailable because of, for example, lack of expensive sensors. PlaNet is a promising solution to realize such latent MPC, as it is used to train state-space models via model-based reinforcement learning (MBRL) and to conduct planning in the latent space. However, recent state-of-the-art strategies mentioned in MBRR literature, such as involving uncertainty into training and planning, have not been considered, significantly suppressing the training performance. The proposed extension is to make PlaNet uncertainty-aware on the basis of Bayesian inference, in which both model and action uncertainty are incorporated. Uncertainty in latent models is represented using a neural network ensemble to approximately infer model posteriors. The ensemble of optimal action candidates is also employed to capture multimodal uncertainty in the optimality. The concept of the action ensemble relies on a general variational inference MPC (VI-MPC) framework and its instance, probabilistic action ensemble with trajectory sampling (PaETS). In this paper, we extend VI-MPC and PaETS, which have been originally introduced in previous literature, to address partially observable cases. We experimentally compare the performances on continuous control tasks, and conclude that our method can consistently improve the asymptotic performance compared with PlaNet.
Domain-Adversarial and -Conditional State Space Model for Imitation Learning
Jan 31, 2020
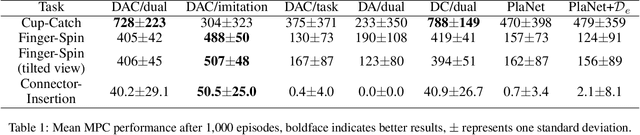
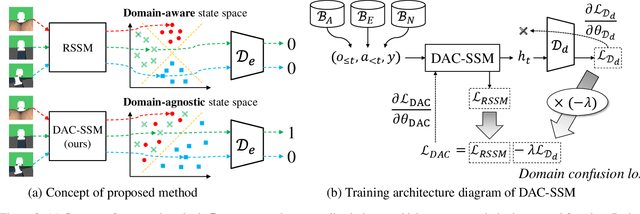

State representation learning (SRL) in partially observable Markov decision processes has been studied to learn abstract features of data useful for robot control tasks. For SRL, acquiring domain-agnostic states is essential for achieving efficient imitation learning (IL). Without these states, IL is hampered by domain-dependent information useless for control. However, existing methods fail to remove such disturbances from the states when the data from experts and agents show large domain shifts. To overcome this issue, we propose a domain-adversarial and -conditional state space model (DAC-SSM) that enables control systems to obtain domain-agnostic and task- and dynamics-aware states. DAC-SSM jointly optimizes the state inference, observation reconstruction, forward dynamics, and reward models. To remove domain-dependent information from the states, the model is trained with domain discriminators in an adversarial manner, and the reconstruction is conditioned on domain labels. We experimentally evaluated the model predictive control performance via IL for continuous control of sparse reward tasks in simulators and compared it with the performance of the existing SRL method. The agents from DAC-SSM achieved performance comparable to experts and more than twice the baselines. We conclude domain-agnostic states are essential for IL that has large domain shifts and can be obtained using DAC-SSM.