 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Word-Level Quality Estimation for Post-Editing Assistance
Sep 23, 2022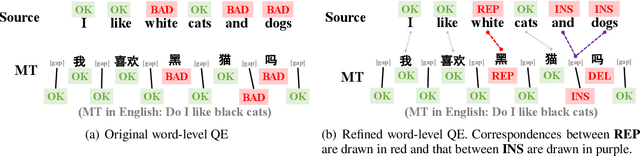
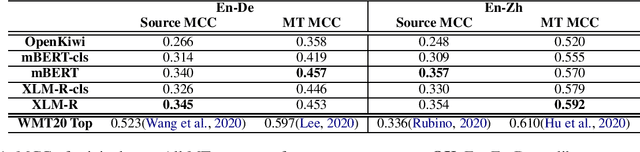


We define a novel concept called extended word alignment in order to improve post-editing assistance efficiency. Based on extended word alignment, we further propose a novel task called refined word-level QE that outputs refined tags and word-level correspondences. Compared to original word-level QE, the new task is able to directly point out editing operations, thus improves efficiency. To extract extended word alignment, we adopt a supervised method based on mBERT. To solve refined word-level QE, we firstly predict original QE tags by training a regression model for sequence tagging based on mBERT and XLM-R. Then, we refine original word tags with extended word alignment. In addition, we extract source-gap correspondences, meanwhile, obtaining gap tags. Experiments on two language pairs show the feasibility of our method and give us inspirations for further improvement.
JParaCrawl v3.0: A Large-scale English-Japanese Parallel Corpus
Feb 28, 2022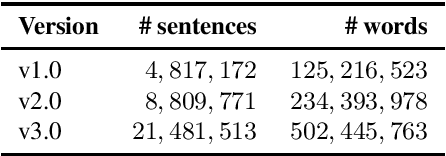

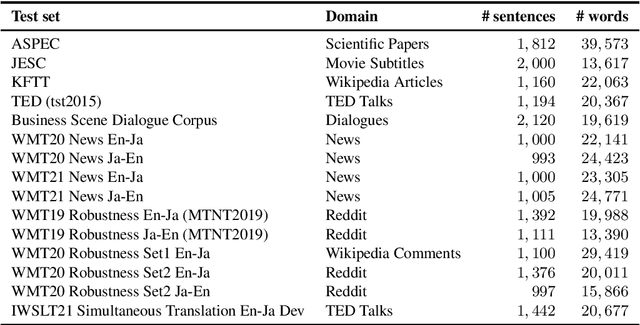
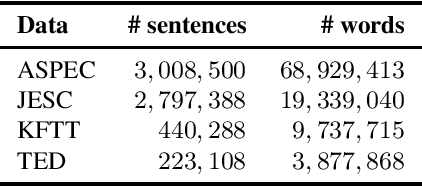
Most current machine translation models are mainly trained with parallel corpora, and their translation accuracy largely depends on the quality and quantity of the corpora. Although there are billions of parallel sentences for a few language pairs, effectively dealing with most language pairs is difficult due to a lack of publicly available parallel corpora. This paper creates a large parallel corpus for English-Japanese, a language pair for which only limited resources are available, compared to such resource-rich languages as English-German. It introduces a new web-based English-Japanese parallel corpus named JParaCrawl v3.0. Our new corpus contains more than 21 million unique parallel sentence pairs, which is more than twice as many as the previous JParaCrawl v2.0 corpus. Through experiments, we empirically show how our new corpus boosts the accuracy of machine translation models on various domains. The JParaCrawl v3.0 corpus will eventually be publicly available online for research purposes.
Bilingual Text Extraction as Reading Comprehension
Apr 29, 2020
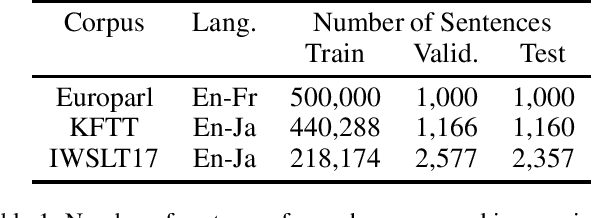
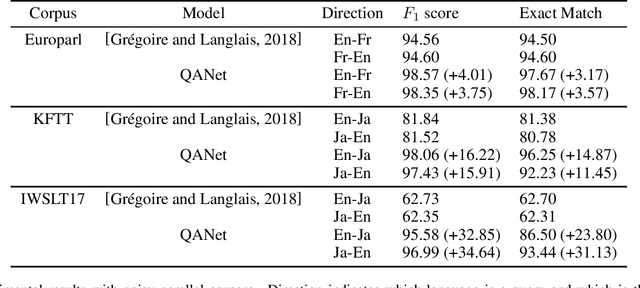

In this paper, we propose a method to extract bilingual texts automatically from noisy parallel corpora by framing the problem as a token-level span prediction, such as SQuAD-style Reading Comprehension. To extract a span of the target document that is a translation of a given source sentence (span), we use either QANet or multilingual BERT. QANet can be trained for a specific parallel corpus from scratch, while multilingual BERT can utilize pre-trained multilingual representations. For the span prediction method using QANet, we introduce a total optimization method using integer linear programming to achieve consistency in the predicted parallel spans. We conduct a parallel sentence extraction experiment using simulated noisy parallel corpora with two language pairs (En-Fr and En-Ja) and find that the proposed method using QANet achieves significantly better accuracy than a baseline method using two bi-directional RNN encoders, particularly for distant language pairs (En-Ja). We also conduct a sentence alignment experiment using En-Ja newspaper articles and find that the proposed method using multilingual BERT achieves significantly better accuracy than a baseline method using a bilingual dictionary and dynamic programming.
A Supervised Word Alignment Method based on Cross-Language Span Prediction using Multilingual BERT
Apr 29, 2020



We present a novel supervised word alignment method based on cross-language span prediction. We first formalize a word alignment problem as a collection of independent predictions from a token in the source sentence to a span in the target sentence. As this is equivalent to a SQuAD v2.0 style question answering task, we then solve this problem by using multilingual BERT, which is fine-tuned on a manually created gold word alignment data. We greatly improved the word alignment accuracy by adding the context of the token to the question. In the experiments using five word alignment datasets among Chinese, Japanese, German, Romanian, French, and English, we show that the proposed method significantly outperformed previous supervised and unsupervised word alignment methods without using any bitexts for pretraining. For example, we achieved an F1 score of 86.7 for the Chinese-English data, which is 13.3 points higher than the previous state-of-the-art supervised methods.
JParaCrawl: A Large Scale Web-Based English-Japanese Parallel Corpus
Nov 25, 2019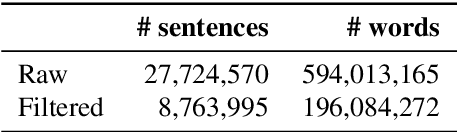

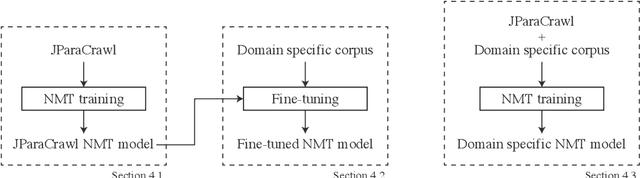
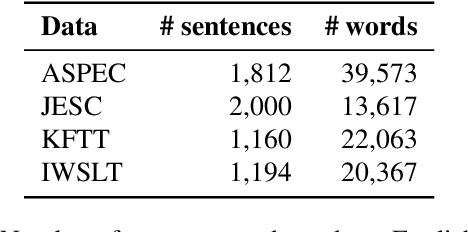
Recent machine translation algorithms mainly rely on parallel corpora. However, since the availability of parallel corpora remains limited, only some resource-rich language pairs can benefit from them. In this paper, we constructed a parallel corpus for English-Japanese, where the amount of publicly available parallel corpora is still limited. We constructed a parallel corpus by broadly crawling the web and automatically aligning parallel sentences. Our collected corpus, called JParaCrawl, amassed over 8.7 million sentence pairs. We show how it includes broader domains, and the NMT model trained with it works as a good pre-trained model for fine-tuning specific domains. The pre-training and fine-tuning approaches surpassed or achieved comparable performance to the model training from the initial state and largely reduced the training cost. Additionally, we trained the model with an in-domain dataset and JParaCrawl to show how we achieved the best performance with them. JParaCrawl and the pre-trained models are freely available online for research purposes.
NTT's Machine Translation Systems for WMT19 Robustness Task
Jul 09, 2019
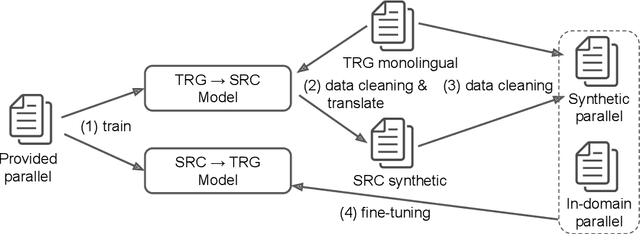
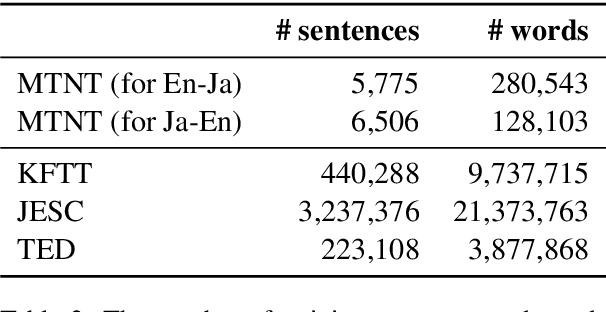
This paper describes NTT's submission to the WMT19 robustness task. This task mainly focuses on translating noisy text (e.g., posts on Twitter), which presents different difficulties from typical translation tasks such as news. Our submission combined techniques including utilization of a synthetic corpus, domain adaptation, and a placeholder mechanism, which significantly improved over the previous baseline. Experimental results revealed the placeholder mechanism, which temporarily replaces the non-standard tokens including emojis and emoticons with special placeholder tokens during translation, improves translation accuracy even with noisy texts.
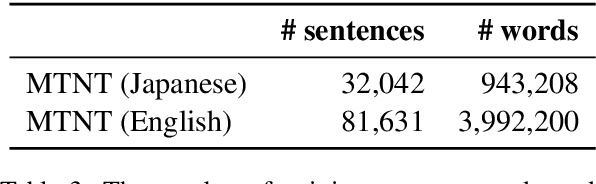
Character n-gram Embeddings to Improve RNN Language Models
Jun 13, 2019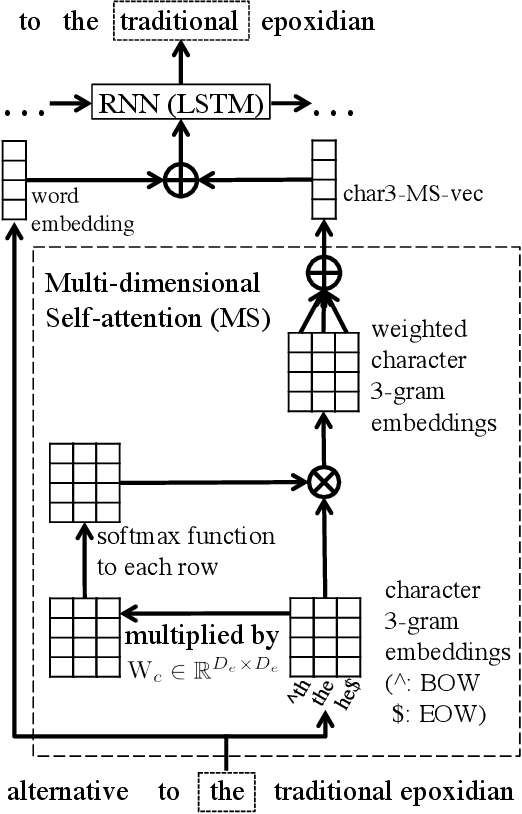
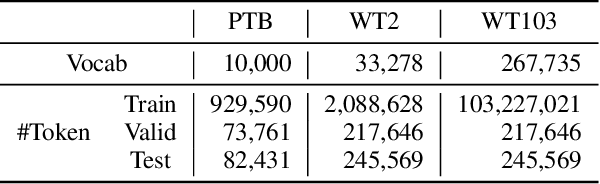
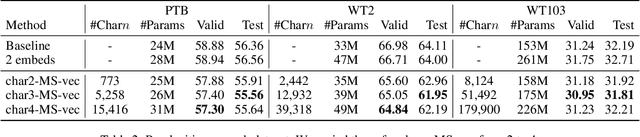
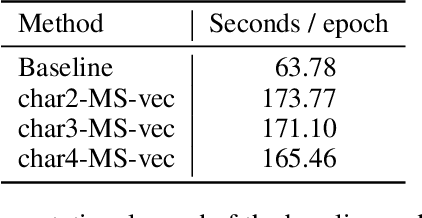
This paper proposes a novel Recurrent Neural Network (RNN) language model that takes advantage of character information. We focus on character n-grams based on research in the field of word embedding construction (Wieting et al. 2016). Our proposed method constructs word embeddings from character n-gram embeddings and combines them with ordinary word embeddings. We demonstrate that the proposed method achieves the best perplexities on the language modeling datasets: Penn Treebank, WikiText-2, and WikiText-103. Moreover, we conduct experiments on application tasks: machine translation and headline generation. The experimental results indicate that our proposed method also positively affects these tasks.
Answering while Summarizing: Multi-task Learning for Multi-hop QA with Evidence Extraction
May 29, 2019
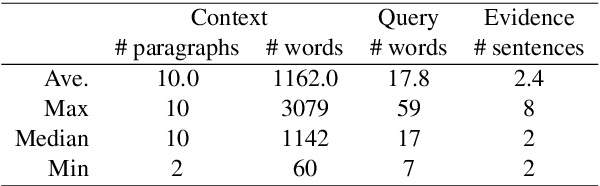
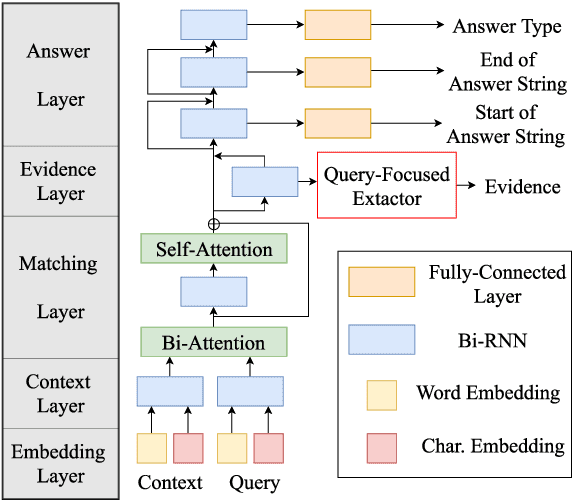
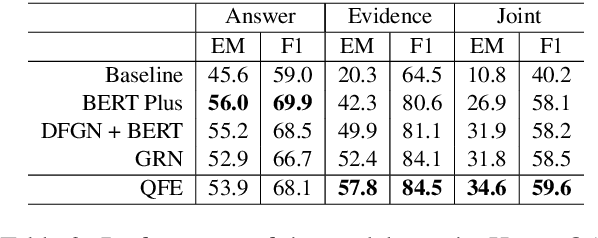
Question answering (QA) using textual sources for purposes such as reading comprehension (RC) has attracted much attention. This study focuses on the task of explainable multi-hop QA, which requires the system to return the answer with evidence sentences by reasoning and gathering disjoint pieces of the reference texts. It proposes the Query Focused Extractor (QFE) model for evidence extraction and uses multi-task learning with the QA model. QFE is inspired by extractive summarization models; compared with the existing method, which extracts each evidence sentence independently, it sequentially extracts evidence sentences by using an RNN with an attention mechanism on the question sentence. It enables QFE to consider the dependency among the evidence sentences and cover important information in the question sentence. Experimental results show that QFE with a simple RC baseline model achieves a state-of-the-art evidence extraction score on HotpotQA. Although designed for RC, it also achieves a state-of-the-art evidence extraction score on FEVER, which is a recognizing textual entailment task on a large textual database.
Direct Output Connection for a High-Rank Language Model
Aug 31, 2018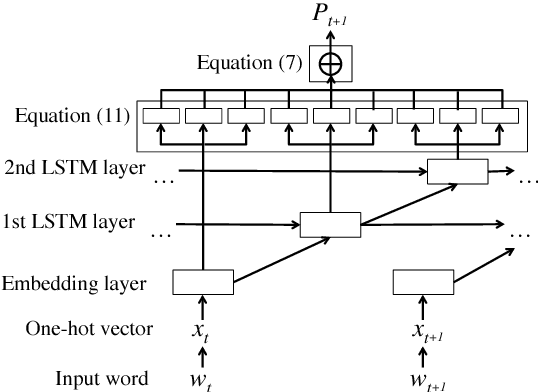
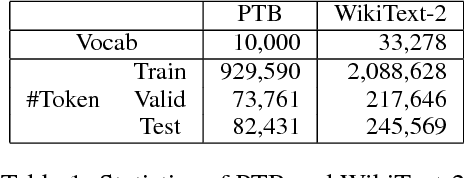
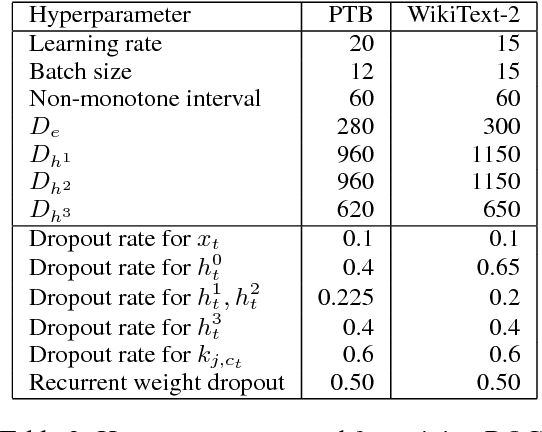
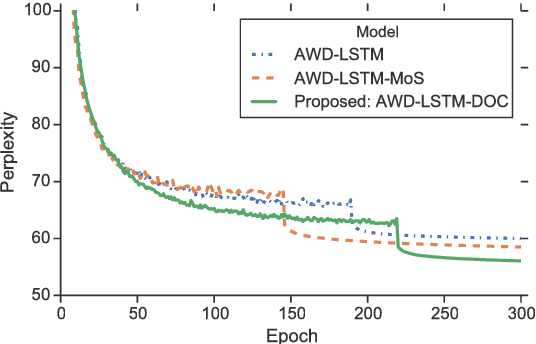
This paper proposes a state-of-the-art recurrent neural network (RNN) language model that combines probability distributions computed not only from a final RNN layer but also from middle layers. Our proposed method raises the expressive power of a language model based on the matrix factorization interpretation of language modeling introduced by Yang et al. (2018). The proposed method improves the current state-of-the-art language model and achieves the best score on the Penn Treebank and WikiText-2, which are the standard benchmark datasets. Moreover, we indicate our proposed method contributes to two application tasks: machine translation and headline generation. Our code is publicly available at: https://github.com/nttcslab-nlp/doc_lm.
Source-side Prediction for Neural Headline Generation
Dec 22, 2017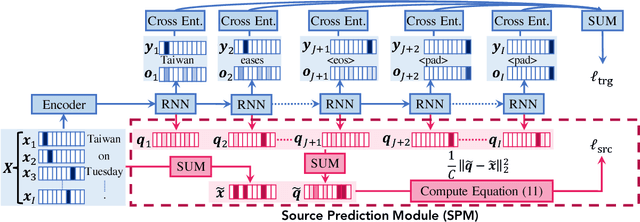

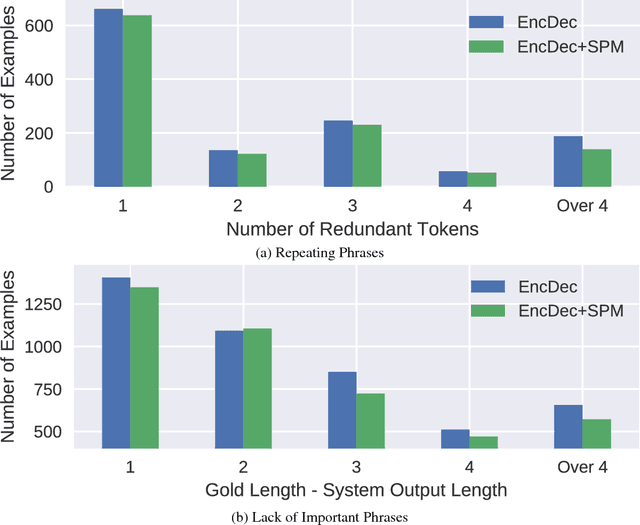
The encoder-decoder model is widely used in natural language generation tasks. However, the model sometimes suffers from repeated redundant generation, misses important phrases, and includes irrelevant entities. Toward solving these problems we propose a novel source-side token prediction module. Our method jointly estimates the probability distributions over source and target vocabularies to capture a correspondence between source and target tokens. The experiments show that the proposed model outperforms the current state-of-the-art method in the headline generation task. Additionally, we show that our method has an ability to learn a reasonable token-wise correspondence without knowing any true alignments.