 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Ontology Generation from Unstructured Text: A Multi-Agent LLM Approach
Apr 25, 2026Automatically generating formal ontologies from unstructured natural language remains a central challenge in knowledge engineering. While large language models (LLMs) show promise, it remains unclear which architectural design choices drive generation quality and why current approaches fail. We present a controlled experimental study using domain-specific insurance contracts to investigate these questions. We first establish a single-agent LLM baseline, identifying key failure modes such as poor Ontology Design Pattern compliance, structural redundancy, and ineffective iterative repair. We then introduce a multi-agent architecture that decomposes ontology construction into four artifact-driven roles: Domain Expert, Manager, Coder, and Quality Assurer. We evaluate performance across architectural quality (via a panel of heterogeneous LLM judges) and functional usability (via competency question driven SPARQL evaluation with complementary retrieval augmented generation based assessment). Results show that the multi-agent approach significantly improves structural quality and modestly enhances queryability, with gains driven primarily by front-loaded planning. These findings highlight planning-first, artifact-driven generation as a promising and more auditable path toward scalable automated ontology engineering.
A Benchmark for Gap and Overlap Analysis as a Test of KG Task Readiness
Apr 12, 2026Task-oriented evaluation of knowledge graph (KG) quality increasingly asks whether an ontology-based representation can answer the competency questions that users actually care about, in a manner that is reproducible, explainable, and traceable to evidence. This paper adopts that perspective and focuses on gap and overlap analysis for policy-like documents (e.g., insurance contracts), where given a scenario, which documents support it (overlap) and which do not (gap), with defensible justifications. The resulting gap/overlap determinations are typically driven by genuine differences in coverage and restrictions rather than missing data, making the task a direct test of KG task readiness rather than a test of missing facts or query expressiveness. We present an executable and auditable benchmark that aligns natural-language contract text with a formal ontology and evidence-linked ground truth, enabling systematic comparison of methods. The benchmark includes: (i) ten simplified yet diverse life-insurance contracts reviewed by a domain expert, (ii) a domain ontology (TBox) with an instantiated knowledge base (ABox) populated from contract facts, and (iii) 58 structured scenarios paired with SPARQL queries with contract-level outcomes and clause-level excerpts that justify each label. Using this resource, we compare a text-only LLM baseline that infers outcomes directly from contract text against an ontology-driven pipeline that answers the same scenarios over the instantiated KG, demonstrating that explicit modeling improves consistency and diagnosis for gap/overlap analyses. Although demonstrated for gap and overlap analysis, the benchmark is intended as a reusable template for evaluating KG quality and supporting downstream work such as ontology learning, KG population, and evidence-grounded question answering.
Terminators: Terms of Service Parsing and Auditing Agents
May 16, 2025
Terms of Service (ToS) documents are often lengthy and written in complex legal language, making them difficult for users to read and understand. To address this challenge, we propose Terminators, a modular agentic framework that leverages large language models (LLMs) to parse and audit ToS documents. Rather than treating ToS understanding as a black-box summarization problem, Terminators breaks the task down to three interpretable steps: term extraction, verification, and accountability planning. We demonstrate the effectiveness of our method on the OpenAI ToS using GPT-4o, highlighting strategies to minimize hallucinations and maximize auditability. Our results suggest that structured, agent-based LLM workflows can enhance both the usability and enforceability of complex legal documents. By translating opaque terms into actionable, verifiable components, Terminators promotes ethical use of web content by enabling greater transparency, empowering users to understand their digital rights, and supporting automated policy audits for regulatory or civic oversight.
Presenting a Larger Up-to-date Movie Dataset and Investigating the Effects of Pre-released Attributes on Gross Revenue
Oct 13, 2021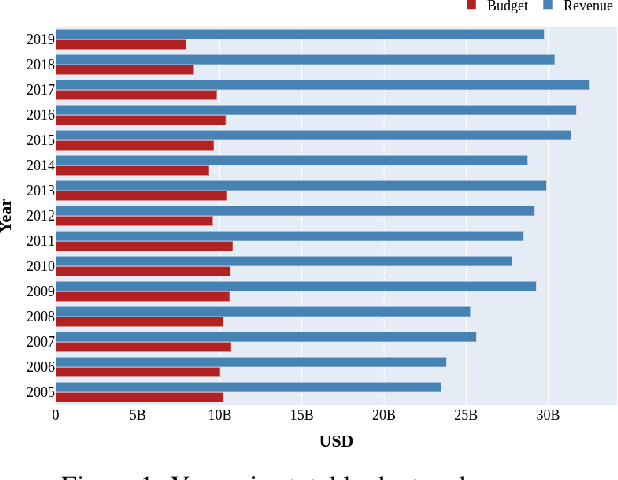
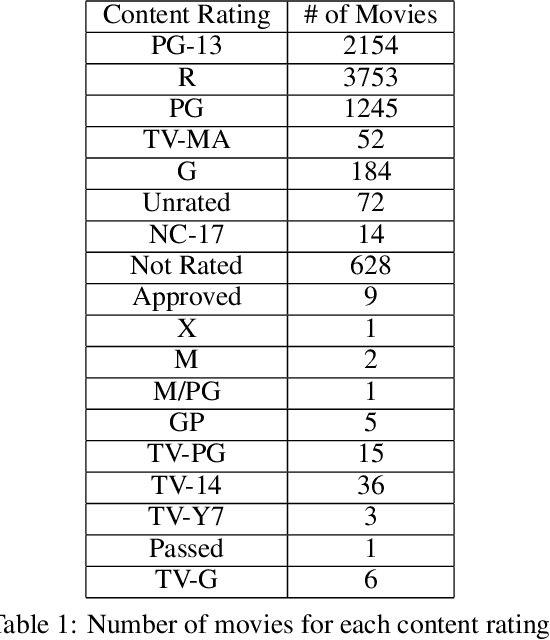
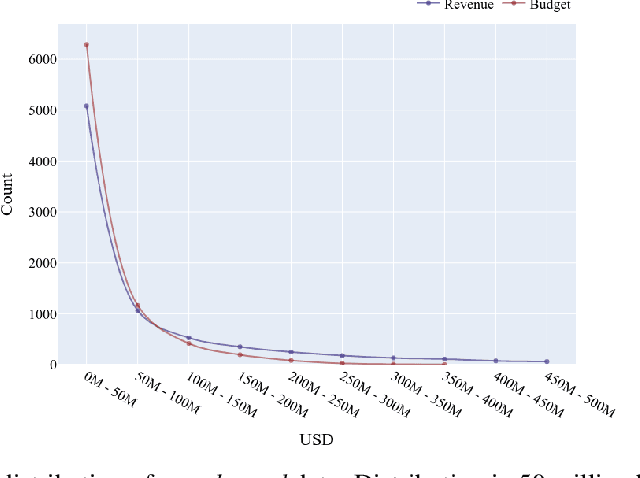
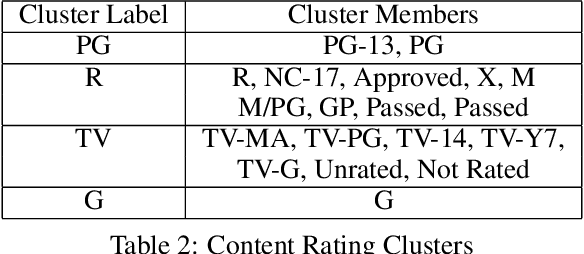
Movie-making has become one of the most costly and risky endeavors in the entertainment industry. Continuous change in the preference of the audience makes it harder to predict what kind of movie will be financially successful at the box office. So, it is no wonder that cautious, intelligent stakeholders and large production houses will always want to know the probable revenue that will be generated by a movie before making an investment. Researchers have been working on finding an optimal strategy to help investors in making the right decisions. But the lack of a large, up-to-date dataset makes their work harder. In this work, we introduce an up-to-date, richer, and larger dataset that we have prepared by scraping IMDb for researchers and data analysts to work with. The compiled dataset contains the summery data of 7.5 million titles and detail information of more than 200K movies. Additionally, we perform different statistical analysis approaches on our dataset to find out how a movie's revenue is affected by different pre-released attributes such as budget, runtime, release month, content rating, genre etc. In our analysis, we have found that having a star cast/director has a positive impact on generated revenue. We introduce a novel approach for calculating the star power of a movie. Based on our analysis we select a set of attributes as features and train different machine learning algorithms to predict a movie's expected revenue. Based on generated revenue, we classified the movies in 10 categories and achieved a one-class-away accuracy rate of almost 60% (bingo accuracy of 30%). All the generated datasets and analysis codes are available online. We also made the source codes of our scraper bots public, so that researchers interested in extending this work can easily modify these bots as they need and prepare their own up-to-date datasets.
Automatic Detection of Satire in Bangla Documents: A CNN Approach Based on Hybrid Feature Extraction Model
Nov 19, 2019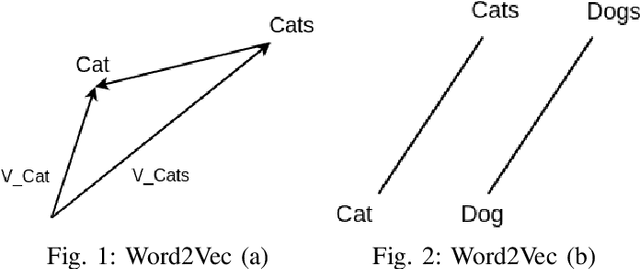
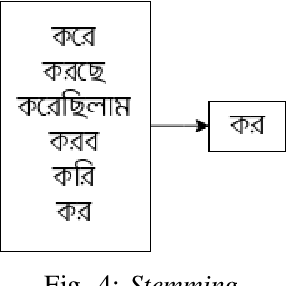
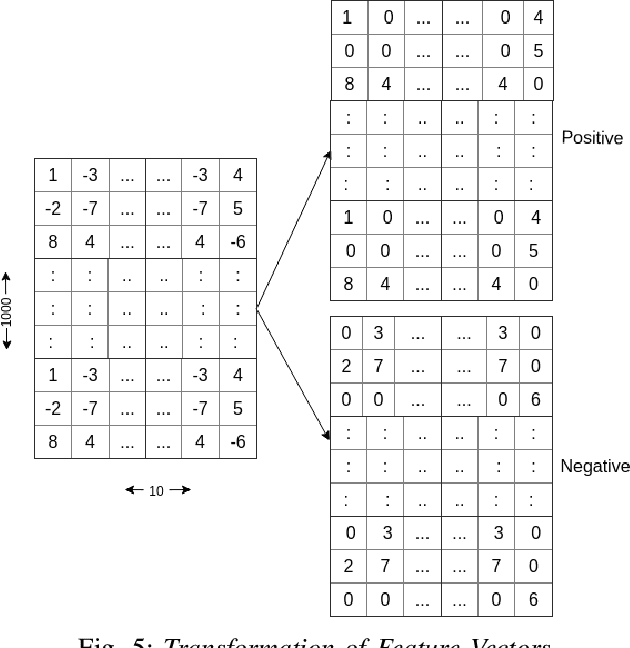
Widespread of satirical news in online communities is an ongoing trend. The nature of satires is so inherently ambiguous that sometimes it's too hard even for humans to understand whether it's actually satire or not. So, research interest has grown in this field. The purpose of this research is to detect Bangla satirical news spread in online news portals as well as social media. In this paper, we propose a hybrid technique for extracting features from text documents combining Word2Vec and TF-IDF. Using our proposed feature extraction technique, with standard CNN architecture we could detect whether a Bangla text document is satire or not with an accuracy of more than 96%.