 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemlr3torch: A Deep Learning Framework in R based on mlr3 and torch
Apr 20, 2026Deep learning (DL) has become a cornerstone of modern machine learning (ML) praxis. We introduce the R package mlr3torch, which is an extensible DL framework for the mlr3 ecosystem. It is built upon the torch package, and simplifies the definition, training, and evaluation of neural networks for both tabular data and generic tensors (e.g., images) for classification and regression. The package implements predefined architectures, and torch models can easily be converted to mlr3 learners. It also allows users to define neural networks as graphs. This representation is based on the graph language defined in mlr3pipelines and allows users to define the entire modeling workflow, including preprocessing, data augmentation, and network architecture, in a single graph. Through its integration into the mlr3 ecosystem, the package allows for convenient resampling, benchmarking, preprocessing, and more. We explain the package's design and features and show how to customize and extend it to new problems. Furthermore, we demonstrate the package's capabilities using three use cases, namely hyperparameter tuning, fine-tuning, and defining architectures for multimodal data. Finally, we present some runtime benchmarks.
mlr3mbo: Bayesian Optimization in R
Mar 31, 2026We present mlr3mbo, a comprehensive and modular toolbox for Bayesian optimization in R. mlr3mbo supports single- and multi-objective optimization, multi-point proposals, batch and asynchronous parallelization, input and output transformations, and robust error handling. While it can be used for many standard Bayesian optimization variants in applied settings, researchers can also construct custom BO algorithms from its flexible building blocks. In addition to an introduction to the software, its design principles, and its building blocks, the paper presents two extensive empirical evaluations of the software on the surrogate-based benchmark suite YAHPO Gym. To identify robust default configurations for both numeric and mixed-hierarchical optimization regimes, and to gain further insights into the respective impacts of individual settings, we run a coordinate descent search over the mlr3mbo configuration space and analyze its results. Furthermore, we demonstrate that mlr3mbo achieves state-of-the-art performance by benchmarking it against a wide range of optimizers, including HEBO, SMAC3, Ax, and Optuna.
CASHomon Sets: Efficient Rashomon Sets Across Multiple Model Classes and their Hyperparameters
Mar 16, 2026Rashomon sets are model sets within one model class that perform nearly as well as a reference model from the same model class. They reveal the existence of alternative well-performing models, which may support different interpretations. This enables selecting models that match domain knowledge, hidden constraints, or user preferences. However, efficient construction methods currently exist for only a few model classes. Applied machine learning usually searches many model classes, and the best class is unknown beforehand. We therefore study Rashomon sets in the combined algorithm selection and hyperparameter optimization (CASH) setting and call them CASHomon sets. We propose TruVaRImp, a model-based active learning algorithm for level set estimation with an implicit threshold, and provide convergence guarantees. On synthetic and real-world datasets, TruVaRImp reliably identifies CASHomon sets members and matches or outperforms naive sampling, Bayesian optimization, classical and implicit level set estimation methods, and other baselines. Our analyses of predictive multiplicity and feature-importance variability across model classes question the common practice of interpreting data through a single model class.
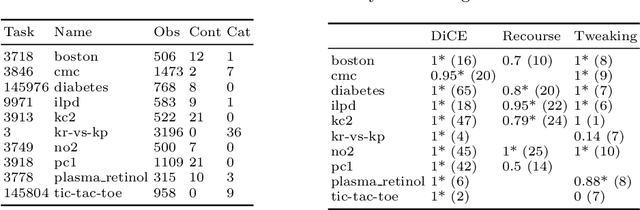
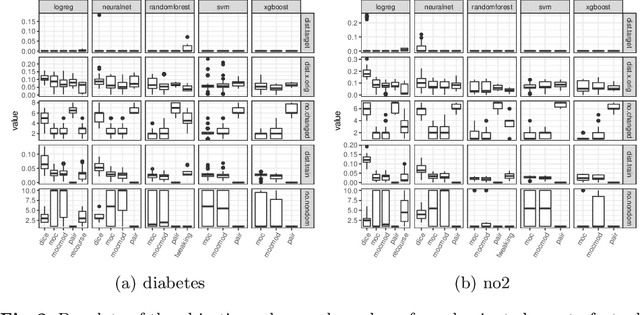
counterfactuals: An R Package for Counterfactual Explanation Methods
Apr 13, 2023Counterfactual explanation methods provide information on how feature values of individual observations must be changed to obtain a desired prediction. Despite the increasing amount of proposed methods in research, only a few implementations exist whose interfaces and requirements vary widely. In this work, we introduce the counterfactuals R package, which provides a modular and unified R6-based interface for counterfactual explanation methods. We implemented three existing counterfactual explanation methods and propose some optional methodological extensions to generalize these methods to different scenarios and to make them more comparable. We explain the structure and workflow of the package using real use cases and show how to integrate additional counterfactual explanation methods into the package. In addition, we compared the implemented methods for a variety of models and datasets with regard to the quality of their counterfactual explanations and their runtime behavior.
Multi-Objective Hyperparameter Optimization -- An Overview
Jun 15, 2022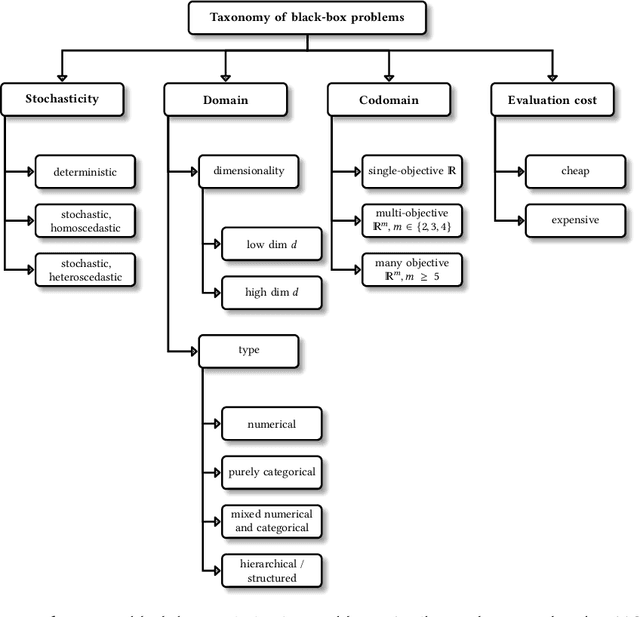
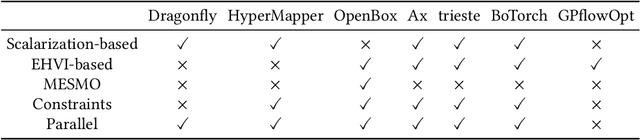
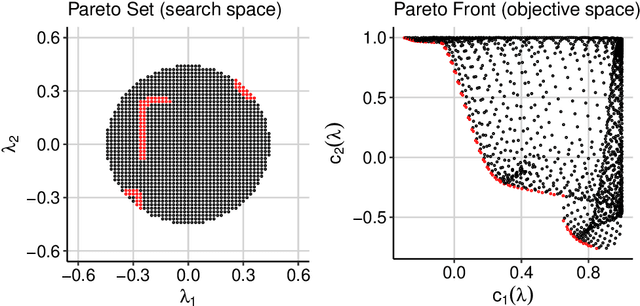
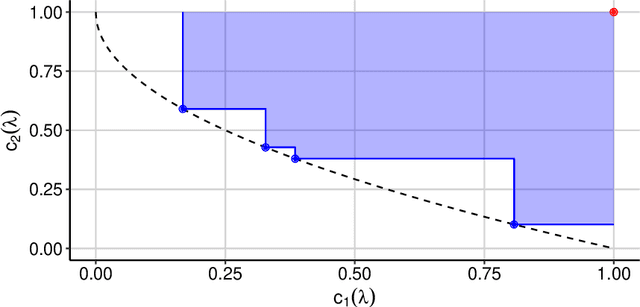
Hyperparameter optimization constitutes a large part of typical modern machine learning workflows. This arises from the fact that machine learning methods and corresponding preprocessing steps often only yield optimal performance when hyperparameters are properly tuned. But in many applications, we are not only interested in optimizing ML pipelines solely for predictive accuracy; additional metrics or constraints must be considered when determining an optimal configuration, resulting in a multi-objective optimization problem. This is often neglected in practice, due to a lack of knowledge and readily available software implementations for multi-objective hyperparameter optimization. In this work, we introduce the reader to the basics of multi- objective hyperparameter optimization and motivate its usefulness in applied ML. Furthermore, we provide an extensive survey of existing optimization strategies, both from the domain of evolutionary algorithms and Bayesian optimization. We illustrate the utility of MOO in several specific ML applications, considering objectives such as operating conditions, prediction time, sparseness, fairness, interpretability and robustness.
Automated Benchmark-Driven Design and Explanation of Hyperparameter Optimizers
Nov 29, 2021
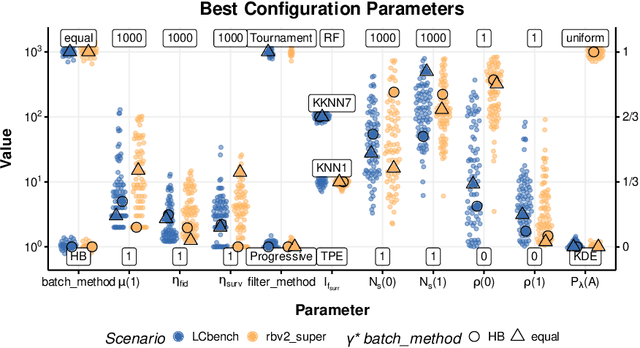

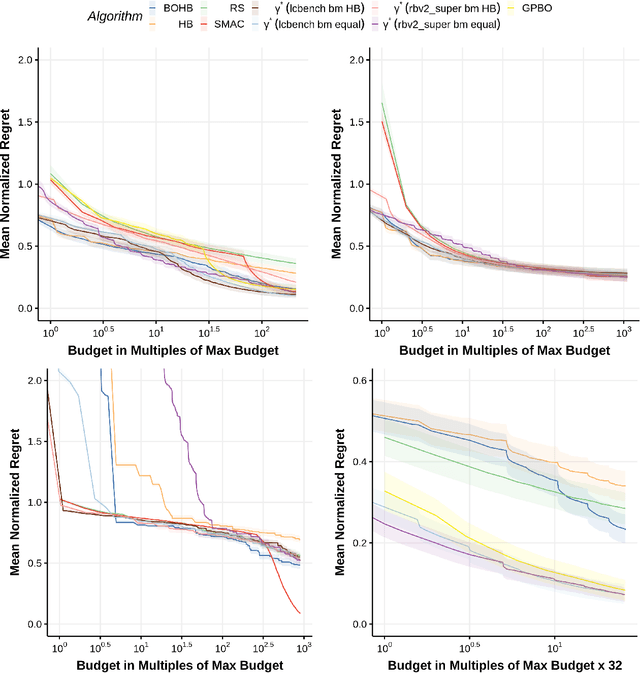
Automated hyperparameter optimization (HPO) has gained great popularity and is an important ingredient of most automated machine learning frameworks. The process of designing HPO algorithms, however, is still an unsystematic and manual process: Limitations of prior work are identified and the improvements proposed are -- even though guided by expert knowledge -- still somewhat arbitrary. This rarely allows for gaining a holistic understanding of which algorithmic components are driving performance, and carries the risk of overlooking good algorithmic design choices. We present a principled approach to automated benchmark-driven algorithm design applied to multifidelity HPO (MF-HPO): First, we formalize a rich space of MF-HPO candidates that includes, but is not limited to common HPO algorithms, and then present a configurable framework covering this space. To find the best candidate automatically and systematically, we follow a programming-by-optimization approach and search over the space of algorithm candidates via Bayesian optimization. We challenge whether the found design choices are necessary or could be replaced by more naive and simpler ones by performing an ablation analysis. We observe that using a relatively simple configuration, in some ways simpler than established methods, performs very well as long as some critical configuration parameters have the right value.
YAHPO Gym -- Design Criteria and a new Multifidelity Benchmark for Hyperparameter Optimization
Sep 08, 2021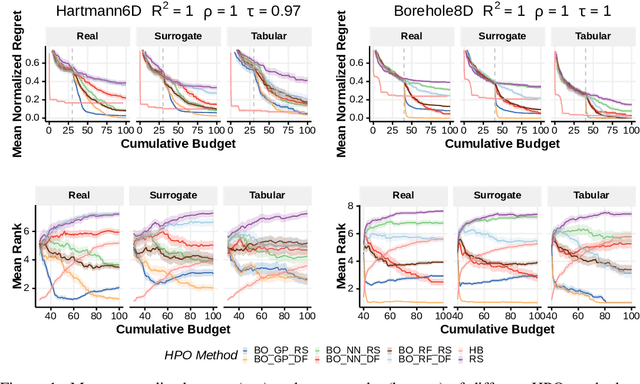

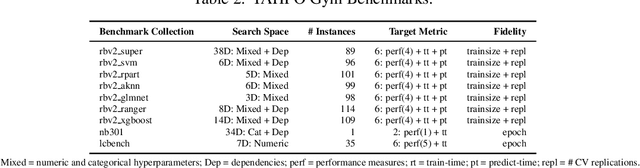
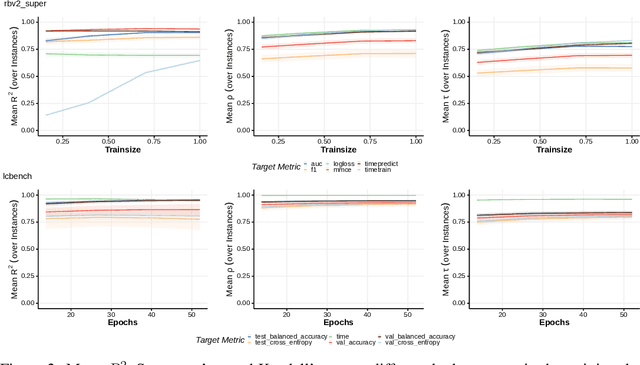
When developing and analyzing new hyperparameter optimization (HPO) methods, it is vital to empirically evaluate and compare them on well-curated benchmark suites. In this work, we list desirable properties and requirements for such benchmarks and propose a new set of challenging and relevant multifidelity HPO benchmark problems motivated by these requirements. For this, we revisit the concept of surrogate-based benchmarks and empirically compare them to more widely-used tabular benchmarks, showing that the latter ones may induce bias in performance estimation and ranking of HPO methods. We present a new surrogate-based benchmark suite for multifidelity HPO methods consisting of 9 benchmark collections that constitute over 700 multifidelity HPO problems in total. All our benchmarks also allow for querying of multiple optimization targets, enabling the benchmarking of multi-objective HPO. We examine and compare our benchmark suite with respect to the defined requirements and show that our benchmarks provide viable additions to existing suites.
Hyperparameter Optimization: Foundations, Algorithms, Best Practices and Open Challenges
Jul 14, 2021
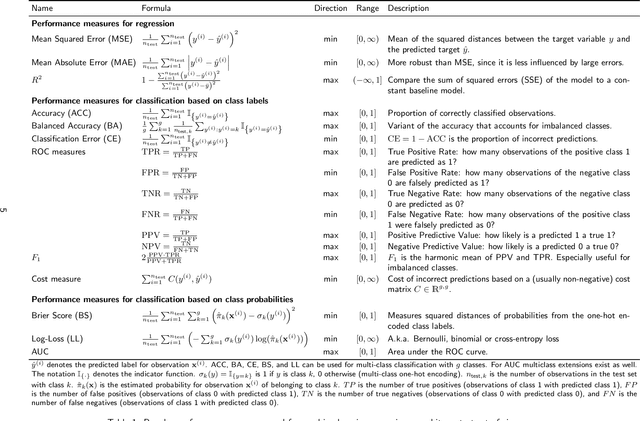
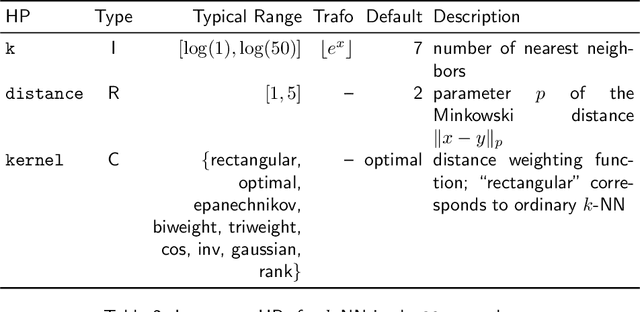
Most machine learning algorithms are configured by one or several hyperparameters that must be carefully chosen and often considerably impact performance. To avoid a time consuming and unreproducible manual trial-and-error process to find well-performing hyperparameter configurations, various automatic hyperparameter optimization (HPO) methods, e.g., based on resampling error estimation for supervised machine learning, can be employed. After introducing HPO from a general perspective, this paper reviews important HPO methods such as grid or random search, evolutionary algorithms, Bayesian optimization, Hyperband and racing. It gives practical recommendations regarding important choices to be made when conducting HPO, including the HPO algorithms themselves, performance evaluation, how to combine HPO with ML pipelines, runtime improvements, and parallelization.
Mutation is all you need
Jul 04, 2021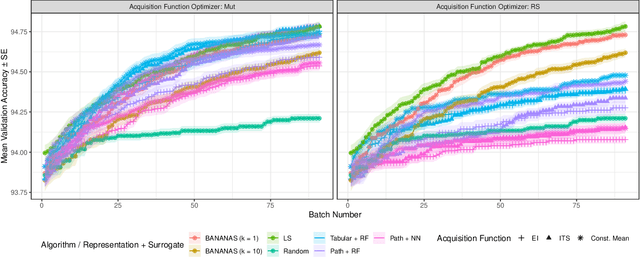
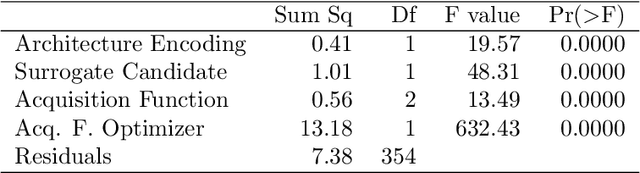
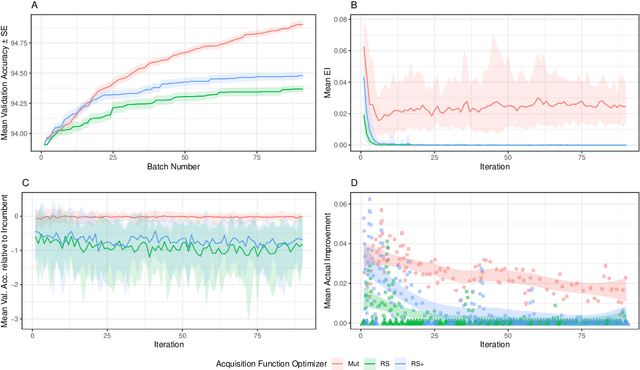
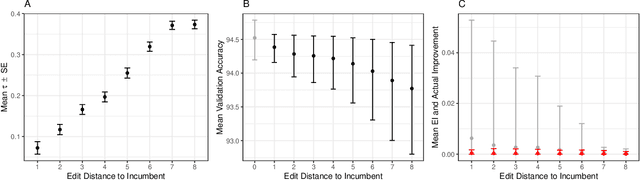
Neural architecture search (NAS) promises to make deep learning accessible to non-experts by automating architecture engineering of deep neural networks. BANANAS is one state-of-the-art NAS method that is embedded within the Bayesian optimization framework. Recent experimental findings have demonstrated the strong performance of BANANAS on the NAS-Bench-101 benchmark being determined by its path encoding and not its choice of surrogate model. We present experimental results suggesting that the performance of BANANAS on the NAS-Bench-301 benchmark is determined by its acquisition function optimizer, which minimally mutates the incumbent.
Multi-Objective Counterfactual Explanations
Apr 23, 2020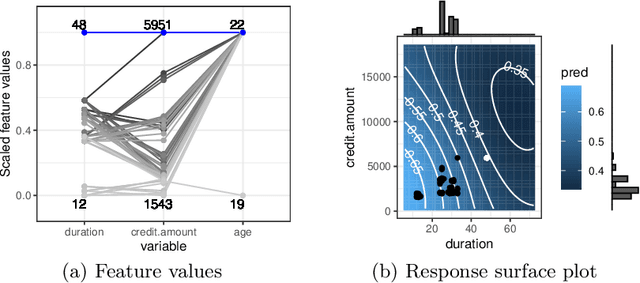
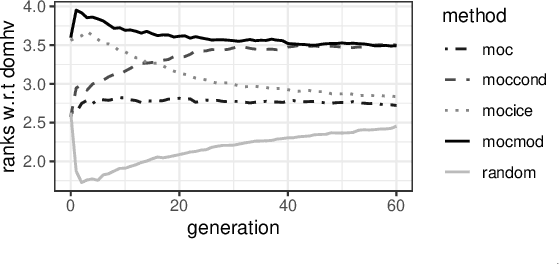
Counterfactual explanations are one of the most popular methods to make predictions of black box machine learning models interpretable by providing explanations in the form of `what-if scenarios'. Current approaches can compute counterfactuals only for certain model classes or feature types, or they generate counterfactuals that are not consistent with the observed data distribution. To overcome these limitations, we propose the Multi-Objective Counterfactuals (MOC) method, which translates the counterfactual search into a multi-objective optimization problem and solves it with a genetic algorithm based on NSGA-II. It returns a diverse set of counterfactuals with different trade-offs between the proposed objectives, enabling either a more detailed post-hoc analysis to facilitate better understanding or more options for actionable user responses to change the predicted outcome. We show the usefulness of MOC in concrete cases and compare our approach with state-of-the-art methods for counterfactual explanations.