 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Probabilistic and Causal Inference using Tractable Circuit Models
Apr 17, 2023



Probabilistic circuits (PCs) are a class of tractable probabilistic models, which admit efficient inference routines depending on their structural properties. In this paper, we introduce md-vtrees, a novel structural formulation of (marginal) determinism in structured decomposable PCs, which generalizes previously proposed classes such as probabilistic sentential decision diagrams. Crucially, we show how mdvtrees can be used to derive tractability conditions and efficient algorithms for advanced inference queries expressed as arbitrary compositions of basic probabilistic operations, such as marginalization, multiplication and reciprocals, in a sound and generalizable manner. In particular, we derive the first polytime algorithms for causal inference queries such as backdoor adjustment on PCs. As a practical instantiation of the framework, we propose MDNets, a novel PC architecture using md-vtrees, and empirically demonstrate their application to causal inference.
Bayesian Network Models of Causal Interventions in Healthcare Decision Making: Literature Review and Software Evaluation
Nov 28, 2022



This report summarises the outcomes of a systematic literature search to identify Bayesian network models used to support decision making in healthcare. After describing the search methodology, the selected research papers are briefly reviewed, with the view to identify publicly available models and datasets that are well suited to analysis using the causal interventional analysis software tool developed in Wang B, Lyle C, Kwiatkowska M (2021). Finally, an experimental evaluation of applying the software on a selection of models is carried out and preliminary results are reported.
When are Local Queries Useful for Robust Learning?
Oct 12, 2022

Distributional assumptions have been shown to be necessary for the robust learnability of concept classes when considering the exact-in-the-ball robust risk and access to random examples by Gourdeau et al. (2019). In this paper, we study learning models where the learner is given more power through the use of local queries, and give the first distribution-free algorithms that perform robust empirical risk minimization (ERM) for this notion of robustness. The first learning model we consider uses local membership queries (LMQ), where the learner can query the label of points near the training sample. We show that, under the uniform distribution, LMQs do not increase the robustness threshold of conjunctions and any superclass, e.g., decision lists and halfspaces. Faced with this negative result, we introduce the local equivalence query (LEQ) oracle, which returns whether the hypothesis and target concept agree in the perturbation region around a point in the training sample, as well as a counterexample if it exists. We show a separation result: on one hand, if the query radius $\lambda$ is strictly smaller than the adversary's perturbation budget $\rho$, then distribution-free robust learning is impossible for a wide variety of concept classes; on the other hand, the setting $\lambda=\rho$ allows us to develop robust ERM algorithms. We then bound the query complexity of these algorithms based on online learning guarantees and further improve these bounds for the special case of conjunctions. We finish by giving robust learning algorithms for halfspaces with margins on both $\{0,1\}^n$ and $\mathbb{R}^n$.
Robustness of Unsupervised Representation Learning without Labels
Oct 08, 2022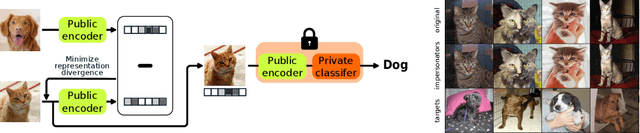

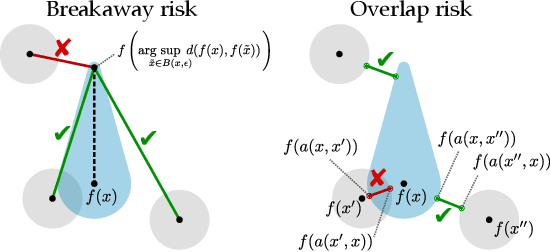
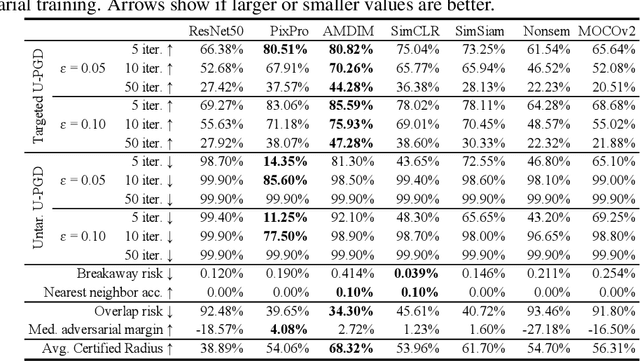
Unsupervised representation learning leverages large unlabeled datasets and is competitive with supervised learning. But non-robust encoders may affect downstream task robustness. Recently, robust representation encoders have become of interest. Still, all prior work evaluates robustness using a downstream classification task. Instead, we propose a family of unsupervised robustness measures, which are model- and task-agnostic and label-free. We benchmark state-of-the-art representation encoders and show that none dominates the rest. We offer unsupervised extensions to the FGSM and PGD attacks. When used in adversarial training, they improve most unsupervised robustness measures, including certified robustness. We validate our results against a linear probe and show that, for MOCOv2, adversarial training results in 3 times higher certified accuracy, a 2-fold decrease in impersonation attack success rate and considerable improvements in certified robustness.
Learning Dynamics and Generalization in Reinforcement Learning
Jun 05, 2022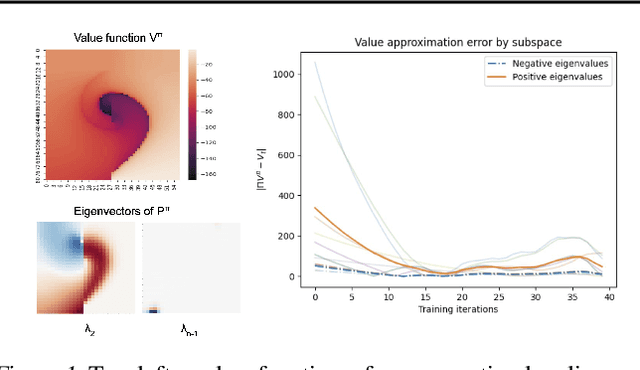
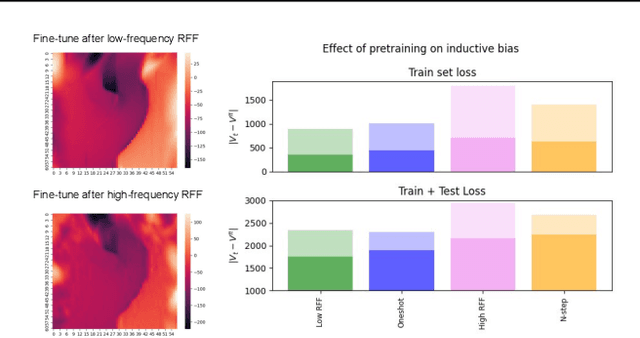
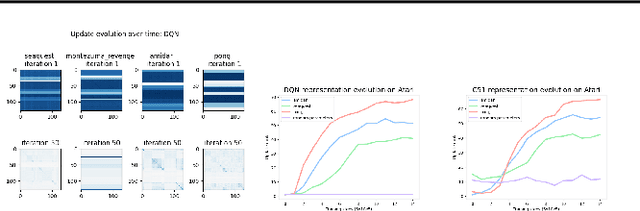
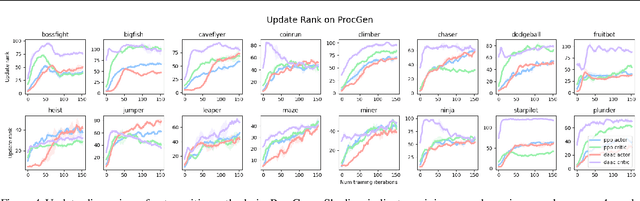
Solving a reinforcement learning (RL) problem poses two competing challenges: fitting a potentially discontinuous value function, and generalizing well to new observations. In this paper, we analyze the learning dynamics of temporal difference algorithms to gain novel insight into the tension between these two objectives. We show theoretically that temporal difference learning encourages agents to fit non-smooth components of the value function early in training, and at the same time induces the second-order effect of discouraging generalization. We corroborate these findings in deep RL agents trained on a range of environments, finding that neural networks trained using temporal difference algorithms on dense reward tasks exhibit weaker generalization between states than randomly initialized networks and networks trained with policy gradient methods. Finally, we investigate how post-training policy distillation may avoid this pitfall, and show that this approach improves generalization to novel environments in the ProcGen suite and improves robustness to input perturbations.
Sample Complexity Bounds for Robustly Learning Decision Lists against Evasion Attacks
May 12, 2022A fundamental problem in adversarial machine learning is to quantify how much training data is needed in the presence of evasion attacks. In this paper we address this issue within the framework of PAC learning, focusing on the class of decision lists. Given that distributional assumptions are essential in the adversarial setting, we work with probability distributions on the input data that satisfy a Lipschitz condition: nearby points have similar probability. Our key results illustrate that the adversary's budget (that is, the number of bits it can perturb on each input) is a fundamental quantity in determining the sample complexity of robust learning. Our first main result is a sample-complexity lower bound: the class of monotone conjunctions (essentially the simplest non-trivial hypothesis class on the Boolean hypercube) and any superclass has sample complexity at least exponential in the adversary's budget. Our second main result is a corresponding upper bound: for every fixed $k$ the class of $k$-decision lists has polynomial sample complexity against a $\log(n)$-bounded adversary. This sheds further light on the question of whether an efficient PAC learning algorithm can always be used as an efficient $\log(n)$-robust learning algorithm under the uniform distribution.
Robustness Guarantees for Credal Bayesian Networks via Constraint Relaxation over Probabilistic Circuits
May 11, 2022
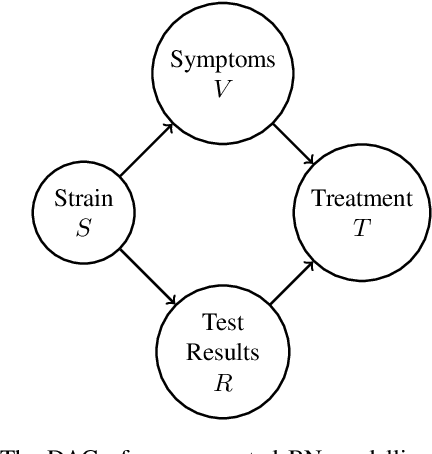
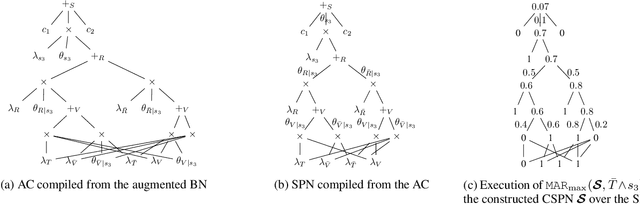
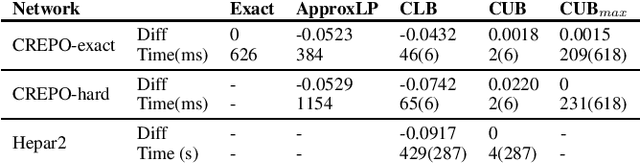
In many domains, worst-case guarantees on the performance (e.g., prediction accuracy) of a decision function subject to distributional shifts and uncertainty about the environment are crucial. In this work we develop a method to quantify the robustness of decision functions with respect to credal Bayesian networks, formal parametric models of the environment where uncertainty is expressed through credal sets on the parameters. In particular, we address the maximum marginal probability (MARmax) problem, that is, determining the greatest probability of an event (such as misclassification) obtainable for parameters in the credal set. We develop a method to faithfully transfer the problem into a constrained optimization problem on a probabilistic circuit. By performing a simple constraint relaxation, we show how to obtain a guaranteed upper bound on MARmax in linear time in the size of the circuit. We further theoretically characterize this constraint relaxation in terms of the original Bayesian network structure, which yields insight into the tightness of the bound. We implement the method and provide experimental evidence that the upper bound is often near tight and demonstrates improved scalability compared to other methods.
Individual Fairness Guarantees for Neural Networks
May 11, 2022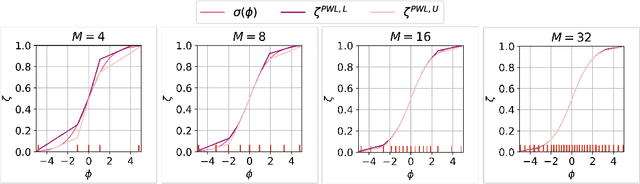
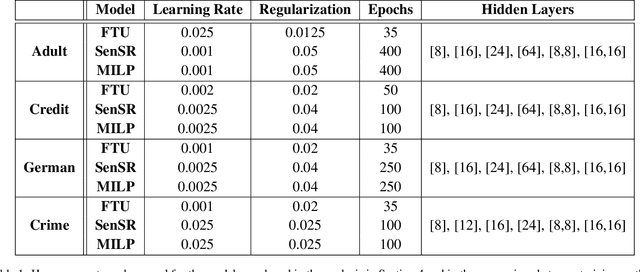
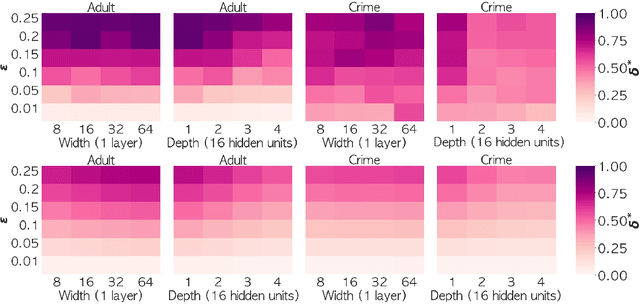
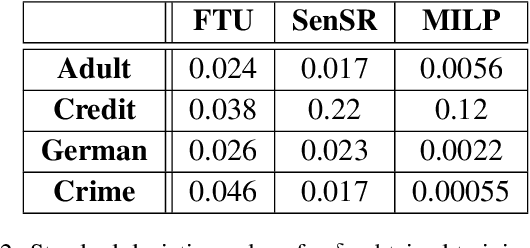
We consider the problem of certifying the individual fairness (IF) of feed-forward neural networks (NNs). In particular, we work with the $\epsilon$-$\delta$-IF formulation, which, given a NN and a similarity metric learnt from data, requires that the output difference between any pair of $\epsilon$-similar individuals is bounded by a maximum decision tolerance $\delta \geq 0$. Working with a range of metrics, including the Mahalanobis distance, we propose a method to overapproximate the resulting optimisation problem using piecewise-linear functions to lower and upper bound the NN's non-linearities globally over the input space. We encode this computation as the solution of a Mixed-Integer Linear Programming problem and demonstrate that it can be used to compute IF guarantees on four datasets widely used for fairness benchmarking. We show how this formulation can be used to encourage models' fairness at training time by modifying the NN loss, and empirically confirm our approach yields NNs that are orders of magnitude fairer than state-of-the-art methods.
Tractable Uncertainty for Structure Learning
Apr 29, 2022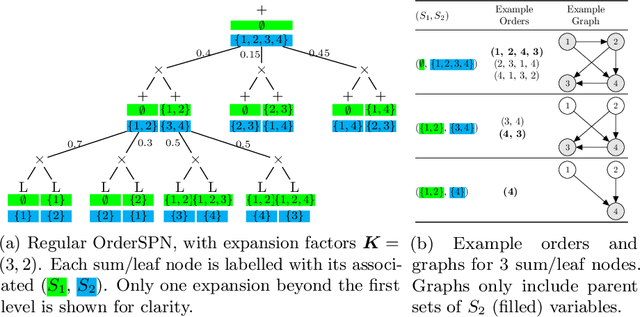

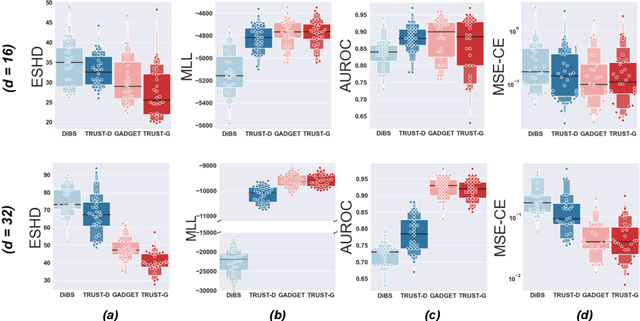
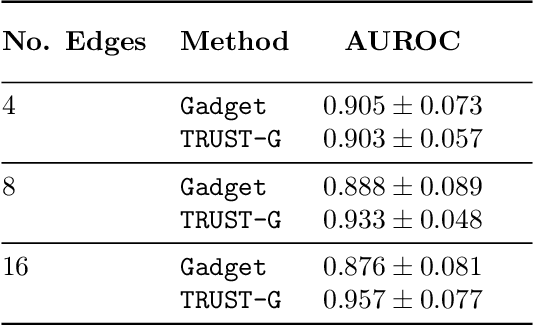
Bayesian structure learning allows one to capture uncertainty over the causal directed acyclic graph (DAG) responsible for generating given data. In this work, we present Tractable Uncertainty for STructure learning (TRUST), a framework for approximate posterior inference that relies on probabilistic circuits as the representation of our posterior belief. In contrast to sample-based posterior approximations, our representation can capture a much richer space of DAGs, while being able to tractably answer a range of useful inference queries. We empirically show how probabilistic circuits can be used as an augmented representation for structure learning methods, leading to improvement in both the quality of inferred structures and posterior uncertainty. Experimental results also demonstrate the improved representational capacity of TRUST, outperforming competing methods on conditional query answering.
Strategy Synthesis for Zero-sum Neuro-symbolic Concurrent Stochastic Games
Feb 13, 2022
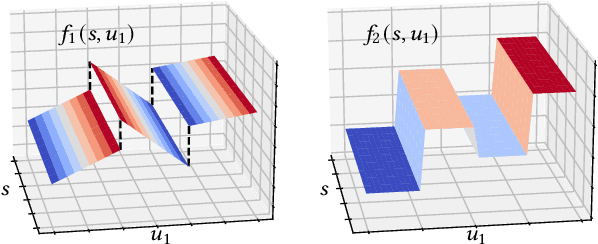
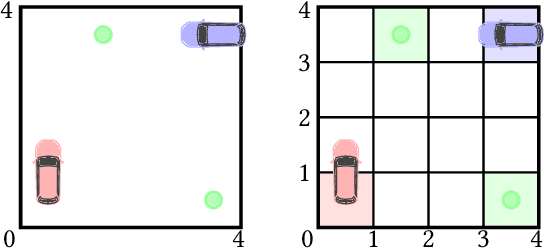
Neuro-symbolic approaches to artificial intelligence, which combine neural networks with classical symbolic techniques, are growing in prominence, necessitating formal approaches to reason about their correctness. We propose a novel modelling formalism called neuro-symbolic concurrent stochastic games (NS-CSGs), which comprise a set of probabilistic finite-state agents interacting in a shared continuous-state environment, observed through perception mechanisms implemented as neural networks. Since the environment state space is continuous, we focus on the class of NS-CSGs with Borel state spaces and Borel measurability restrictions on the components of the model. We consider the problem of zero-sum discounted cumulative reward, proving that NS-CSGs are determined and therefore have a value which corresponds to a unique fixed point. From an algorithmic perspective, existing methods to compute values and optimal strategies for CSGs focus on finite state spaces. We present, for the first time, value iteration and policy iteration algorithms to solve a class of uncountable state space CSGs, and prove their convergence. Our approach works by formulating piecewise linear or constant representations of the value functions and strategies of NS-CSGs. We validate the approach with a prototype implementation applied to a dynamic vehicle parking example.