 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTipping the Balance: Impact of Class Imbalance Correction on the Performance of Clinical Risk Prediction Models
Feb 27, 2026Objective: ML-based clinical risk prediction models are increasingly used to support decision-making in healthcare. While class-imbalance correction techniques are commonly applied to improve model performance in settings with rare outcomes, their impact on probabilistic calibration remains insufficiently understood. This study evaluated the effect of widely used resampling strategies on both discrimination and calibration across real-world clinical prediction tasks. Methods: Ten clinical datasets spanning diverse medical domains and including 605,842 patients were analyzed. Multiple machine-learning model families, including linear models and several non-linear approaches, were evaluated. Models were trained on the original data and under three commonly used 1:1 class-imbalance correction strategies (SMOTE, RUS, ROS). Performance was assessed on held-out data using discrimination and calibration metrics. Results: Across all datasets and model families, resampling had no positive impact on predictive performance. Changes in the Receiver Operating Characteristic Area Under Curve (ROC-AUC) relative to models trained on the original data were small and inconsistent (ROS: -0.002, p<0.05; RUS: -0.004, p>0.05; SMOTE: -0.01, p<0.05), with no resampling strategy demonstrating a systematic improvement. In contrast, resampling in general degraded the calibration performance. Models trained using imbalance correction exhibited higher Brier scores (0.029 to 0.080, p<0.05), reflecting poorer probabilistic accuracy, and marked deviations in calibration intercept and slope, indicating systematic distortions of predicted risk despite preserved rank-based performance. Conclusion: In a diverse set of real-world clinical prediction tasks, commonly used class-imbalance correction techniques did not provide generalizable improvements in discrimination and were associated with degraded calibration.
Classifying extremely imbalanced data sets
Nov 29, 2010
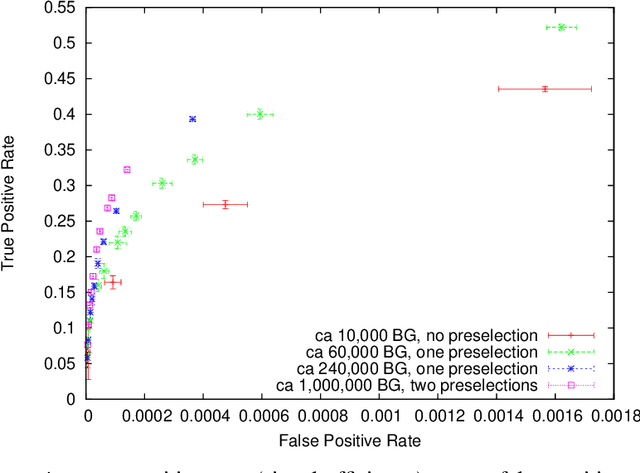


Imbalanced data sets containing much more background than signal instances are very common in particle physics, and will also be characteristic for the upcoming analyses of LHC data. Following up the work presented at ACAT 2008, we use the multivariate technique presented there (a rule growing algorithm with the meta-methods bagging and instance weighting) on much more imbalanced data sets, especially a selection of D0 decays without the use of particle identification. It turns out that the quality of the result strongly depends on the number of background instances used for training. We discuss methods to exploit this in order to improve the results significantly, and how to handle and reduce the size of large training sets without loss of result quality in general. We will also comment on how to take into account statistical fluctuation in receiver operation characteristic curves (ROC) for comparing classifier methods.