 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning approach to inverse problem and unfolding procedure
May 25, 2011

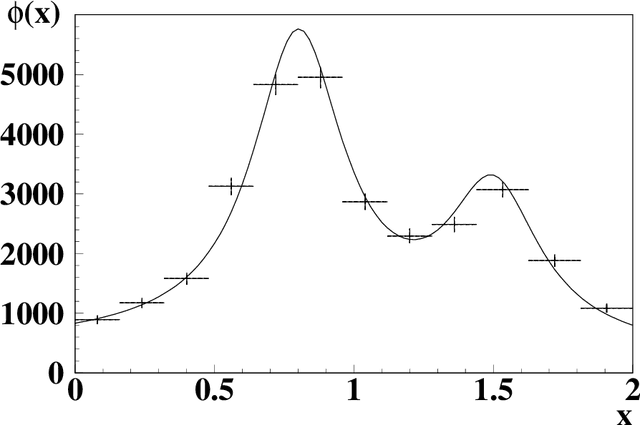

A procedure for unfolding the true distribution from experimental data is presented. Machine learning methods are applied for simultaneous identification of an apparatus function and solving of an inverse problem. A priori information about the true distribution from theory or previous experiments is used for Monte-Carlo simulation of the training sample. The training sample can be used to calculate a transformation from the true distribution to the measured one. This transformation provides a robust solution for an unfolding problem with minimal biases and statistical errors for the set of distributions used to create the training sample. The dimensionality of the solved problem can be arbitrary. A numerical example is presented to illustrate and validate the procedure.
Classifying extremely imbalanced data sets
Nov 29, 2010
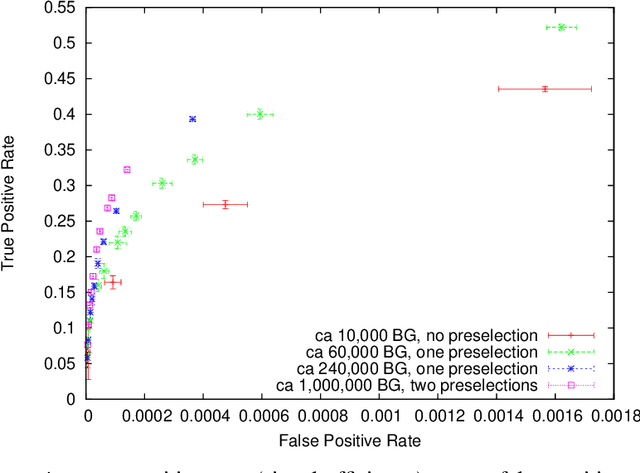


Imbalanced data sets containing much more background than signal instances are very common in particle physics, and will also be characteristic for the upcoming analyses of LHC data. Following up the work presented at ACAT 2008, we use the multivariate technique presented there (a rule growing algorithm with the meta-methods bagging and instance weighting) on much more imbalanced data sets, especially a selection of D0 decays without the use of particle identification. It turns out that the quality of the result strongly depends on the number of background instances used for training. We discuss methods to exploit this in order to improve the results significantly, and how to handle and reduce the size of large training sets without loss of result quality in general. We will also comment on how to take into account statistical fluctuation in receiver operation characteristic curves (ROC) for comparing classifier methods.