 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Improved Generic Bet-and-Run Strategy for Speeding Up Stochastic Local Search
Jun 23, 2018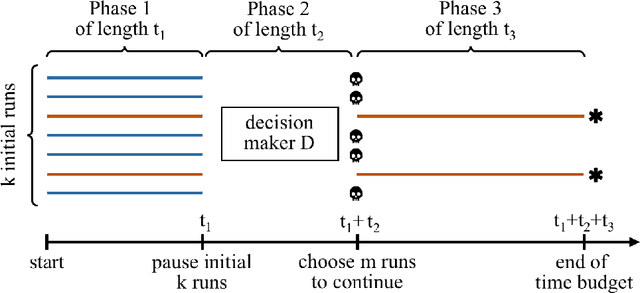
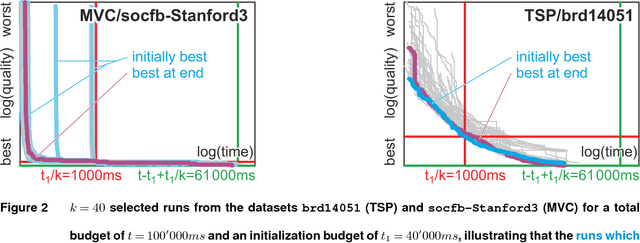
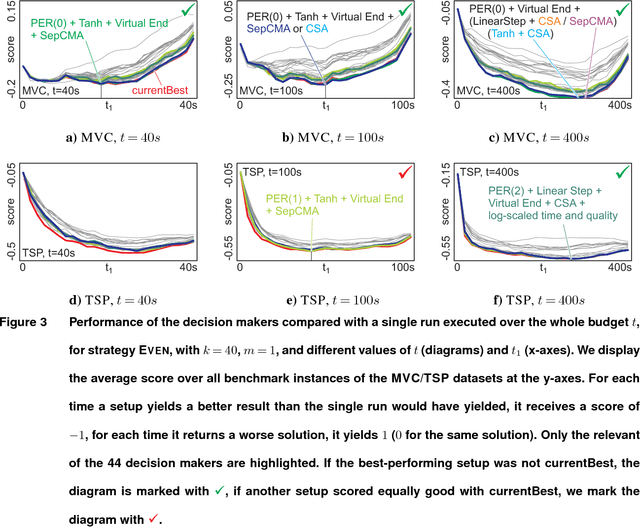
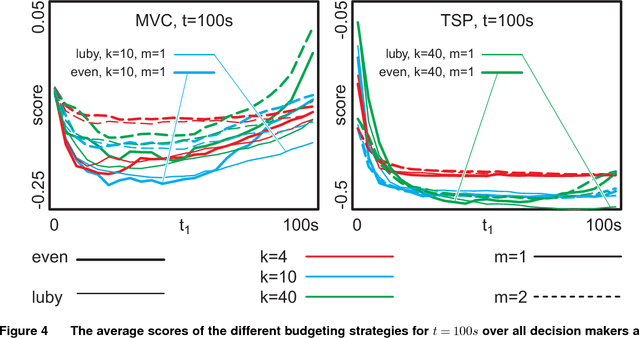
A commonly used strategy for improving optimization algorithms is to restart the algorithm when it is believed to be trapped in an inferior part of the search space. Building on the recent success of Bet-and-Run approaches for restarted local search solvers, we introduce an improved generic Bet-and-Run strategy. The goal is to obtain the best possible results within a given time budget t using a given black-box optimization algorithm. If no prior knowledge about problem features and algorithm behavior is available, the question about how to use the time budget most efficiently arises. We propose to first start k>=1 independent runs of the algorithm during an initialization budget t1<t, pausing these runs, then apply a decision maker D to choose 1<=m<=k runs from them (consuming t2>=0 time units in doing so), and then continuing these runs for the remaining t3=t-t1-t2 time units. In previous Bet-and-Run strategies, the decision maker D=currentBest would simply select the run with the best- so-far results at negligible time. We propose using more advanced methods to discriminate between "good" and "bad" sample runs, with the goal of increasing the correlation of the chosen run with the a-posteriori best one. We test several different approaches, including neural networks trained or polynomials fitted on the current trace of the algorithm to predict which run may yield the best results if granted the remaining budget. We show with extensive experiments that this approach can yield better results than the previous methods, but also find that the currentBest method is a very reliable and robust baseline approach.
Per-Corpus Configuration of Topic Modelling for GitHub and Stack Overflow Collections
Jun 23, 2018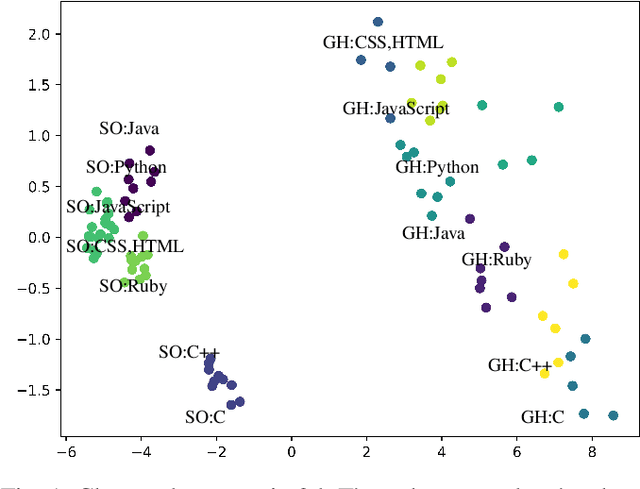
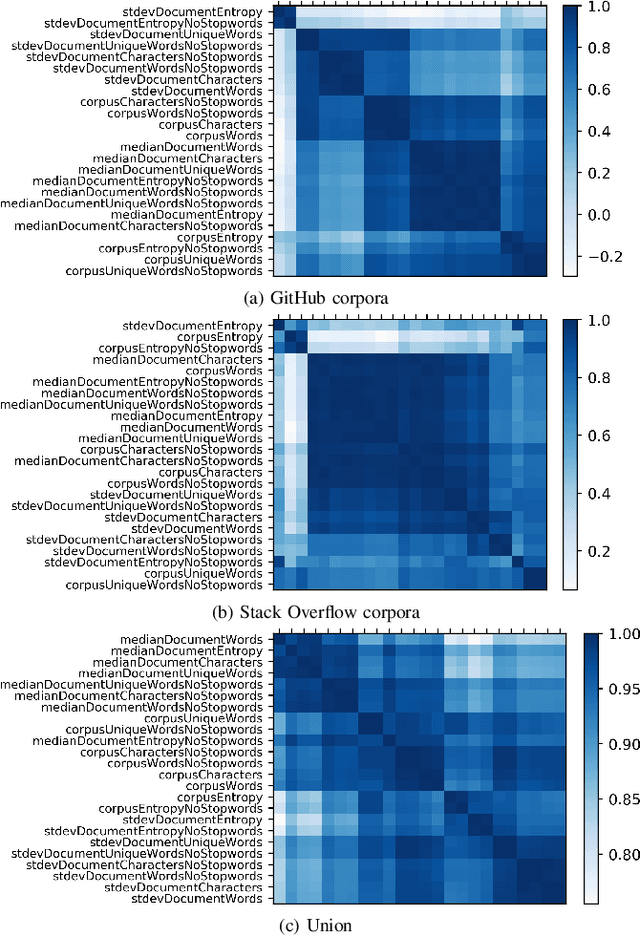
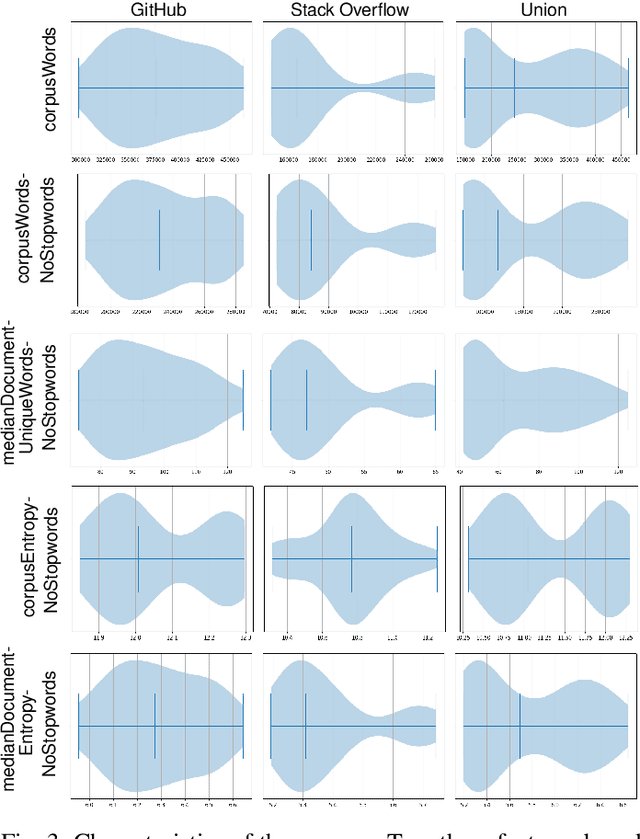
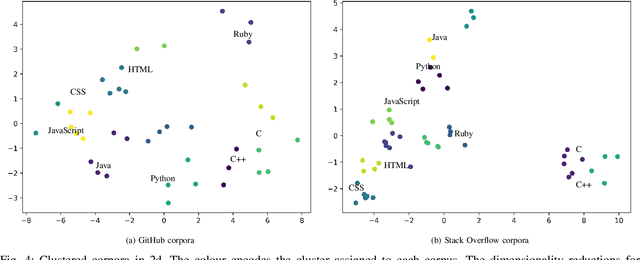
To make sense of large amounts of textual data, topic modelling is frequently used as a text-mining tool for the discovery of hidden semantic structures in text bodies. Latent Dirichlet allocation (LDA) is a commonly used topic model that aims to explain the structure of a corpus by grouping texts. LDA requires multiple parameters to work well, and there are only rough and sometimes conflicting guidelines available on how these parameters should be set. In this paper, we contribute (i) a broad study of parameters to arrive at good local optima, (ii) an a-posteriori characterisation of text corpora related to eight programming languages from GitHub and Stack Overflow, and (iii) an analysis of corpus feature importance via per-corpus LDA configuration.
On the Effectiveness of Simple Success-Based Parameter Selection Mechanisms for Two Classical Discrete Black-Box Optimization Benchmark Problems
Mar 04, 2018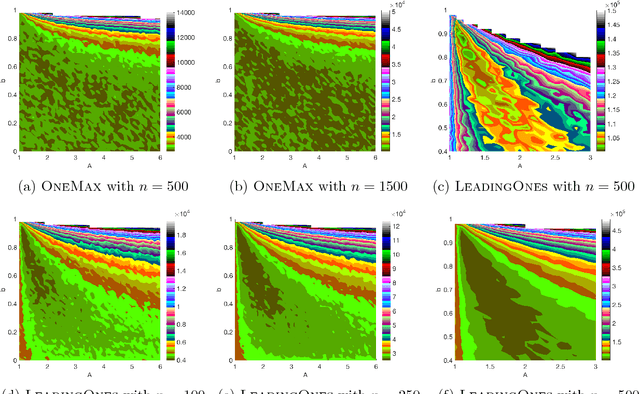
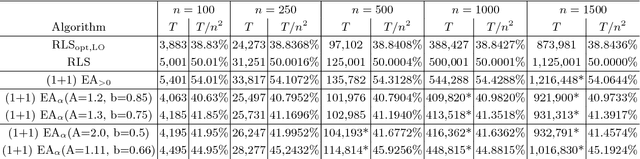
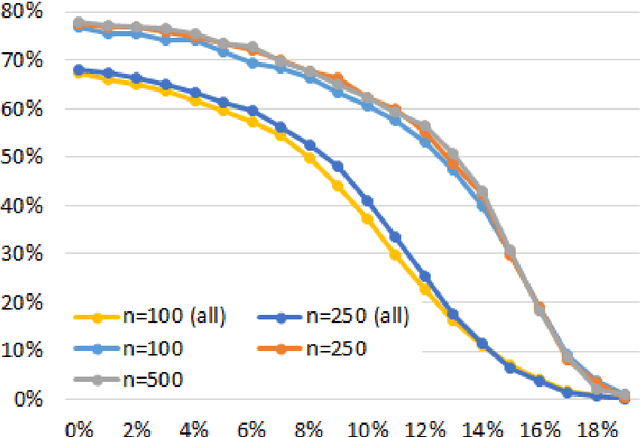
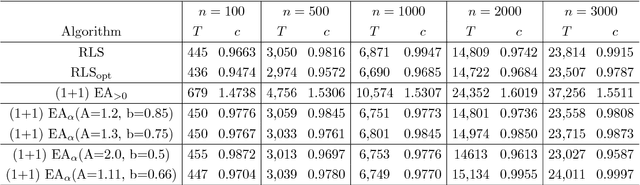
Despite significant empirical and theoretically supported evidence that non-static parameter choices can be strongly beneficial in evolutionary computation, the question how to best adjust parameter values plays only a marginal role in contemporary research on discrete black-box optimization. This has led to the unsatisfactory situation in which feedback-free parameter selection rules such as the cooling schedule of Simulated Annealing are predominant in state-of-the-art heuristics, while, at the same time, we understand very well that such time-dependent selection rules can only perform worse than adjustment rules that do take into account the evolution of the optimization process. A number of adaptive and self-adaptive parameter control strategies have been proposed in the literature, but did not (yet) make their way to a broader public. A key obstacle seems to lie in their rather complex update rules. The purpose of our work is to demonstrate that high-performing online parameter selection rules do not have to be very complicated. More precisely, we experiment with a multiplicative, comparison-based update rule to adjust the mutation probability of a (1+1)~Evolutionary Algorithm. We show that this simple self-adjusting rule outperforms the best static unary unbiased black-box algorithm on LeadingOnes, achieving an almost optimal speedup of about~$18\%$.
Discrepancy-based Evolutionary Diversity Optimization
Feb 15, 2018
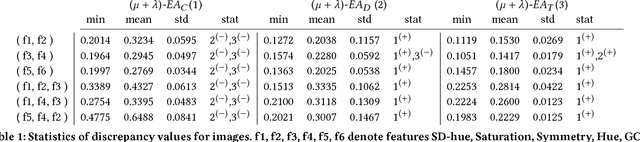

Diversity plays a crucial role in evolutionary computation. While diversity has been mainly used to prevent the population of an evolutionary algorithm from premature convergence, the use of evolutionary algorithms to obtain a diverse set of solutions has gained increasing attention in recent years. Diversity optimization in terms of features on the underlying problem allows to obtain a better understanding of possible solutions to the problem at hand and can be used for algorithm selection when dealing with combinatorial optimization problems such as the Traveling Salesperson Problem. We explore the use of the star-discrepancy measure to guide the diversity optimization process of an evolutionary algorithm. In our experimental investigations, we consider our discrepancy-based diversity optimization approaches for evolving diverse sets of images as well as instances of the Traveling Salesperson problem where a local search is not able to find near optimal solutions. Our experimental investigations comparing three diversity optimization approaches show that a discrepancy-based diversity optimization approach using a tie-breaking rule based on weighted differences to surrounding feature points provides the best results in terms of the star discrepancy measure.
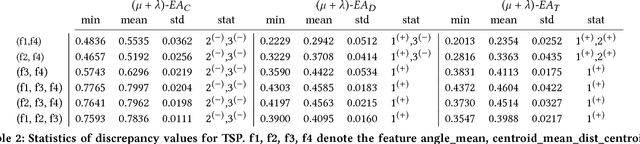
Evolutionary Computation plus Dynamic Programming for the Bi-Objective Travelling Thief Problem
Feb 07, 2018
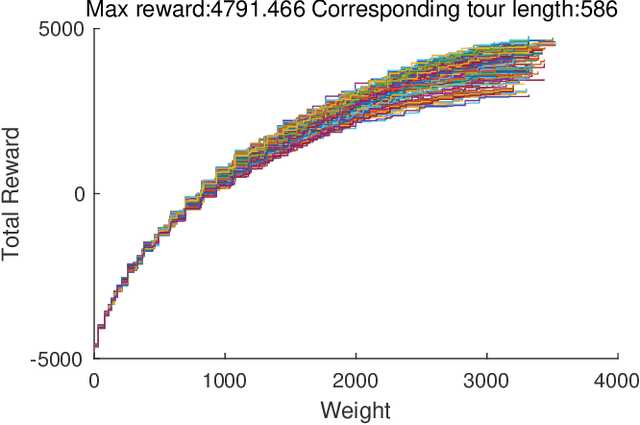
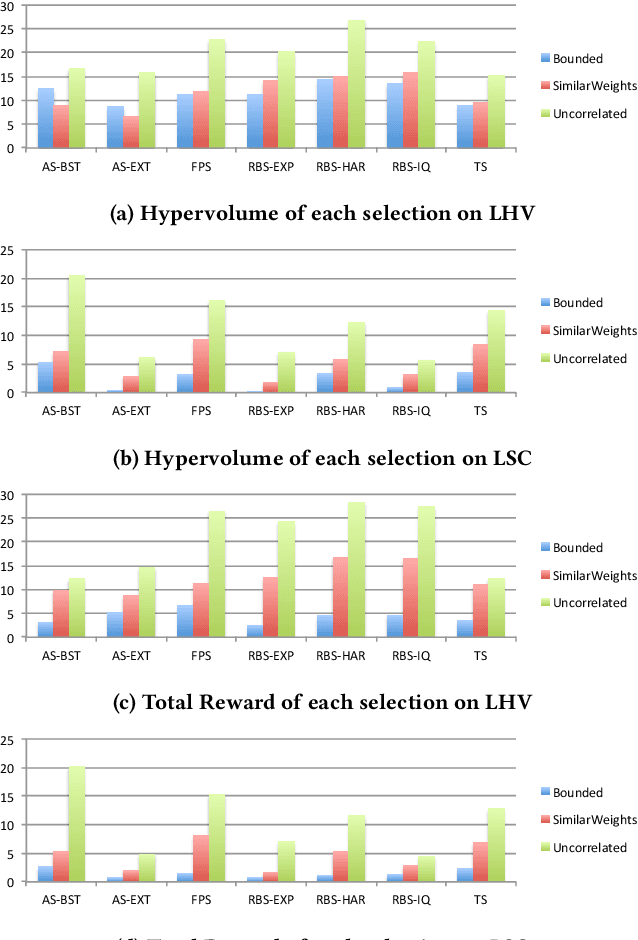
This research proposes a novel indicator-based hybrid evolutionary approach that combines approximate and exact algorithms. We apply it to a new bi-criteria formulation of the travelling thief problem, which is known to the Evolutionary Computation community as a benchmark multi-component optimisation problem that interconnects two classical NP-hard problems: the travelling salesman problem and the 0-1 knapsack problem. Our approach employs the exact dynamic programming algorithm for the underlying Packing-While-Travelling (PWT) problem as a subroutine within a bi-objective evolutionary algorithm. This design takes advantage of the data extracted from Pareto fronts generated by the dynamic program to achieve better solutions. Furthermore, we develop a number of novel indicators and selection mechanisms to strengthen synergy of the two algorithmic components of our approach. The results of computational experiments show that the approach is capable to outperform the state-of-the-art results for the single-objective case of the problem.
Exact Approaches for the Travelling Thief Problem
Aug 01, 2017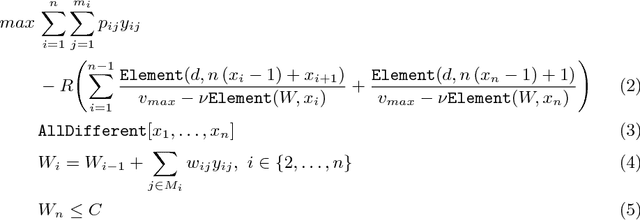
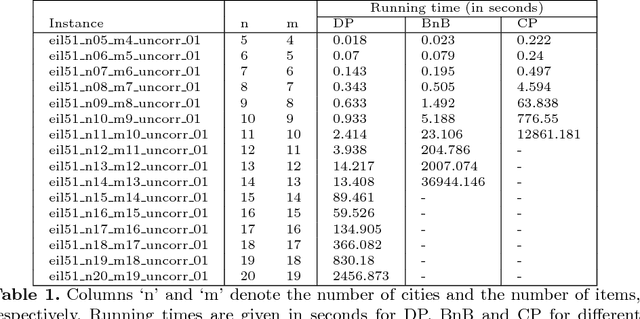
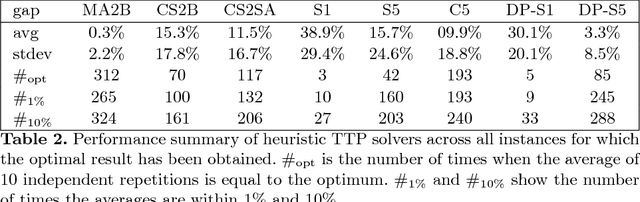
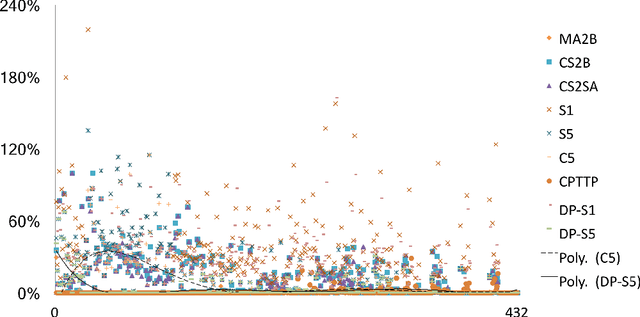
Many evolutionary and constructive heuristic approaches have been introduced in order to solve the Traveling Thief Problem (TTP). However, the accuracy of such approaches is unknown due to their inability to find global optima. In this paper, we propose three exact algorithms and a hybrid approach to the TTP. We compare these with state-of-the-art approaches to gather a comprehensive overview on the accuracy of heuristic methods for solving small TTP instances.
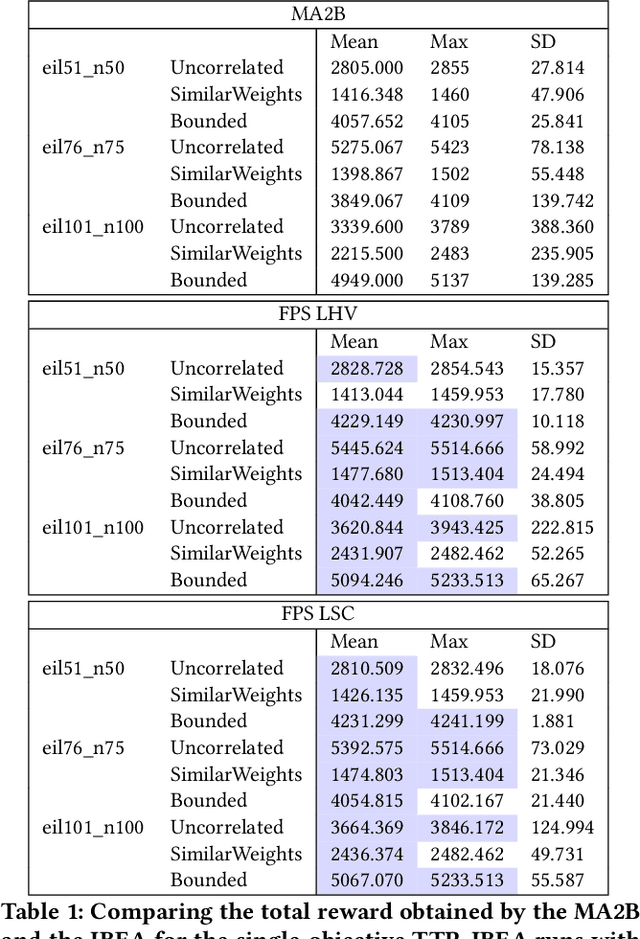
A Generic Bet-and-run Strategy for Speeding Up Traveling Salesperson and Minimum Vertex Cover
Sep 13, 2016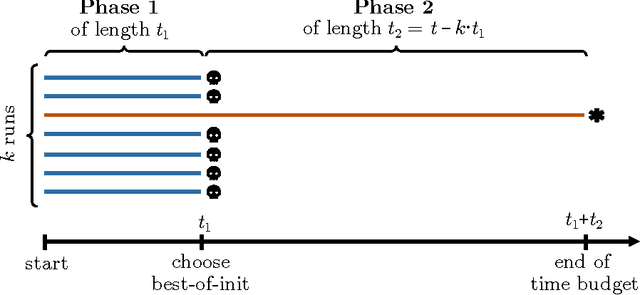
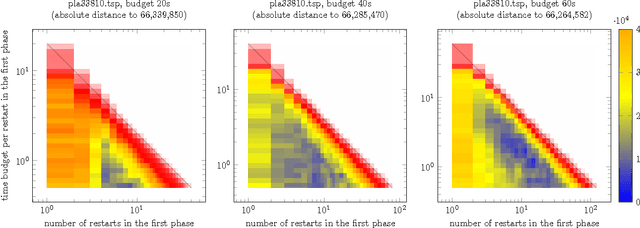
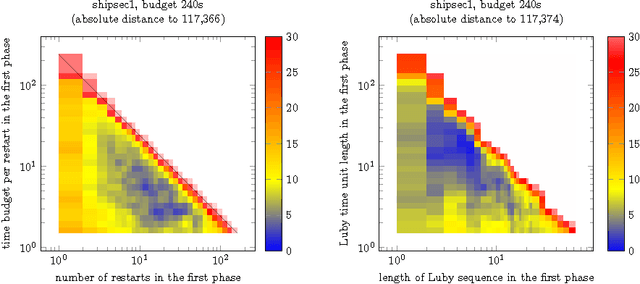
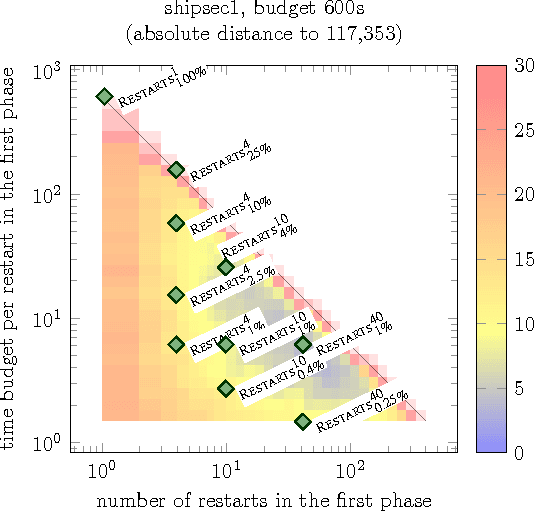
A common strategy for improving optimization algorithms is to restart the algorithm when it is believed to be trapped in an inferior part of the search space. However, while specific restart strategies have been developed for specific problems (and specific algorithms), restarts are typically not regarded as a general tool to speed up an optimization algorithm. In fact, many optimization algorithms do not employ restarts at all. Recently, "bet-and-run" was introduced in the context of mixed-integer programming, where first a number of short runs with randomized initial conditions is made, and then the most promising run of these is continued. In this article, we consider two classical NP-complete combinatorial optimization problems, traveling salesperson and minimum vertex cover, and study the effectiveness of different bet-and-run strategies. In particular, our restart strategies do not take any problem knowledge into account, nor are tailored to the optimization algorithm. Therefore, they can be used off-the-shelf. We observe that state-of-the-art solvers for these problems can benefit significantly from restarts on standard benchmark instances.
A case study of algorithm selection for the traveling thief problem
Sep 02, 2016
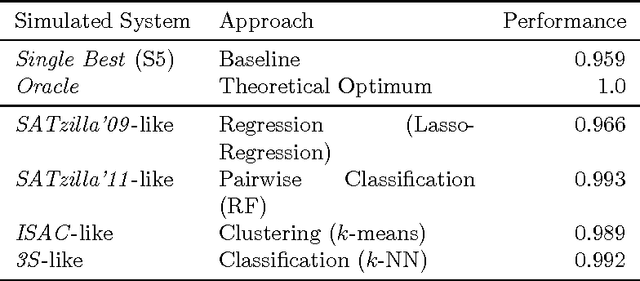
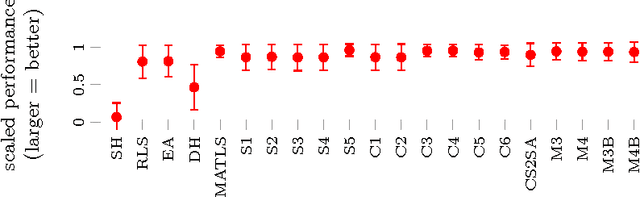
Many real-world problems are composed of several interacting components. In order to facilitate research on such interactions, the Traveling Thief Problem (TTP) was created in 2013 as the combination of two well-understood combinatorial optimization problems. With this article, we contribute in four ways. First, we create a comprehensive dataset that comprises the performance data of 21 TTP algorithms on the full original set of 9720 TTP instances. Second, we define 55 characteristics for all TPP instances that can be used to select the best algorithm on a per-instance basis. Third, we use these algorithms and features to construct the first algorithm portfolios for TTP, clearly outperforming the single best algorithm. Finally, we study which algorithms contribute most to this portfolio.
Evolutionary computation for multicomponent problems: opportunities and future directions
Jun 22, 2016
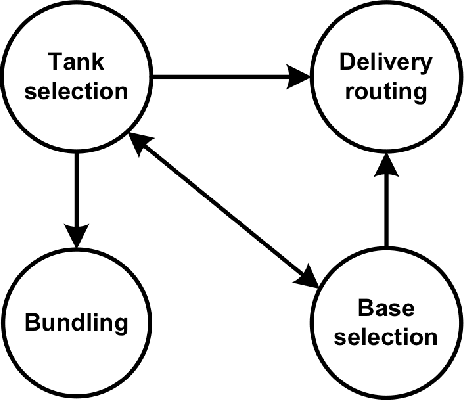
Over the past 30 years many researchers in the field of evolutionary computation have put a lot of effort to introduce various approaches for solving hard problems. Most of these problems have been inspired by major industries so that solving them, by providing either optimal or near optimal solution, was of major significance. Indeed, this was a very promising trajectory as advances in these problem-solving approaches could result in adding values to major industries. In this paper we revisit this trajectory to find out whether the attempts that started three decades ago are still aligned with the same goal, as complexities of real-world problems increased significantly. We present some examples of modern real-world problems, discuss why they might be difficult to solve, and whether there is any mismatch between these examples and the problems that are investigated in the evolutionary computation area.
Seeding the Initial Population of Multi-Objective Evolutionary Algorithms: A Computational Study
Nov 30, 2014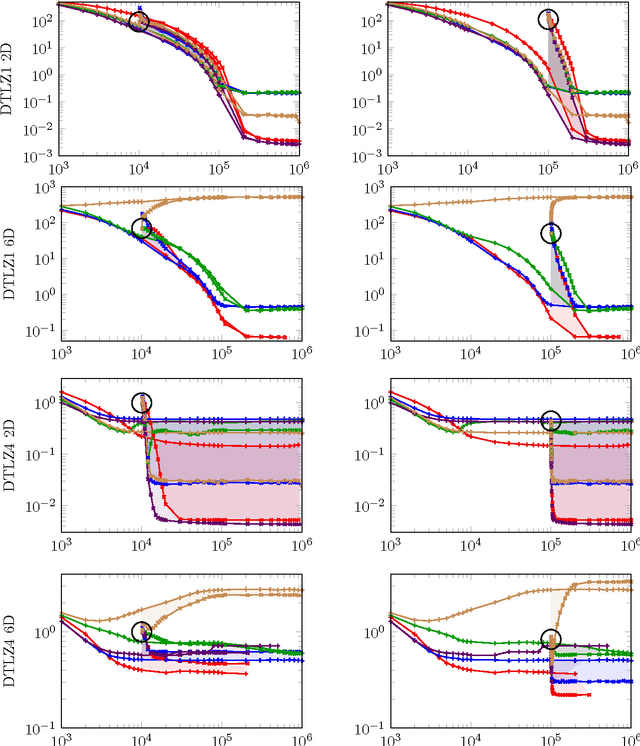



Most experimental studies initialize the population of evolutionary algorithms with random genotypes. In practice, however, optimizers are typically seeded with good candidate solutions either previously known or created according to some problem-specific method. This "seeding" has been studied extensively for single-objective problems. For multi-objective problems, however, very little literature is available on the approaches to seeding and their individual benefits and disadvantages. In this article, we are trying to narrow this gap via a comprehensive computational study on common real-valued test functions. We investigate the effect of two seeding techniques for five algorithms on 48 optimization problems with 2, 3, 4, 6, and 8 objectives. We observe that some functions (e.g., DTLZ4 and the LZ family) benefit significantly from seeding, while others (e.g., WFG) profit less. The advantage of seeding also depends on the examined algorithm.