 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Attention Forcing for Machine Translation
Nov 06, 2022Attention-based autoregressive models have achieved state-of-the-art performance in various sequence-to-sequence tasks, including Text-To-Speech (TTS) and Neural Machine Translation (NMT), but can be difficult to train. The standard training approach, teacher forcing, guides a model with the reference back-history. During inference, the generated back-history must be used. This mismatch limits the evaluation performance. Attention forcing has been introduced to address the mismatch, guiding the model with the generated back-history and reference attention. While successful in tasks with continuous outputs like TTS, attention forcing faces additional challenges in tasks with discrete outputs like NMT. This paper introduces the two extensions of attention forcing to tackle these challenges. (1) Scheduled attention forcing automatically turns attention forcing on and off, which is essential for tasks with discrete outputs. (2) Parallel attention forcing makes training parallel, and is applicable to Transformer-based models. The experiments show that the proposed approaches improve the performance of models based on RNNs and Transformers.
Deliberation Networks and How to Train Them
Nov 06, 2022Deliberation networks are a family of sequence-to-sequence models, which have achieved state-of-the-art performance in a wide range of tasks such as machine translation and speech synthesis. A deliberation network consists of multiple standard sequence-to-sequence models, each one conditioned on the initial input and the output of the previous model. During training, there are several key questions: whether to apply Monte Carlo approximation to the gradients or the loss, whether to train the standard models jointly or separately, whether to run an intermediate model in teacher forcing or free running mode, whether to apply task-specific techniques. Previous work on deliberation networks typically explores one or two training options for a specific task. This work introduces a unifying framework, covering various training options, and addresses the above questions. In general, it is simpler to approximate the gradients. When parallel training is essential, separate training should be adopted. Regardless of the task, the intermediate model should be in free running mode. For tasks where the output is continuous, a guided attention loss can be used to prevent degradation into a standard model.
Multiple-Choice Question Generation: Towards an Automated Assessment Framework
Sep 23, 2022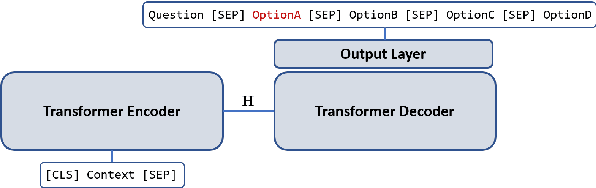
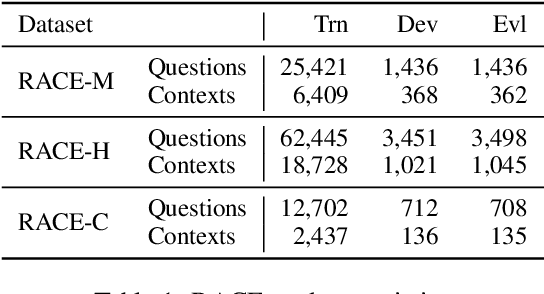
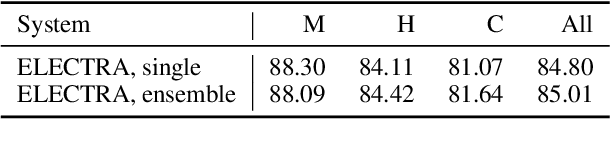
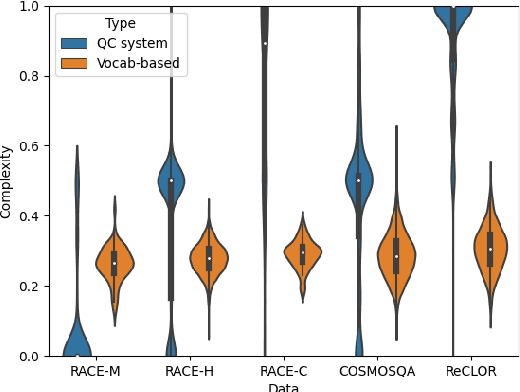
Automated question generation is an important approach to enable personalisation of English comprehension assessment. Recently, transformer-based pretrained language models have demonstrated the ability to produce appropriate questions from a context paragraph. Typically, these systems are evaluated against a reference set of manually generated questions using n-gram based metrics, or manual qualitative assessment. Here, we focus on a fully automated multiple-choice question generation (MCQG) system where both the question and possible answers must be generated from the context paragraph. Applying n-gram based approaches is challenging for this form of system as the reference set is unlikely to capture the full range of possible questions and answer options. Conversely manual assessment scales poorly and is expensive for MCQG system development. In this work, we propose a set of performance criteria that assess different aspects of the generated multiple-choice questions of interest. These qualities include: grammatical correctness, answerability, diversity and complexity. Initial systems for each of these metrics are described, and individually evaluated on standard multiple-choice reading comprehension corpora.
Gender Bias and Universal Substitution Adversarial Attacks on Grammatical Error Correction Systems for Automated Assessment
Aug 19, 2022
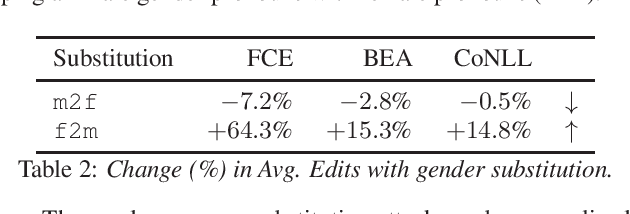

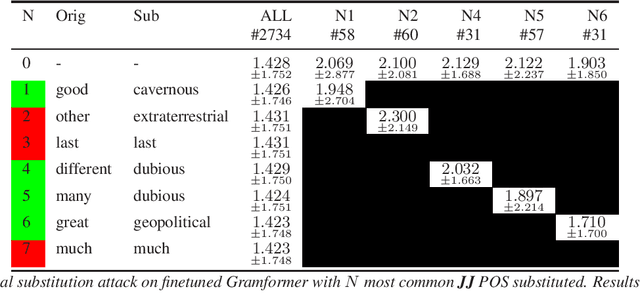
Grammatical Error Correction (GEC) systems perform a sequence-to-sequence task, where an input word sequence containing grammatical errors, is corrected for these errors by the GEC system to output a grammatically correct word sequence. With the advent of deep learning methods, automated GEC systems have become increasingly popular. For example, GEC systems are often used on speech transcriptions of English learners as a form of assessment and feedback - these powerful GEC systems can be used to automatically measure an aspect of a candidate's fluency. The count of \textit{edits} from a candidate's input sentence (or essay) to a GEC system's grammatically corrected output sentence is indicative of a candidate's language ability, where fewer edits suggest better fluency. The count of edits can thus be viewed as a \textit{fluency score} with zero implying perfect fluency. However, although deep learning based GEC systems are extremely powerful and accurate, they are susceptible to adversarial attacks: an adversary can introduce a small, specific change at the input of a system that causes a large, undesired change at the output. When considering the application of GEC systems to automated language assessment, the aim of an adversary could be to cheat by making a small change to a grammatically incorrect input sentence that conceals the errors from a GEC system, such that no edits are found and the candidate is unjustly awarded a perfect fluency score. This work examines a simple universal substitution adversarial attack that non-native speakers of English could realistically employ to deceive GEC systems used for assessment.
Residue-Based Natural Language Adversarial Attack Detection
Apr 17, 2022
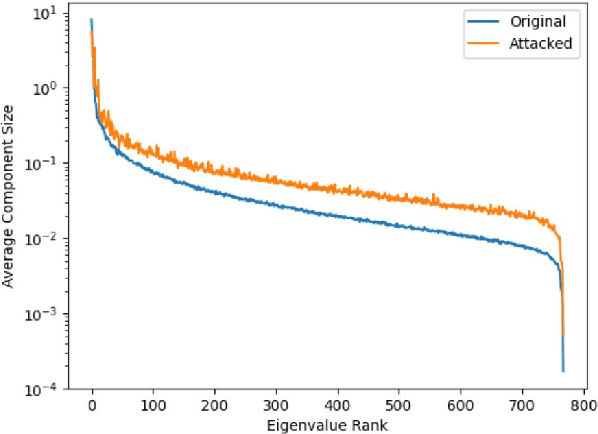
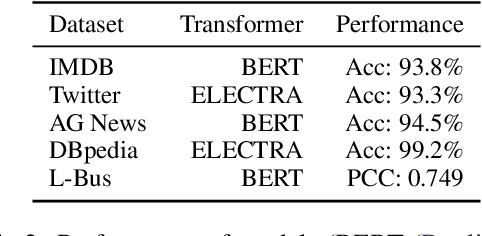
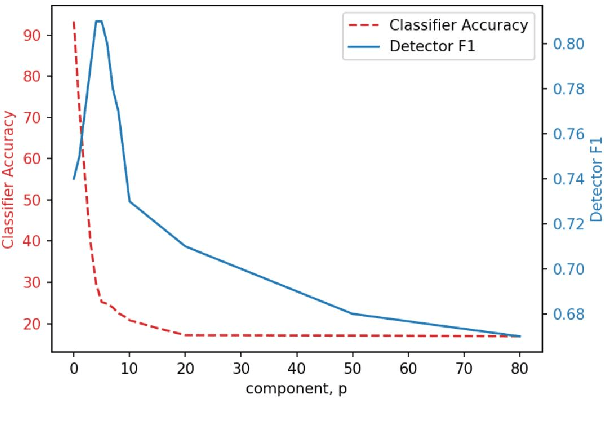
Deep learning based systems are susceptible to adversarial attacks, where a small, imperceptible change at the input alters the model prediction. However, to date the majority of the approaches to detect these attacks have been designed for image processing systems. Many popular image adversarial detection approaches are able to identify adversarial examples from embedding feature spaces, whilst in the NLP domain existing state of the art detection approaches solely focus on input text features, without consideration of model embedding spaces. This work examines what differences result when porting these image designed strategies to Natural Language Processing (NLP) tasks - these detectors are found to not port over well. This is expected as NLP systems have a very different form of input: discrete and sequential in nature, rather than the continuous and fixed size inputs for images. As an equivalent model-focused NLP detection approach, this work proposes a simple sentence-embedding "residue" based detector to identify adversarial examples. On many tasks, it out-performs ported image domain detectors and recent state of the art NLP specific detectors.
Scaling Ensemble Distribution Distillation to Many Classes with Proxy Targets
May 14, 2021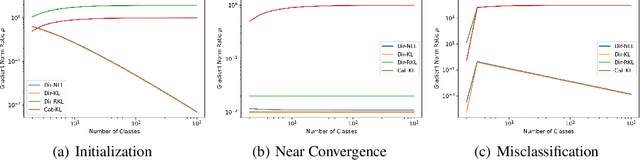

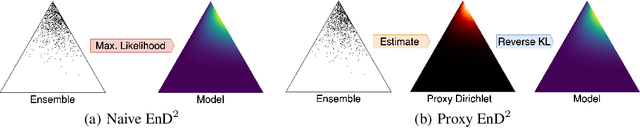
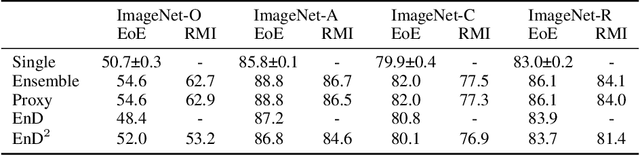
Ensembles of machine learning models yield improved system performance as well as robust and interpretable uncertainty estimates; however, their inference costs may often be prohibitively high. \emph{Ensemble Distribution Distillation} is an approach that allows a single model to efficiently capture both the predictive performance and uncertainty estimates of an ensemble. For classification, this is achieved by training a Dirichlet distribution over the ensemble members' output distributions via the maximum likelihood criterion. Although theoretically principled, this criterion exhibits poor convergence when applied to large-scale tasks where the number of classes is very high. In our work, we analyze this effect and show that the Dirichlet log-likelihood criterion classes with low probability induce larger gradients than high-probability classes. This forces the model to focus on the distribution of the ensemble tail-class probabilities. We propose a new training objective that minimizes the reverse KL-divergence to a \emph{Proxy-Dirichlet} target derived from the ensemble. This loss resolves the gradient issues of Ensemble Distribution Distillation, as we demonstrate both theoretically and empirically on the ImageNet and WMT17 En-De datasets containing 1000 and 40,000 classes, respectively.
Should Ensemble Members Be Calibrated?
Jan 13, 2021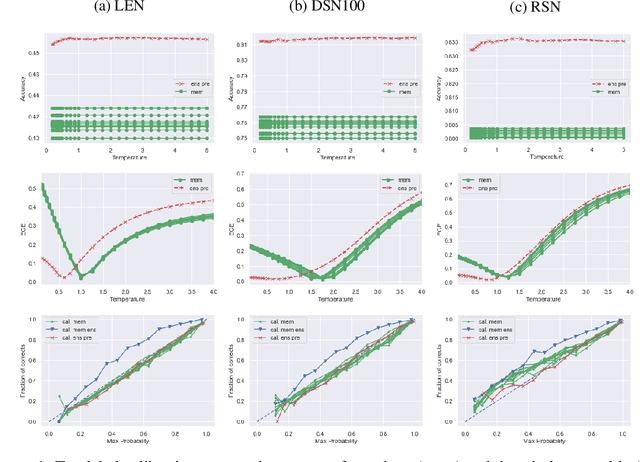
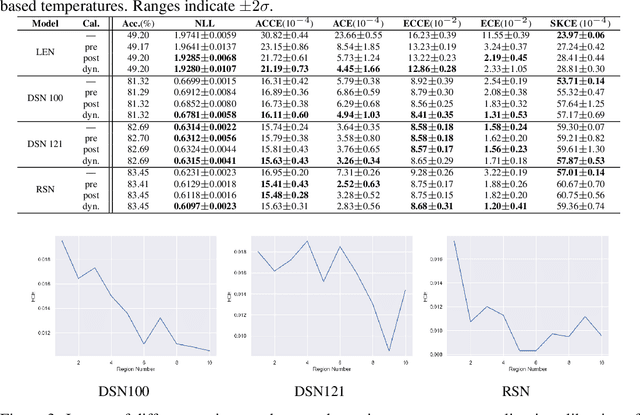
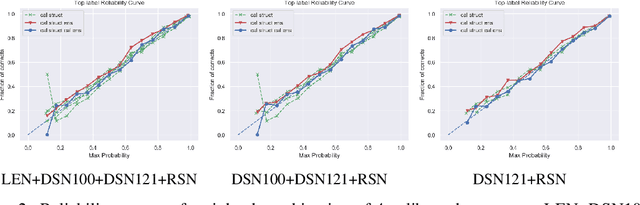
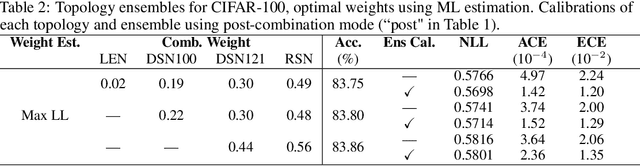
Underlying the use of statistical approaches for a wide range of applications is the assumption that the probabilities obtained from a statistical model are representative of the "true" probability that event, or outcome, will occur. Unfortunately, for modern deep neural networks this is not the case, they are often observed to be poorly calibrated. Additionally, these deep learning approaches make use of large numbers of model parameters, motivating the use of Bayesian, or ensemble approximation, approaches to handle issues with parameter estimation. This paper explores the application of calibration schemes to deep ensembles from both a theoretical perspective and empirically on a standard image classification task, CIFAR-100. The underlying theoretical requirements for calibration, and associated calibration criteria, are first described. It is shown that well calibrated ensemble members will not necessarily yield a well calibrated ensemble prediction, and if the ensemble prediction is well calibrated its performance cannot exceed that of the average performance of the calibrated ensemble members. On CIFAR-100 the impact of calibration for ensemble prediction, and associated calibration is evaluated. Additionally the situation where multiple different topologies are combined together is discussed.
CUED_speech at TREC 2020 Podcast Summarisation Track
Jan 13, 2021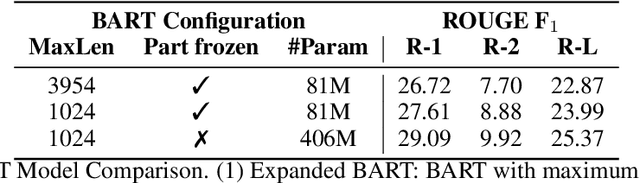
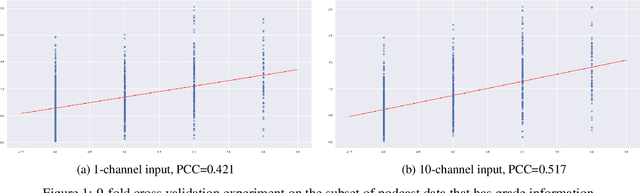
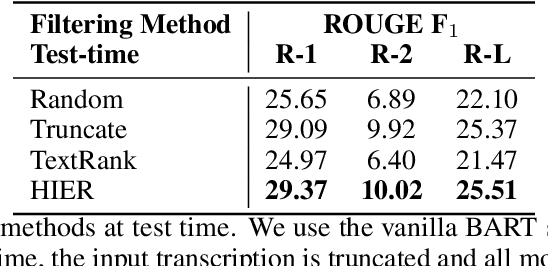
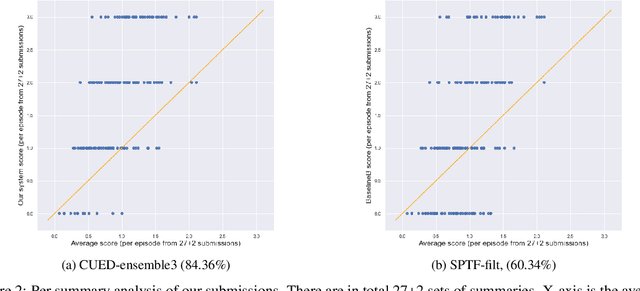
In this paper, we describe our approach for the Podcast Summarisation challenge in TREC 2020. Given a podcast episode with its transcription, the goal is to generate a summary that captures the most important information in the content. Our approach consists of two steps: (1) Filtering redundant or less informative sentences in the transcription using the attention of a hierarchical model; (2) Applying a state-of-the-art text summarisation system (BART) fine-tuned on the Podcast data using a sequence-level reward function. Furthermore, we perform ensembles of three and nine models for our submission runs. We also fine-tune the BART model on the Podcast data as our baseline. The human evaluation by NIST shows that our best submission achieves 1.777 in the EGFB scale, while the score of creator-provided description is 1.291. Our system won the Spotify Podcast Summarisation Challenge in the TREC2020 Podcast Track in both human and automatic evaluation.
Ensemble Distillation Approaches for Grammatical Error Correction
Dec 15, 2020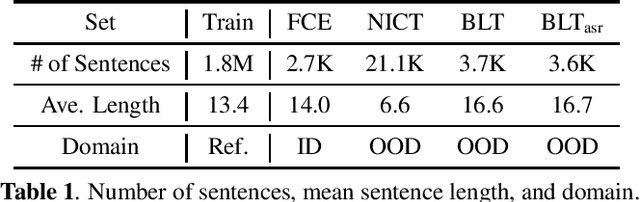
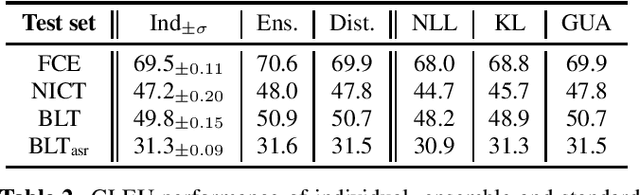
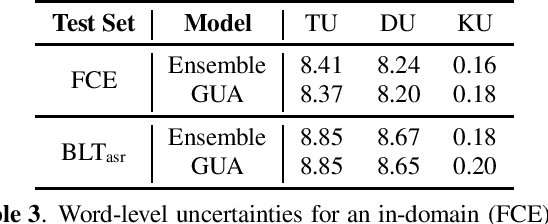
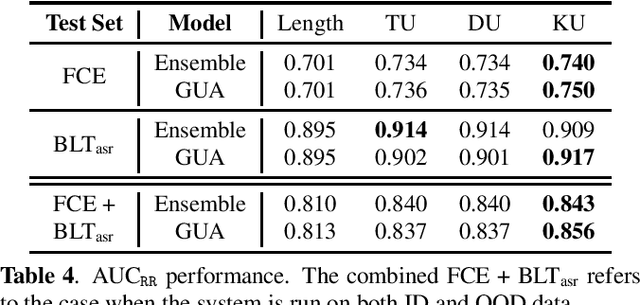
Ensemble approaches are commonly used techniques to improving a system by combining multiple model predictions. Additionally these schemes allow the uncertainty, as well as the source of the uncertainty, to be derived for the prediction. Unfortunately these benefits come at a computational and memory cost. To address this problem ensemble distillation (EnD) and more recently ensemble distribution distillation (EnDD) have been proposed that compress the ensemble into a single model, representing either the ensemble average prediction or prediction distribution respectively. This paper examines the application of both these distillation approaches to a sequence prediction task, grammatical error correction (GEC). This is an important application area for language learning tasks as it can yield highly useful feedback to the learner. It is, however, more challenging than the standard tasks investigated for distillation as the prediction of any grammatical correction to a word will be highly dependent on both the input sequence and the generated output history for the word. The performance of both EnD and EnDD are evaluated on both publicly available GEC tasks as well as a spoken language task.
Regression Prior Networks
Jun 20, 2020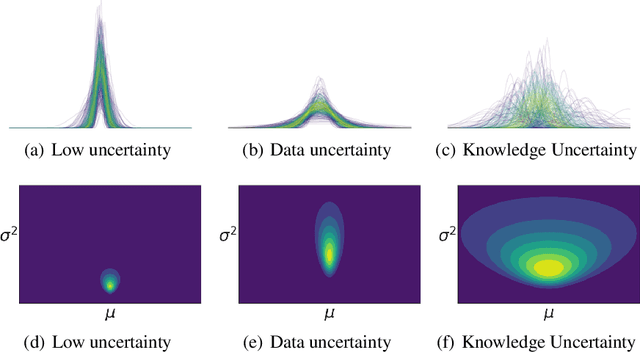

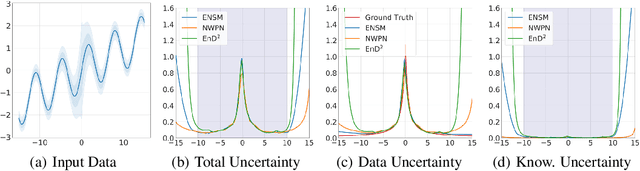
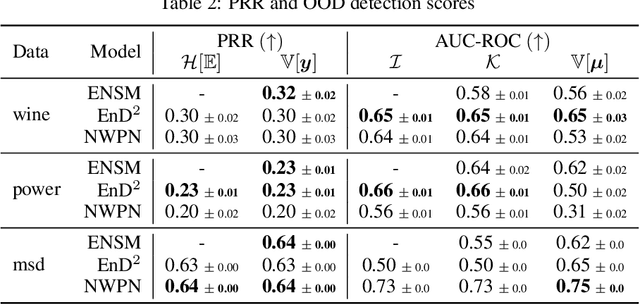
Prior Networks are a recently developed class of models which yield interpretable measures of uncertainty and have been shown to outperform state-of-the-art ensemble approaches on a range of tasks. They can also be used to distill an ensemble of models via Ensemble Distribution Distillation (EnD$^2$), such that its accuracy, calibration and uncertainty estimates are retained within a single model. However, Prior Networks have so far been developed only for classification tasks. This work extends Prior Networks and EnD$^2$ to regression tasks by considering the Normal-Wishart distribution. The properties of Regression Prior Networks are demonstrated on synthetic data, selected UCI datasets and a monocular depth estimation task, where they yield performance competitive with ensemble approaches.