 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperimental demonstration of a robust training method for strongly defective neuromorphic hardware
Dec 11, 2023The increasing scale of neural networks needed to support more complex applications has led to an increasing requirement for area- and energy-efficient hardware. One route to meeting the budget for these applications is to circumvent the von Neumann bottleneck by performing computation in or near memory. An inevitability of transferring neural networks onto hardware is that non-idealities such as device-to-device variations or poor device yield impact performance. Methods such as hardware-aware training, where substrate non-idealities are incorporated during network training, are one way to recover performance at the cost of solution generality. In this work, we demonstrate inference on hardware neural networks consisting of 20,000 magnetic tunnel junction arrays integrated on a complementary metal-oxide-semiconductor chips that closely resembles market-ready spin transfer-torque magnetoresistive random access memory technology. Using 36 dies, each containing a crossbar array with its own non-idealities, we show that even a small number of defects in physically mapped networks significantly degrades the performance of networks trained without defects and show that, at the cost of generality, hardware-aware training accounting for specific defects on each die can recover to comparable performance with ideal networks. We then demonstrate a robust training method that extends hardware-aware training to statistics-aware training, producing network weights that perform well on most defective dies regardless of their specific defect locations. When evaluated on the 36 physical dies, statistics-aware trained solutions can achieve a mean misclassification error on the MNIST dataset that differs from the software-baseline by only 2 %. This statistics-aware training method could be generalized to networks with many layers that are mapped to hardware suited for industry-ready applications.
Quantum materials for energy-efficient neuromorphic computing
Apr 04, 2022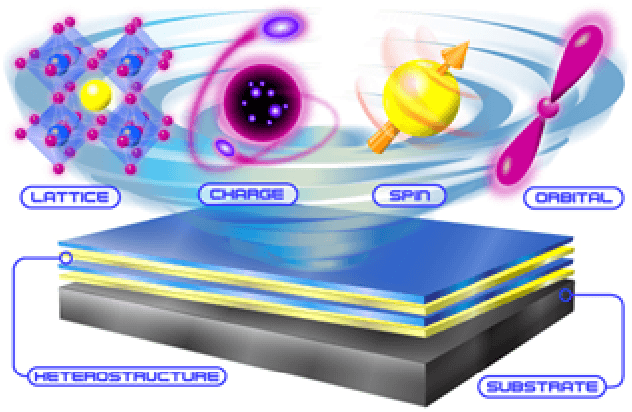
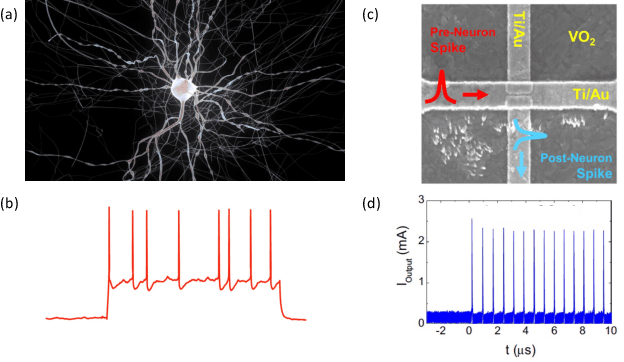
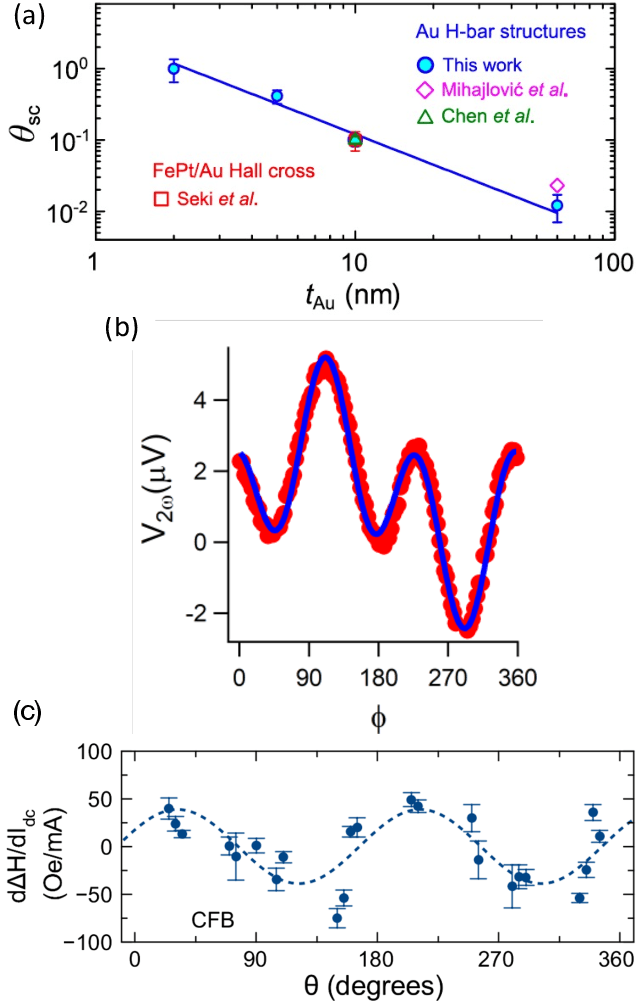
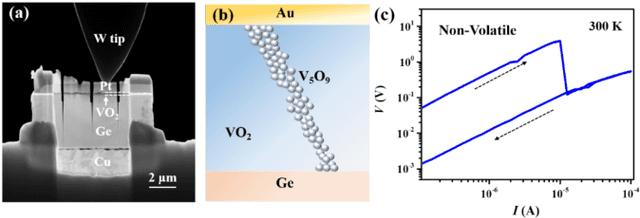
Neuromorphic computing approaches become increasingly important as we address future needs for efficiently processing massive amounts of data. The unique attributes of quantum materials can help address these needs by enabling new energy-efficient device concepts that implement neuromorphic ideas at the hardware level. In particular, strong correlations give rise to highly non-linear responses, such as conductive phase transitions that can be harnessed for short and long-term plasticity. Similarly, magnetization dynamics are strongly non-linear and can be utilized for data classification. This paper discusses select examples of these approaches, and provides a perspective for the current opportunities and challenges for assembling quantum-material-based devices for neuromorphic functionalities into larger emergent complex network systems.
Implementation of a Binary Neural Network on a Passive Array of Magnetic Tunnel Junctions
Dec 16, 2021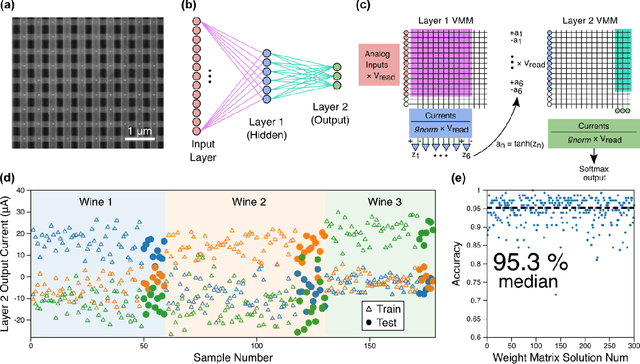
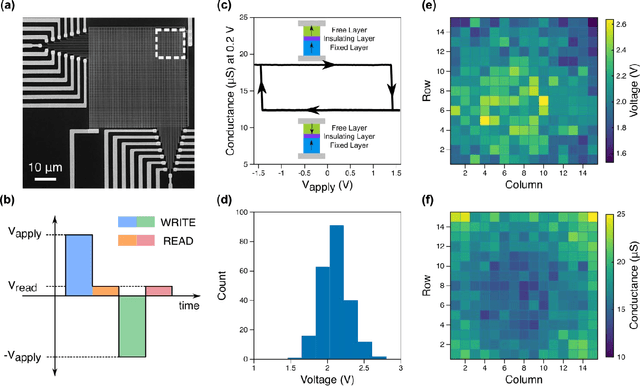
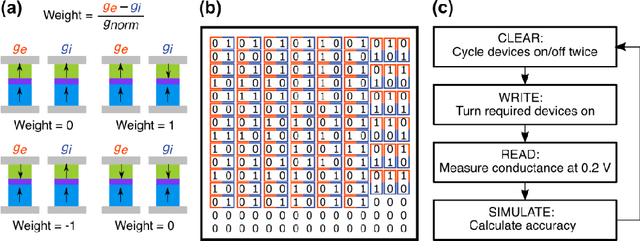
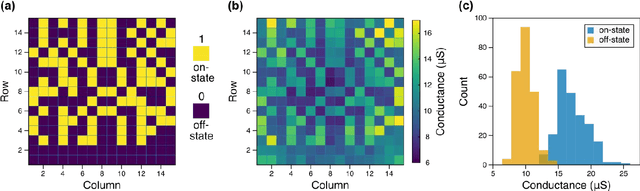
The increasing scale of neural networks and their growing application space have produced demand for more energy- and memory-efficient artificial-intelligence-specific hardware. Avenues to mitigate the main issue, the von Neumann bottleneck, include in-memory and near-memory architectures, as well as algorithmic approaches. Here we leverage the low-power and the inherently binary operation of magnetic tunnel junctions (MTJs) to demonstrate neural network hardware inference based on passive arrays of MTJs. In general, transferring a trained network model to hardware for inference is confronted by degradation in performance due to device-to-device variations, write errors, parasitic resistance, and nonidealities in the substrate. To quantify the effect of these hardware realities, we benchmark 300 unique weight matrix solutions of a 2-layer perceptron to classify the Wine dataset for both classification accuracy and write fidelity. Despite device imperfections, we achieve software-equivalent accuracy of up to 95.3 % with proper tuning of network parameters in 15 x 15 MTJ arrays having a range of device sizes. The success of this tuning process shows that new metrics are needed to characterize the performance and quality of networks reproduced in mixed signal hardware.
Associative Memories Using Complex-Valued Hopfield Networks Based on Spin-Torque Oscillator Arrays
Dec 06, 2021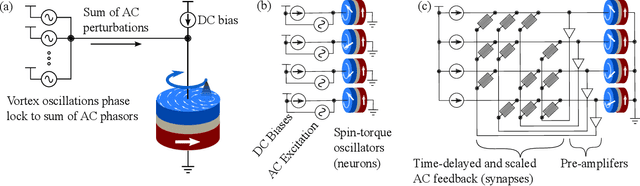
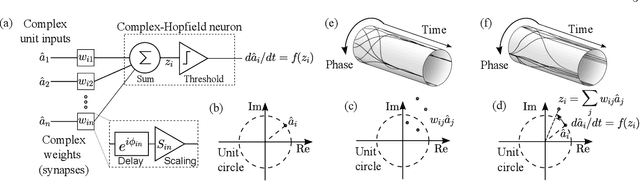
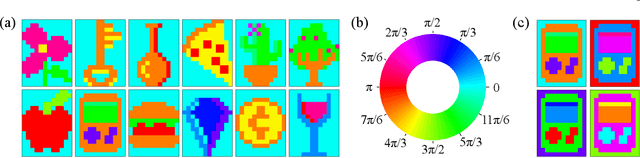
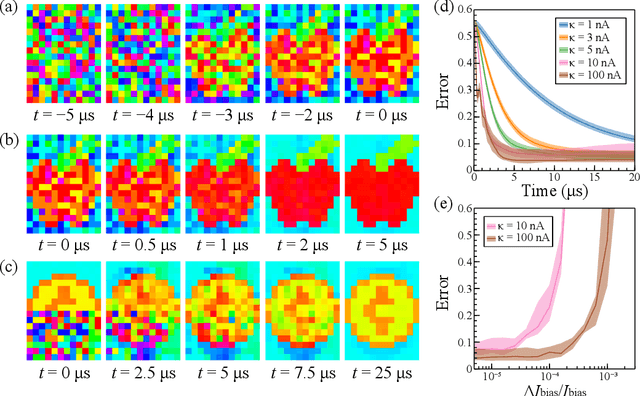
Simulations of complex-valued Hopfield networks based on spin-torque oscillators can recover phase-encoded images. Sequences of memristor-augmented inverters provide tunable delay elements that implement complex weights by phase shifting the oscillatory output of the oscillators. Pseudo-inverse training suffices to store at least 12 images in a set of 192 oscillators, representing 16$\times$12 pixel images. The energy required to recover an image depends on the desired error level. For the oscillators and circuitry considered here, 5 % root mean square deviations from the ideal image require approximately 5 $\mu$s and consume roughly 130 nJ. Simulations show that the network functions well when the resonant frequency of the oscillators can be tuned to have a fractional spread less than $10^{-3}$, depending on the strength of the feedback.
Memory-efficient training with streaming dimensionality reduction
Apr 25, 2020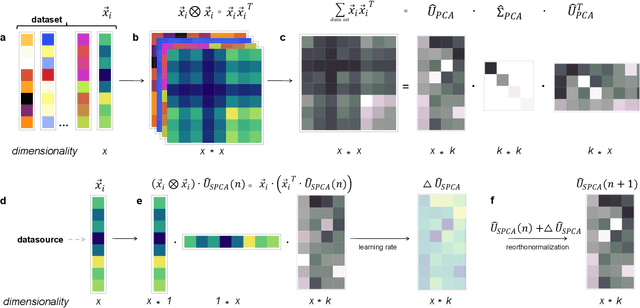
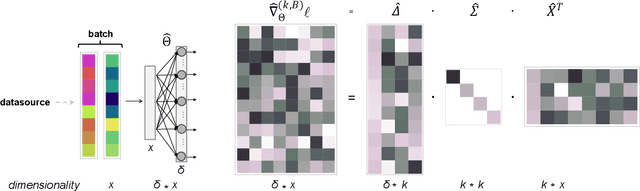
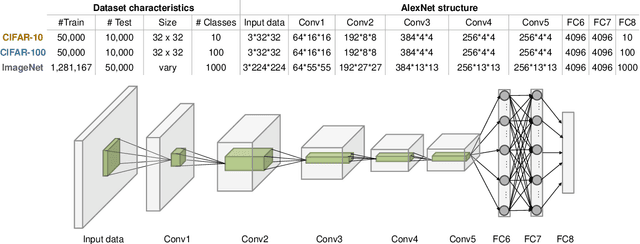
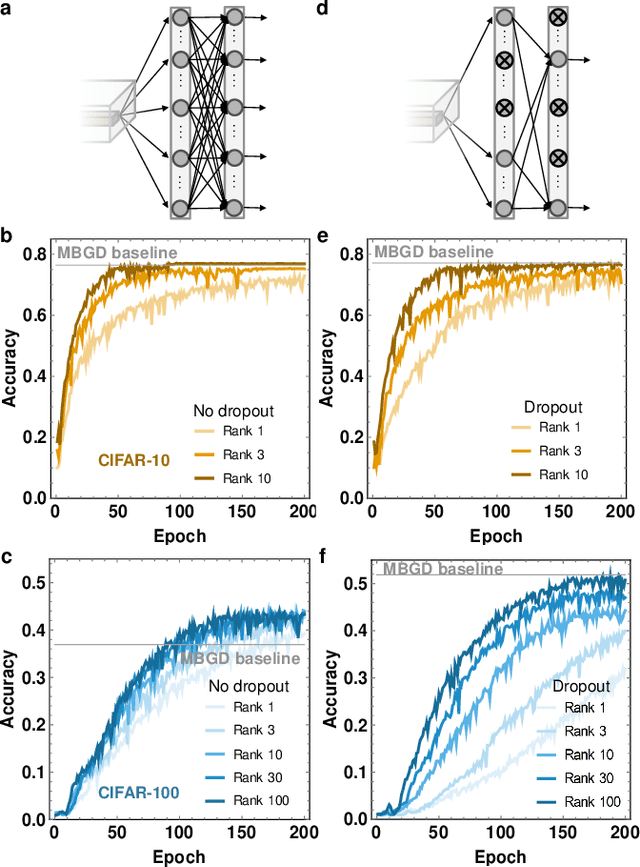
The movement of large quantities of data during the training of a Deep Neural Network presents immense challenges for machine learning workloads. To minimize this overhead, especially on the movement and calculation of gradient information, we introduce streaming batch principal component analysis as an update algorithm. Streaming batch principal component analysis uses stochastic power iterations to generate a stochastic k-rank approximation of the network gradient. We demonstrate that the low rank updates produced by streaming batch principal component analysis can effectively train convolutional neural networks on a variety of common datasets, with performance comparable to standard mini batch gradient descent. These results can lead to both improvements in the design of application specific integrated circuits for deep learning and in the speed of synchronization of machine learning models trained with data parallelism.
Streaming Batch Eigenupdates for Hardware Neuromorphic Networks
Mar 05, 2019
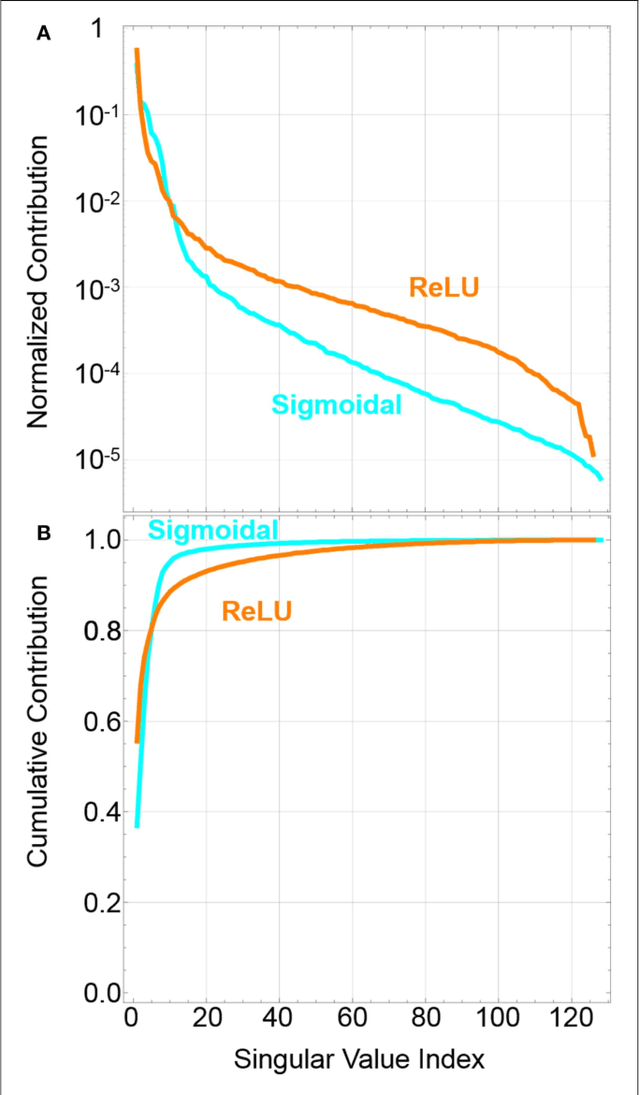
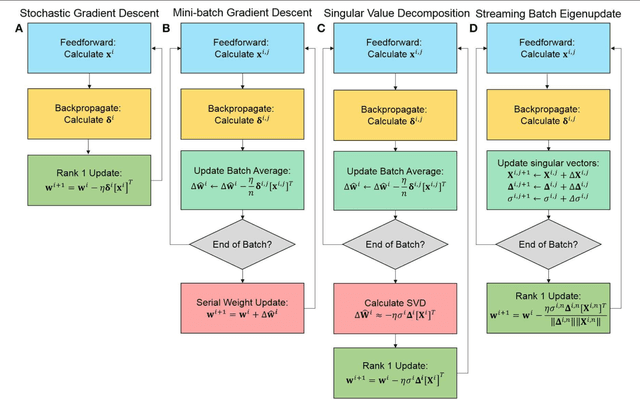
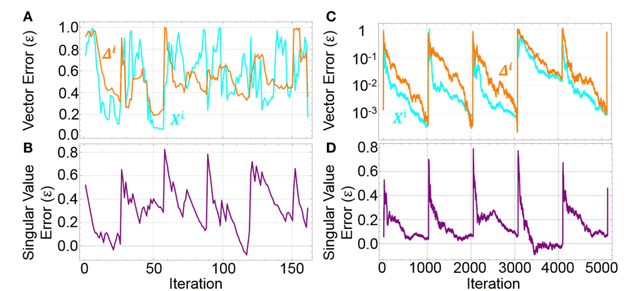
Neuromorphic networks based on nanodevices, such as metal oxide memristors, phase change memories, and flash memory cells, have generated considerable interest for their increased energy efficiency and density in comparison to graphics processing units (GPUs) and central processing units (CPUs). Though immense acceleration of the training process can be achieved by leveraging the fact that the time complexity of training does not scale with the network size, it is limited by the space complexity of stochastic gradient descent, which grows quadratically. The main objective of this work is to reduce this space complexity by using low-rank approximations of stochastic gradient descent. This low spatial complexity combined with streaming methods allows for significant reductions in memory and compute overhead, opening the doors for improvements in area, time and energy efficiency of training. We refer to this algorithm and architecture to implement it as the streaming batch eigenupdate (SBE) approach.