 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplitting EUD graphs into trees: A quick and clatty approach
Jul 18, 2021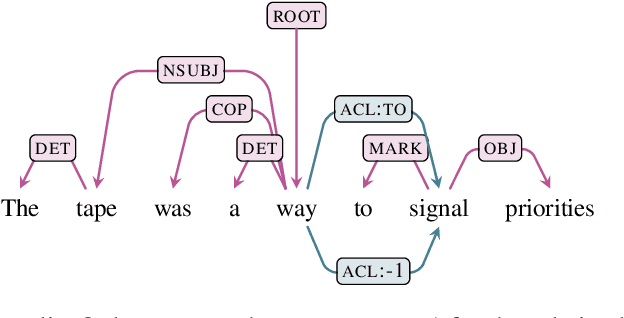
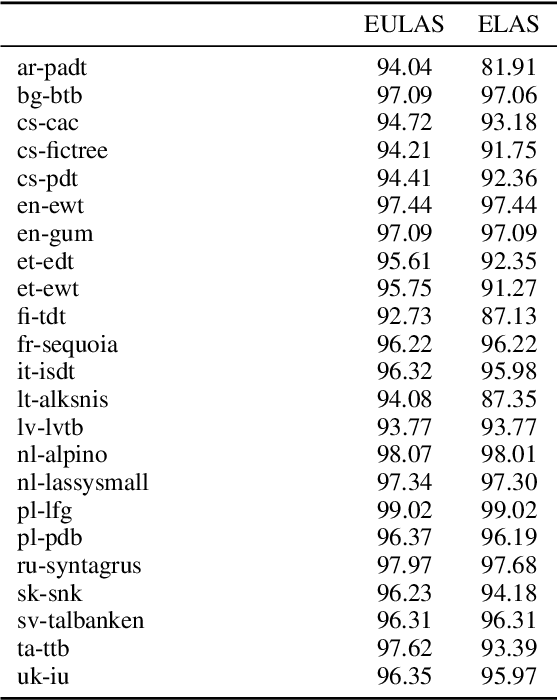
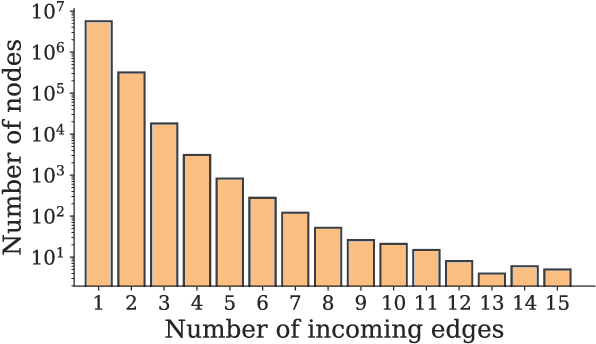
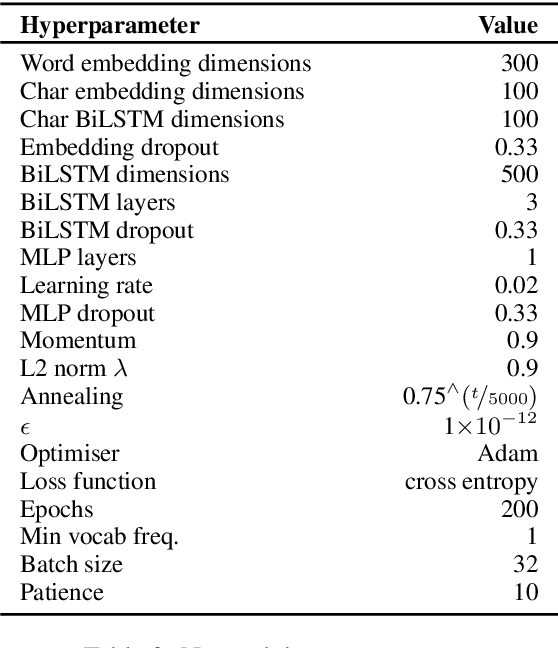
We present the system submission from the FASTPARSE team for the EUD Shared Task at IWPT 2021. We engaged in the task last year by focusing on efficiency. This year we have focused on experimenting with new ideas on a limited time budget. Our system is based on splitting the EUD graph into several trees, based on linguistic criteria. We predict these trees using a sequence-labelling parser and combine them into an EUD graph. The results were relatively poor, although not a total disaster and could probably be improved with some polishing of the system's rough edges.
A Modest Pareto Optimisation Analysis of Dependency Parsers in 2021
Jun 09, 2021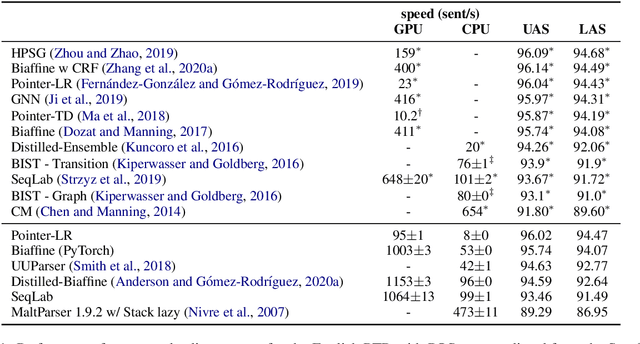
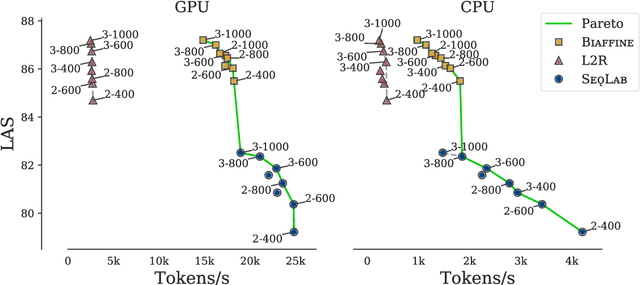
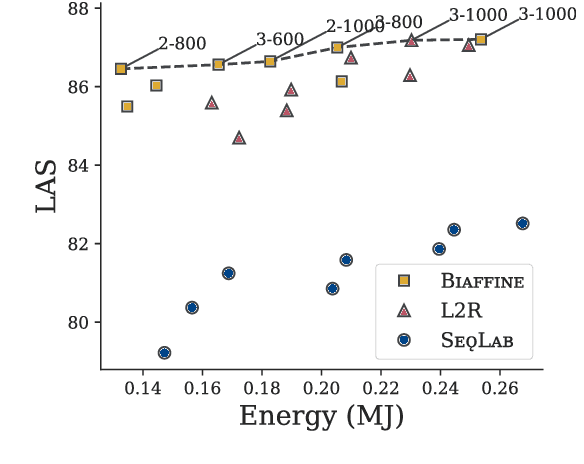

We evaluate three leading dependency parser systems from different paradigms on a small yet diverse subset of languages in terms of their accuracy-efficiency Pareto front. As we are interested in efficiency, we evaluate core parsers without pretrained language models (as these are typically huge networks and would constitute most of the compute time) or other augmentations that can be transversally applied to any of them. Biaffine parsing emerges as a well-balanced default choice, with sequence-labelling parsing being preferable if inference speed (but not training energy cost) is the priority.
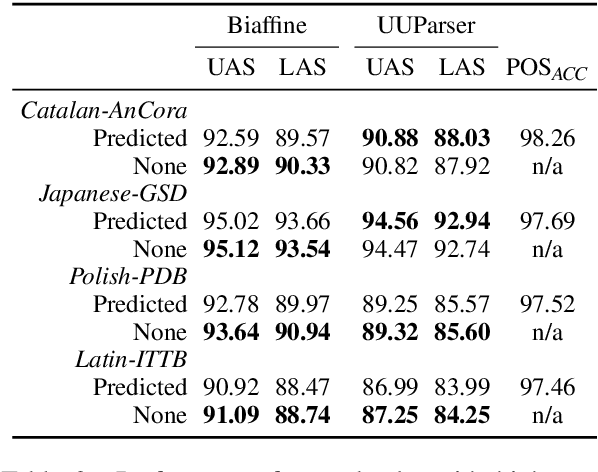
A Falta de Pan, Buenas Son Tortas: The Efficacy of Predicted UPOS Tags for Low Resource UD Parsing
Jun 08, 2021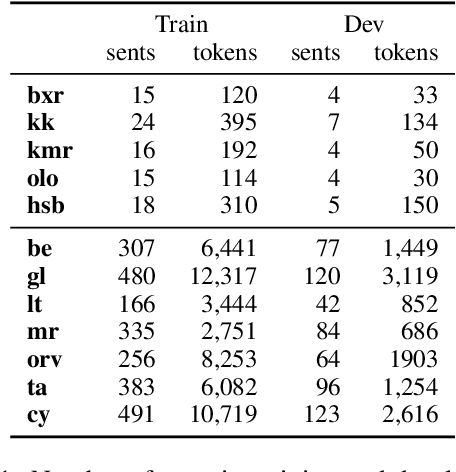
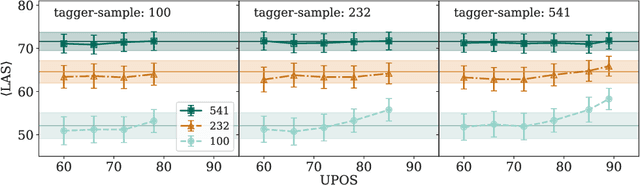
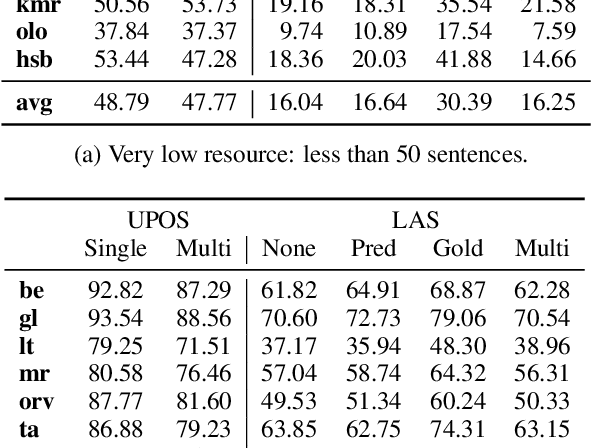
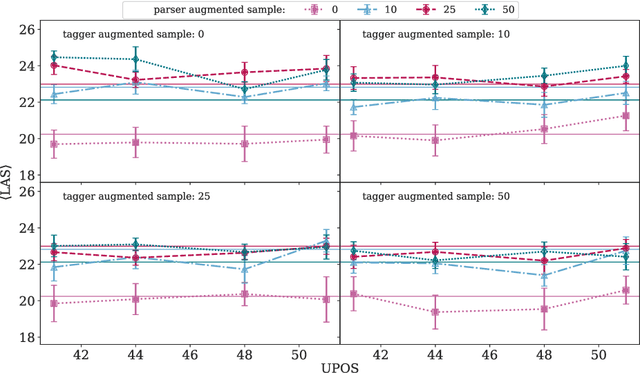
We evaluate the efficacy of predicted UPOS tags as input features for dependency parsers in lower resource settings to evaluate how treebank size affects the impact tagging accuracy has on parsing performance. We do this for real low resource universal dependency treebanks, artificially low resource data with varying treebank sizes, and for very small treebanks with varying amounts of augmented data. We find that predicted UPOS tags are somewhat helpful for low resource treebanks, especially when fewer fully-annotated trees are available. We also find that this positive impact diminishes as the amount of data increases.
John praised Mary because he? Implicit Causality Bias and Its Interaction with Explicit Cues in LMs
Jun 02, 2021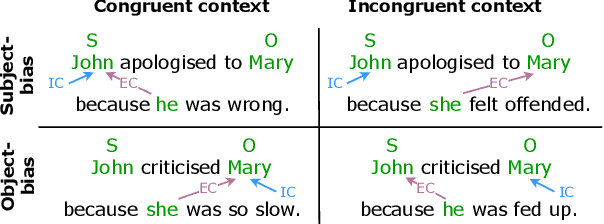
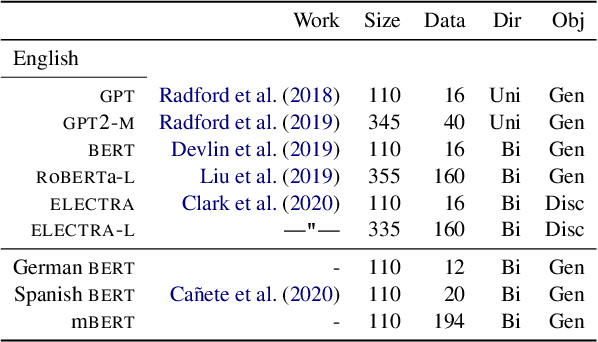
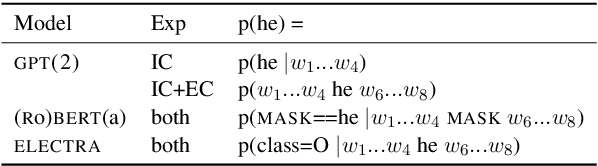
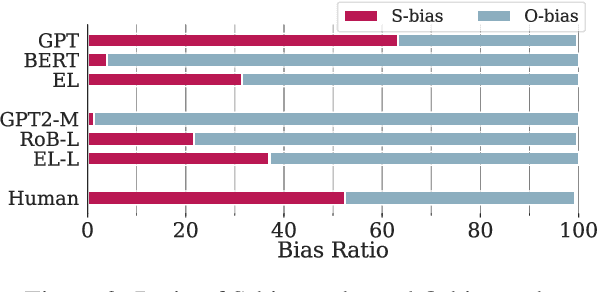
Some interpersonal verbs can implicitly attribute causality to either their subject or their object and are therefore said to carry an implicit causality (IC) bias. Through this bias, causal links can be inferred from a narrative, aiding language comprehension. We investigate whether pre-trained language models (PLMs) encode IC bias and use it at inference time. We find that to be the case, albeit to different degrees, for three distinct PLM architectures. However, causes do not always need to be implicit -- when a cause is explicitly stated in a subordinate clause, an incongruent IC bias associated with the verb in the main clause leads to a delay in human processing. We hypothesize that the temporary challenge humans face in integrating the two contradicting signals, one from the lexical semantics of the verb, one from the sentence-level semantics, would be reflected in higher error rates for models on tasks dependent on causal links. The results of our study lend support to this hypothesis, suggesting that PLMs tend to prioritize lexical patterns over higher-order signals.
Replicating and Extending "Because Their Treebanks Leak": Graph Isomorphism, Covariants, and Parser Performance
Jun 02, 2021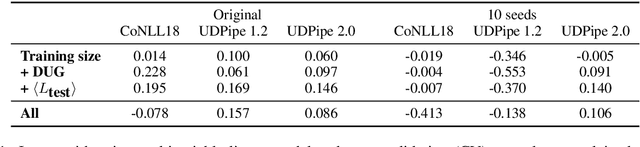
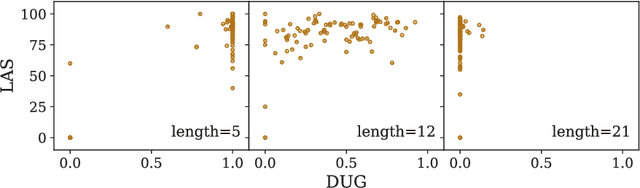
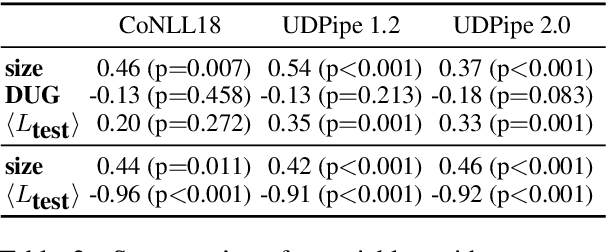
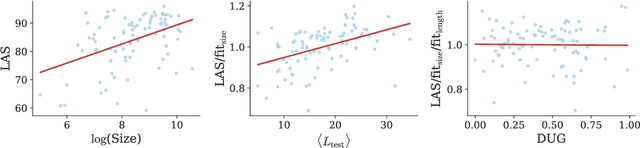
S{\o}gaard (2020) obtained results suggesting the fraction of trees occurring in the test data isomorphic to trees in the training set accounts for a non-trivial variation in parser performance. Similar to other statistical analyses in NLP, the results were based on evaluating linear regressions. However, the study had methodological issues and was undertaken using a small sample size leading to unreliable results. We present a replication study in which we also bin sentences by length and find that only a small subset of sentences vary in performance with respect to graph isomorphism. Further, the correlation observed between parser performance and graph isomorphism in the wild disappears when controlling for covariants. However, in a controlled experiment, where covariants are kept fixed, we do observe a strong correlation. We suggest that conclusions drawn from statistical analyses like this need to be tempered and that controlled experiments can complement them by more readily teasing factors apart.
What Taggers Fail to Learn, Parsers Need the Most
Apr 02, 2021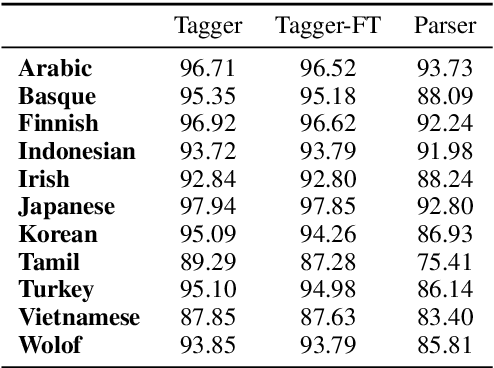
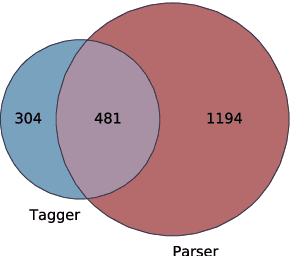
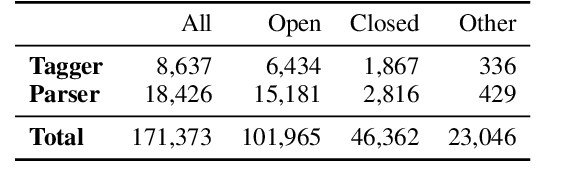
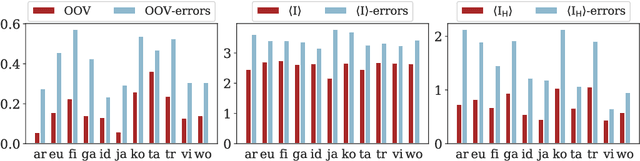
We present an error analysis of neural UPOS taggers to evaluate why using gold standard tags has such a large positive contribution to parsing performance while using predicted UPOS tags either harms performance or offers a negligible improvement. We evaluate what neural dependency parsers implicitly learn about word types and how this relates to the errors taggers make to explain the minimal impact using predicted tags has on parsers. We also present a short analysis on what contexts result in reductions in tagging performance. We then mask UPOS tags based on errors made by taggers to tease away the contribution of UPOS tags which taggers succeed and fail to classify correctly and the impact of tagging errors.
On the Frailty of Universal POS Tags for Neural UD Parsers
Oct 14, 2020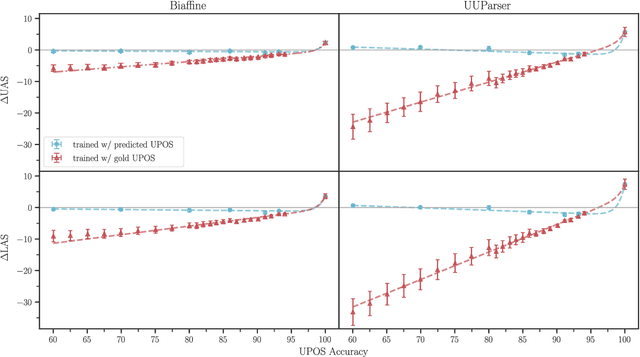
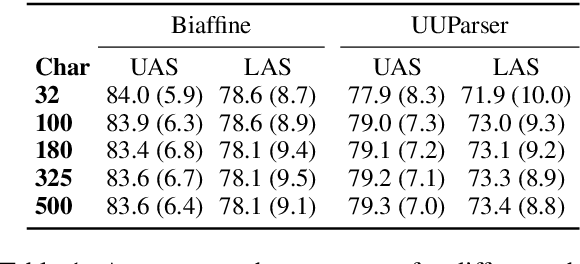
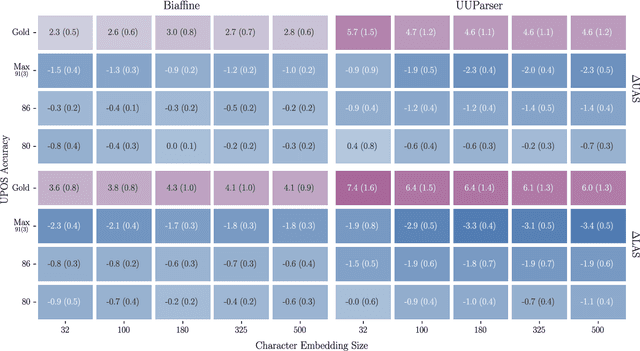
We present an analysis on the effect UPOS accuracy has on parsing performance. Results suggest that leveraging UPOS tags as features for neural parsers requires a prohibitively high tagging accuracy and that the use of gold tags offers a non-linear increase in performance, suggesting some sort of exceptionality. We also investigate what aspects of predicted UPOS tags impact parsing accuracy the most, highlighting some potentially meaningful linguistic facets of the problem.
Distilling Neural Networks for Greener and Faster Dependency Parsing
Jun 01, 2020

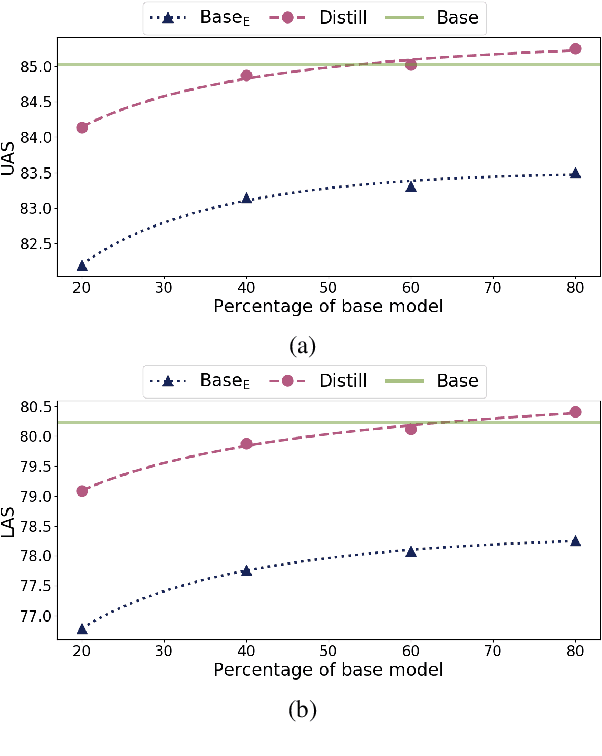
The carbon footprint of natural language processing research has been increasing in recent years due to its reliance on large and inefficient neural network implementations. Distillation is a network compression technique which attempts to impart knowledge from a large model to a smaller one. We use teacher-student distillation to improve the efficiency of the Biaffine dependency parser which obtains state-of-the-art performance with respect to accuracy and parsing speed (Dozat and Manning, 2017). When distilling to 20\% of the original model's trainable parameters, we only observe an average decrease of $\sim$1 point for both UAS and LAS across a number of diverse Universal Dependency treebanks while being 2.30x (1.19x) faster than the baseline model on CPU (GPU) at inference time. We also observe a small increase in performance when compressing to 80\% for some treebanks. Finally, through distillation we attain a parser which is not only faster but also more accurate than the fastest modern parser on the Penn Treebank.
Efficient EUD Parsing
Jun 01, 2020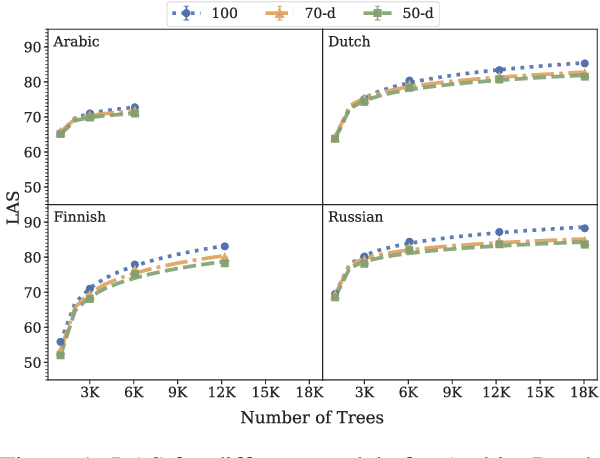
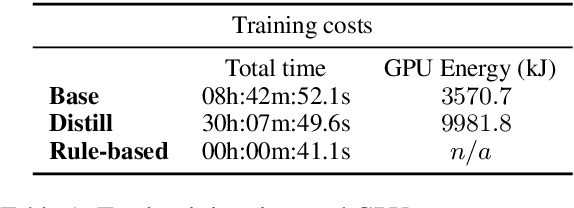
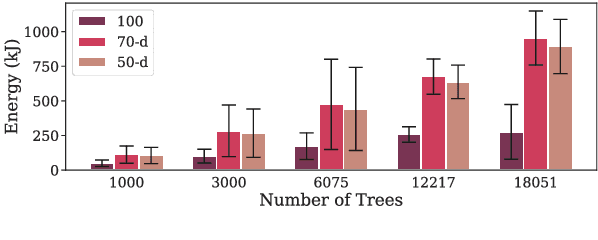
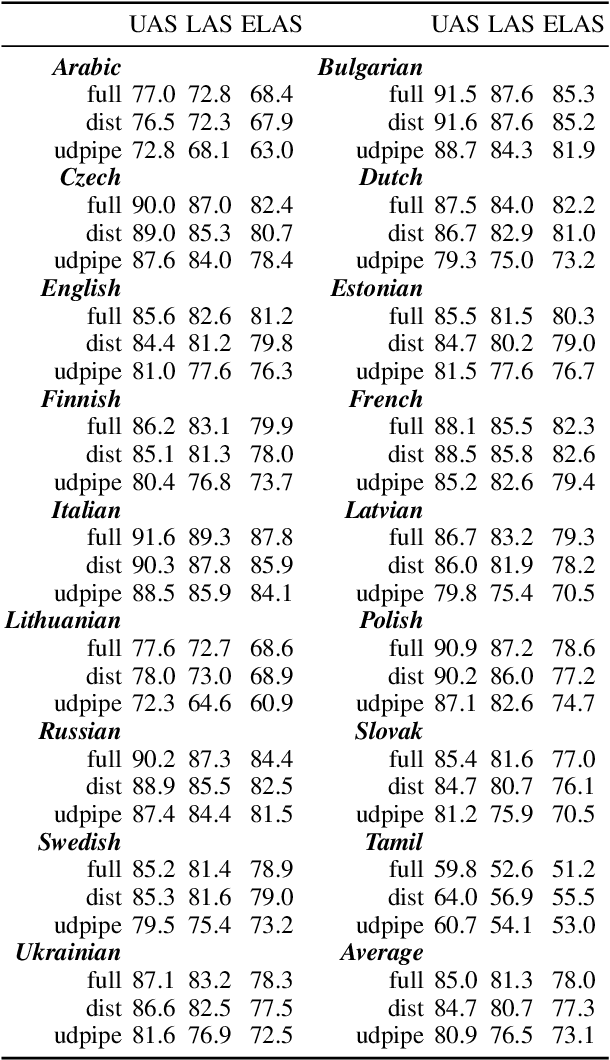
We present the system submission from the FASTPARSE team for the EUD Shared Task at IWPT 2020. We engaged with the task by focusing on efficiency. For this we considered training costs and inference efficiency. Our models are a combination of distilled neural dependency parsers and a rule-based system that projects UD trees into EUD graphs. We obtained an average ELAS of 74.04 for our official submission, ranking 4th overall.
Inherent Dependency Displacement Bias of Transition-Based Algorithms
Mar 31, 2020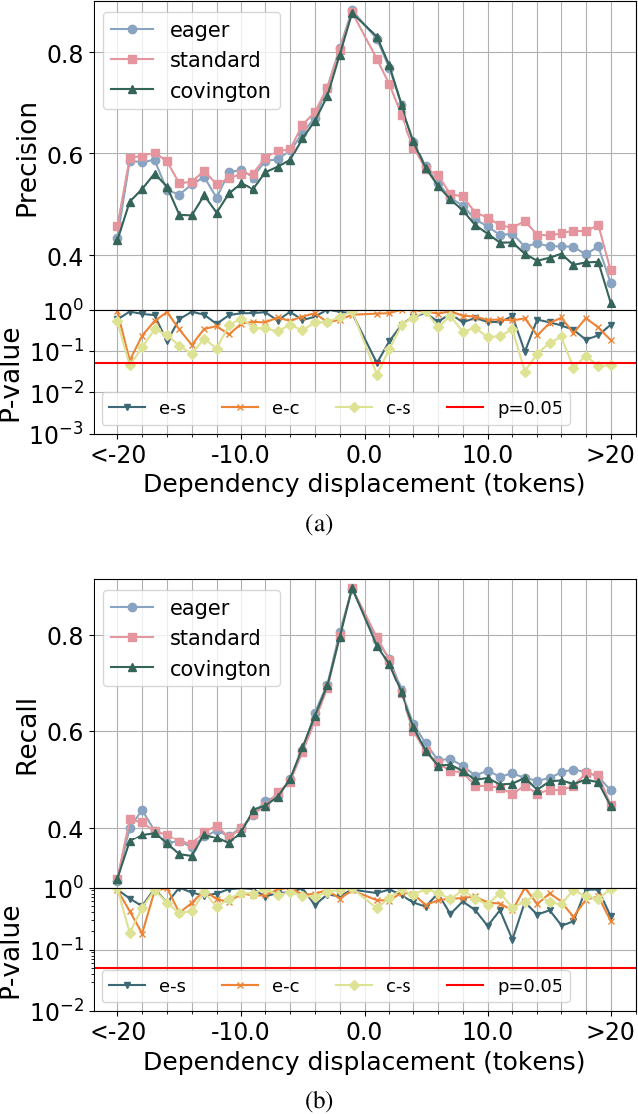
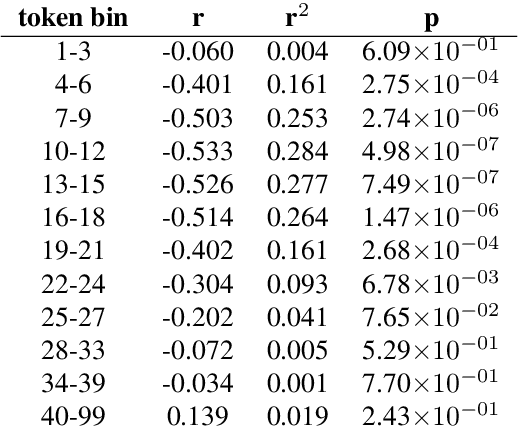
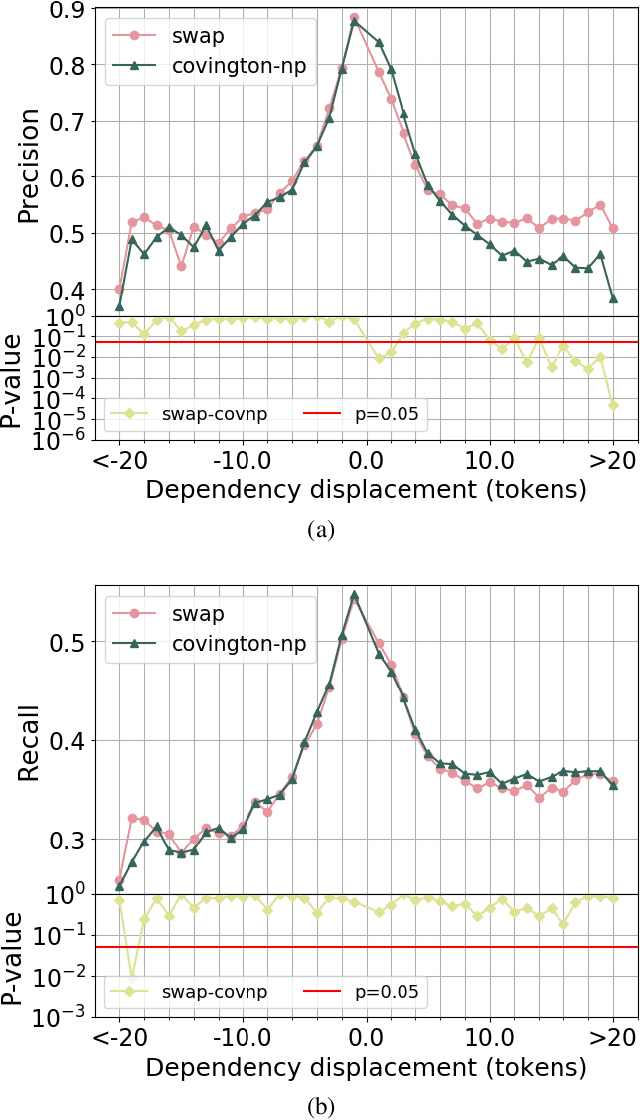
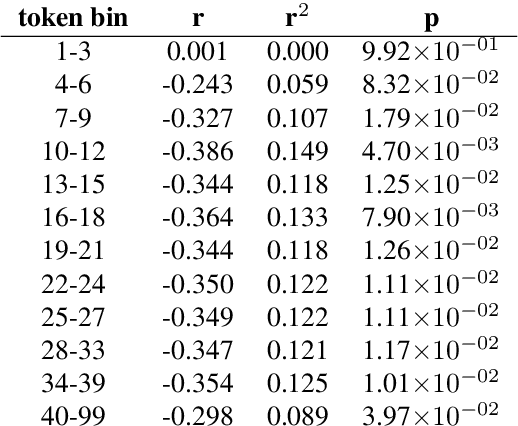
A wide variety of transition-based algorithms are currently used for dependency parsers. Empirical studies have shown that performance varies across different treebanks in such a way that one algorithm outperforms another on one treebank and the reverse is true for a different treebank. There is often no discernible reason for what causes one algorithm to be more suitable for a certain treebank and less so for another. In this paper we shed some light on this by introducing the concept of an algorithm's inherent dependency displacement distribution. This characterises the bias of the algorithm in terms of dependency displacement, which quantify both distance and direction of syntactic relations. We show that the similarity of an algorithm's inherent distribution to a treebank's displacement distribution is clearly correlated to the algorithm's parsing performance on that treebank, specifically with highly significant and substantial correlations for the predominant sentence lengths in Universal Dependency treebanks. We also obtain results which show a more discrete analysis of dependency displacement does not result in any meaningful correlations.