 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Challenges in Differentially-Private Federated Survival Analysis of Medical Data
Feb 08, 2022
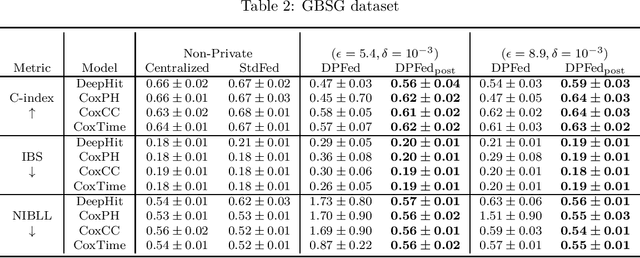
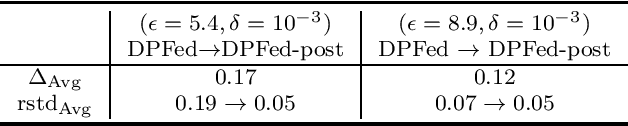
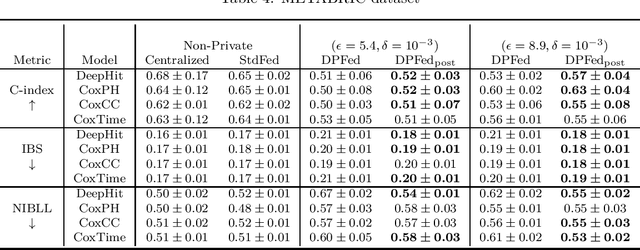
Survival analysis or time-to-event analysis aims to model and predict the time it takes for an event of interest to happen in a population or an individual. In the medical context this event might be the time of dying, metastasis, recurrence of cancer, etc. Recently, the use of neural networks that are specifically designed for survival analysis has become more popular and an attractive alternative to more traditional methods. In this paper, we take advantage of the inherent properties of neural networks to federate the process of training of these models. This is crucial in the medical domain since data is scarce and collaboration of multiple health centers is essential to make a conclusive decision about the properties of a treatment or a disease. To ensure the privacy of the datasets, it is common to utilize differential privacy on top of federated learning. Differential privacy acts by introducing random noise to different stages of training, thus making it harder for an adversary to extract details about the data. However, in the realistic setting of small medical datasets and only a few data centers, this noise makes it harder for the models to converge. To address this problem, we propose DPFed-post which adds a post-processing stage to the private federated learning scheme. This extra step helps to regulate the magnitude of the noisy average parameter update and easier convergence of the model. For our experiments, we choose 3 real-world datasets in the realistic setting when each health center has only a few hundred records, and we show that DPFed-post successfully increases the performance of the models by an average of up to $17\%$ compared to the standard differentially private federated learning scheme.
Open-Domain, Content-based, Multi-modal Fact-checking of Out-of-Context Images via Online Resources
Dec 07, 2021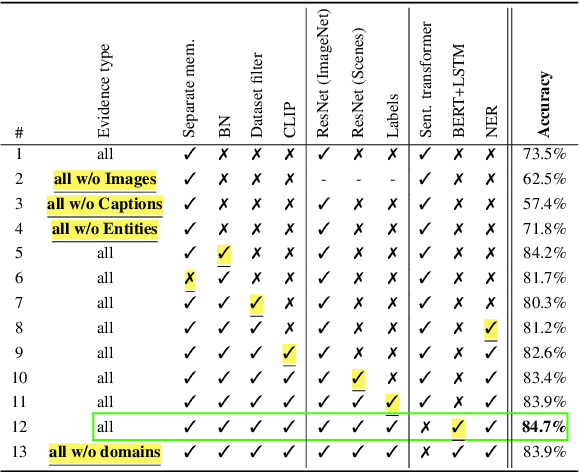
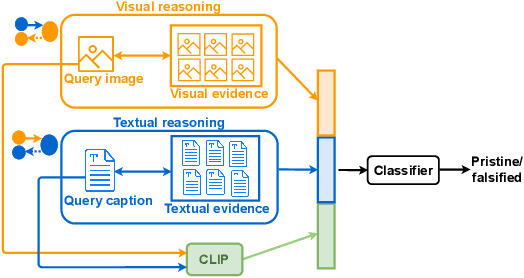
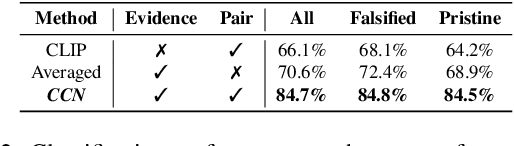
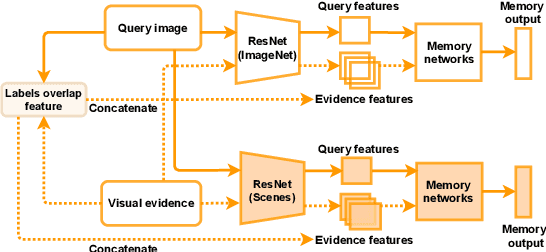
Misinformation is now a major problem due to its potential high risks to our core democratic and societal values and orders. Out-of-context misinformation is one of the easiest and effective ways used by adversaries to spread viral false stories. In this threat, a real image is re-purposed to support other narratives by misrepresenting its context and/or elements. The internet is being used as the go-to way to verify information using different sources and modalities. Our goal is an inspectable method that automates this time-consuming and reasoning-intensive process by fact-checking the image-caption pairing using Web evidence. To integrate evidence and cues from both modalities, we introduce the concept of 'multi-modal cycle-consistency check'; starting from the image/caption, we gather textual/visual evidence, which will be compared against the other paired caption/image, respectively. Moreover, we propose a novel architecture, Consistency-Checking Network (CCN), that mimics the layered human reasoning across the same and different modalities: the caption vs. textual evidence, the image vs. visual evidence, and the image vs. caption. Our work offers the first step and benchmark for open-domain, content-based, multi-modal fact-checking, and significantly outperforms previous baselines that did not leverage external evidence.
ProgFed: Effective, Communication, and Computation Efficient Federated Learning by Progressive Training
Oct 11, 2021
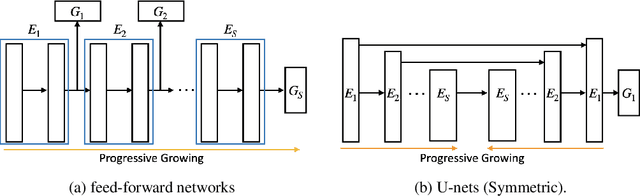
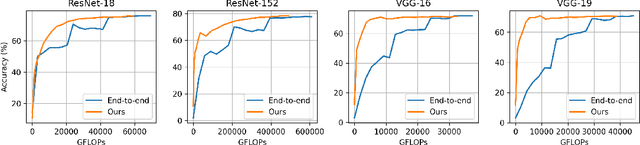
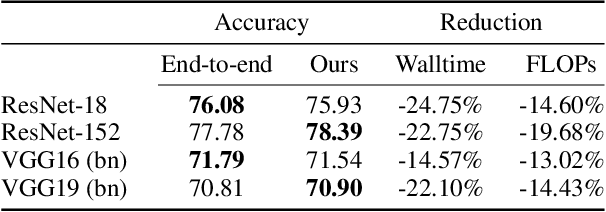
Federated learning is a powerful distributed learning scheme that allows numerous edge devices to collaboratively train a model without sharing their data. However, training is resource-intensive for edge devices, and limited network bandwidth is often the main bottleneck. Prior work often overcomes the constraints by condensing the models or messages into compact formats, e.g., by gradient compression or distillation. In contrast, we propose ProgFed, the first progressive training framework for efficient and effective federated learning. It inherently reduces computation and two-way communication costs while maintaining the strong performance of the final models. We theoretically prove that ProgFed converges at the same asymptotic rate as standard training on full models. Extensive results on a broad range of architectures, including CNNs (VGG, ResNet, ConvNets) and U-nets, and diverse tasks from simple classification to medical image segmentation show that our highly effective training approach saves up to $20\%$ computation and up to $63\%$ communication costs for converged models. As our approach is also complimentary to prior work on compression, we can achieve a wide range of trade-offs, showing reduced communication of up to $50\times$ at only $0.1\%$ loss in utility.
Optimising for Interpretability: Convolutional Dynamic Alignment Networks
Sep 27, 2021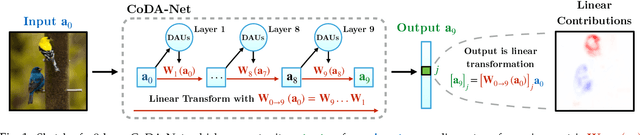
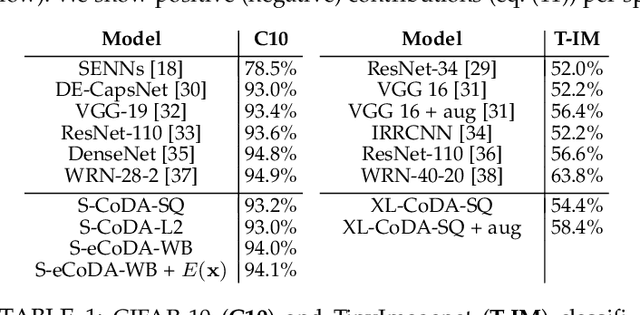
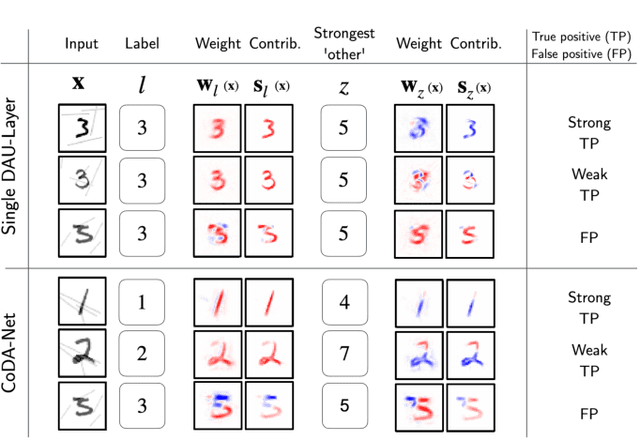
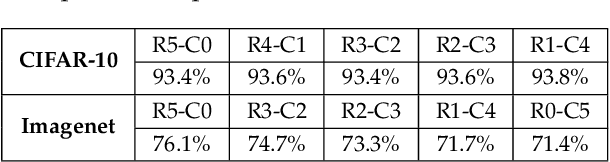
We introduce a new family of neural network models called Convolutional Dynamic Alignment Networks (CoDA Nets), which are performant classifiers with a high degree of inherent interpretability. Their core building blocks are Dynamic Alignment Units (DAUs), which are optimised to transform their inputs with dynamically computed weight vectors that align with task-relevant patterns. As a result, CoDA Nets model the classification prediction through a series of input-dependent linear transformations, allowing for linear decomposition of the output into individual input contributions. Given the alignment of the DAUs, the resulting contribution maps align with discriminative input patterns. These model-inherent decompositions are of high visual quality and outperform existing attribution methods under quantitative metrics. Further, CoDA Nets constitute performant classifiers, achieving on par results to ResNet and VGG models on e.g. CIFAR-10 and TinyImagenet. Lastly, CoDA Nets can be combined with conventional neural network models to yield powerful classifiers that more easily scale to complex datasets such as Imagenet whilst exhibiting an increased interpretable depth, i.e., the output can be explained well in terms of contributions from intermediate layers within the network.
Backdoor Attacks on Network Certification via Data Poisoning
Aug 25, 2021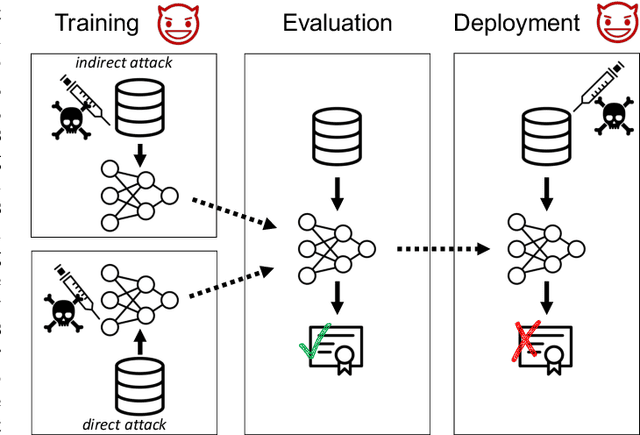

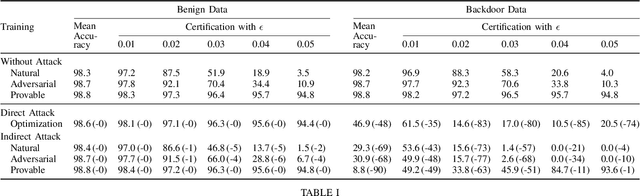
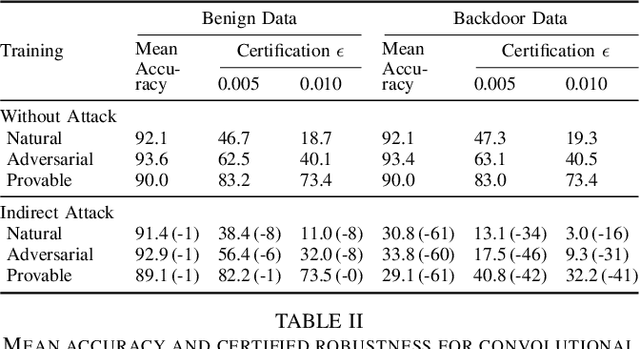
Certifiers for neural networks have made great progress towards provable robustness guarantees against evasion attacks using adversarial examples. However, introducing certifiers into deep learning systems also opens up new attack vectors, which need to be considered before deployment. In this work, we conduct the first systematic analysis of training time attacks against certifiers in practical application pipelines, identifying new threat vectors that can be exploited to degrade the overall system. Using these insights, we design two backdoor attacks against network certifiers, which can drastically reduce certified robustness when the backdoor is activated. For example, adding 1% poisoned data points during training is sufficient to reduce certified robustness by up to 95 percentage points, effectively rendering the certifier useless. We analyze how such novel attacks can compromise the overall system's integrity or availability. Our extensive experiments across multiple datasets, model architectures, and certifiers demonstrate the wide applicability of these attacks. A first investigation into potential defenses shows that current approaches only partially mitigate the issue, highlighting the need for new, more specific solutions.
Euro-PVI: Pedestrian Vehicle Interactions in Dense Urban Centers
Jun 22, 2021
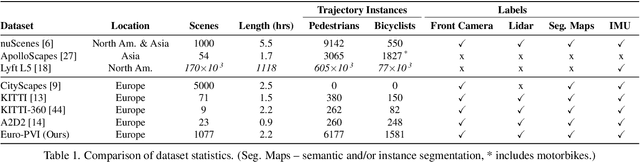
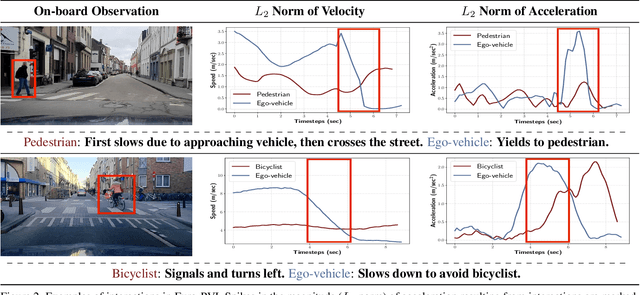
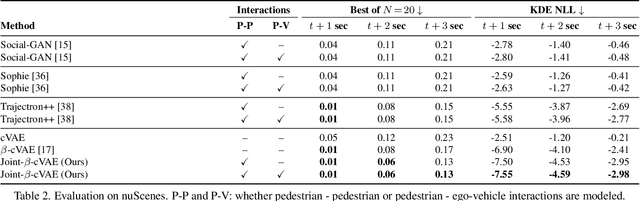
Accurate prediction of pedestrian and bicyclist paths is integral to the development of reliable autonomous vehicles in dense urban environments. The interactions between vehicle and pedestrian or bicyclist have a significant impact on the trajectories of traffic participants e.g. stopping or turning to avoid collisions. Although recent datasets and trajectory prediction approaches have fostered the development of autonomous vehicles yet the amount of vehicle-pedestrian (bicyclist) interactions modeled are sparse. In this work, we propose Euro-PVI, a dataset of pedestrian and bicyclist trajectories. In particular, our dataset caters more diverse and complex interactions in dense urban scenarios compared to the existing datasets. To address the challenges in predicting future trajectories with dense interactions, we develop a joint inference model that learns an expressive multi-modal shared latent space across agents in the urban scene. This enables our Joint-$\beta$-cVAE approach to better model the distribution of future trajectories. We achieve state of the art results on the nuScenes and Euro-PVI datasets demonstrating the importance of capturing interactions between ego-vehicle and pedestrians (bicyclists) for accurate predictions.
Beyond the Spectrum: Detecting Deepfakes via Re-Synthesis
May 29, 2021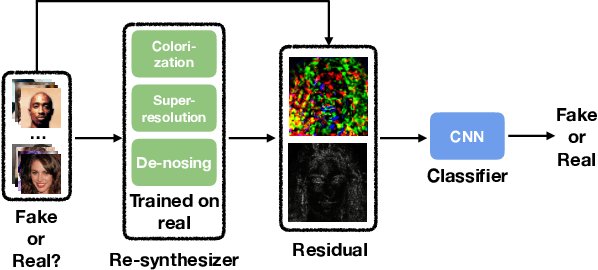
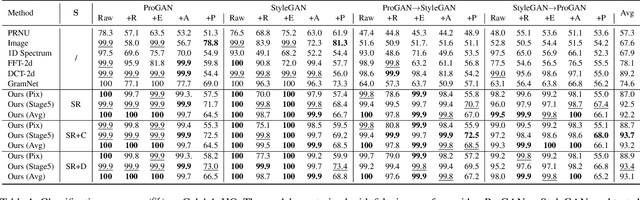
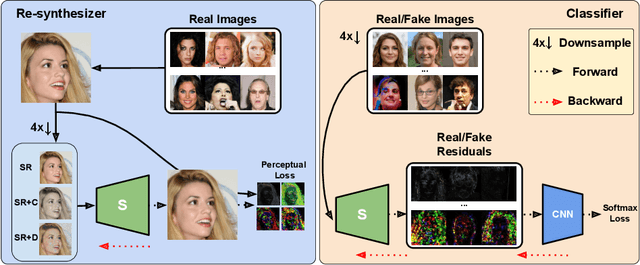
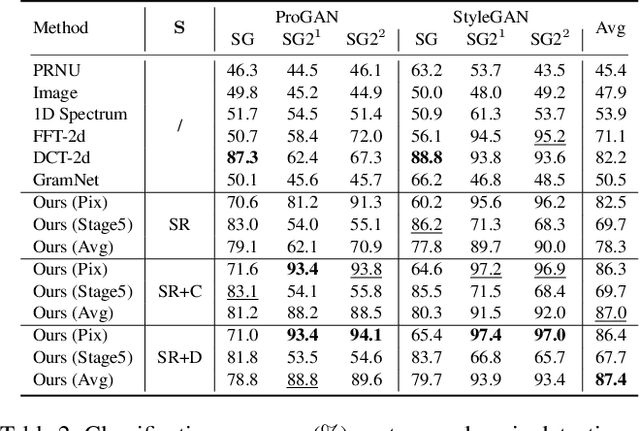
The rapid advances in deep generative models over the past years have led to highly {realistic media, known as deepfakes,} that are commonly indistinguishable from real to human eyes. These advances make assessing the authenticity of visual data increasingly difficult and pose a misinformation threat to the trustworthiness of visual content in general. Although recent work has shown strong detection accuracy of such deepfakes, the success largely relies on identifying frequency artifacts in the generated images, which will not yield a sustainable detection approach as generative models continue evolving and closing the gap to real images. In order to overcome this issue, we propose a novel fake detection that is designed to re-synthesize testing images and extract visual cues for detection. The re-synthesis procedure is flexible, allowing us to incorporate a series of visual tasks - we adopt super-resolution, denoising and colorization as the re-synthesis. We demonstrate the improved effectiveness, cross-GAN generalization, and robustness against perturbations of our approach in a variety of detection scenarios involving multiple generators over CelebA-HQ, FFHQ, and LSUN datasets. Source code is available at https://github.com/SSAW14/BeyondtheSpectrum.
Convolutional Dynamic Alignment Networks for Interpretable Classifications
Mar 31, 2021
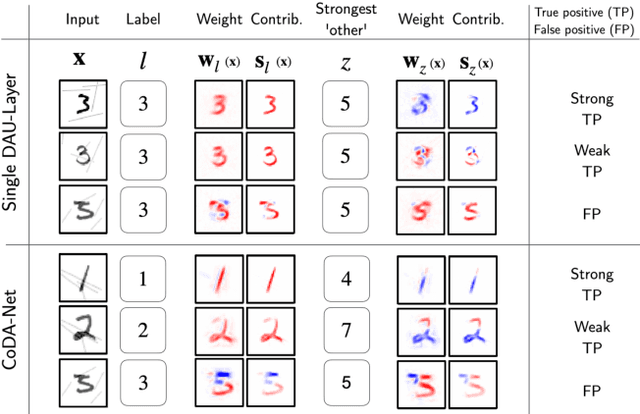

We introduce a new family of neural network models called Convolutional Dynamic Alignment Networks (CoDA-Nets), which are performant classifiers with a high degree of inherent interpretability. Their core building blocks are Dynamic Alignment Units (DAUs), which linearly transform their input with weight vectors that dynamically align with task-relevant patterns. As a result, CoDA-Nets model the classification prediction through a series of input-dependent linear transformations, allowing for linear decomposition of the output into individual input contributions. Given the alignment of the DAUs, the resulting contribution maps align with discriminative input patterns. These model-inherent decompositions are of high visual quality and outperform existing attribution methods under quantitative metrics. Further, CoDA-Nets constitute performant classifiers, achieving on par results to ResNet and VGG models on e.g. CIFAR-10 and TinyImagenet.
Dual Contrastive Loss and Attention for GANs
Mar 31, 2021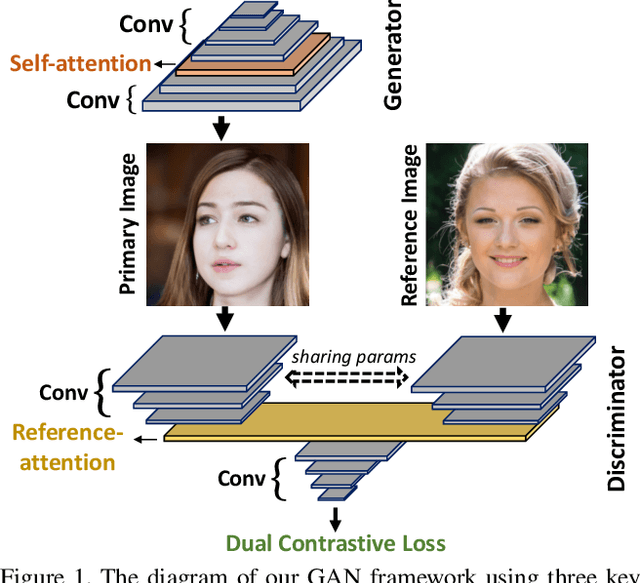
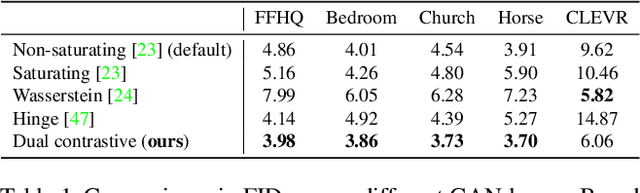
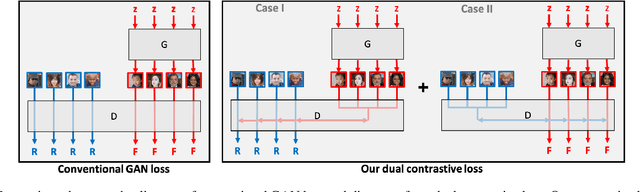

Generative Adversarial Networks (GANs) produce impressive results on unconditional image generation when powered with large-scale image datasets. Yet generated images are still easy to spot especially on datasets with high variance (e.g. bedroom, church). In this paper, we propose various improvements to further push the boundaries in image generation. Specifically, we propose a novel dual contrastive loss and show that, with this loss, discriminator learns more generalized and distinguishable representations to incentivize generation. In addition, we revisit attention and extensively experiment with different attention blocks in the generator. We find attention to be still an important module for successful image generation even though it was not used in the recent state-of-the-art models. Lastly, we study different attention architectures in the discriminator, and propose a reference attention mechanism. By combining the strengths of these remedies, we improve the compelling state-of-the-art Fr\'{e}chet Inception Distance (FID) by at least 17.5% on several benchmark datasets. We obtain even more significant improvements on compositional synthetic scenes (up to 47.5% in FID).
"What's in the box?!": Deflecting Adversarial Attacks by Randomly Deploying Adversarially-Disjoint Models
Mar 09, 2021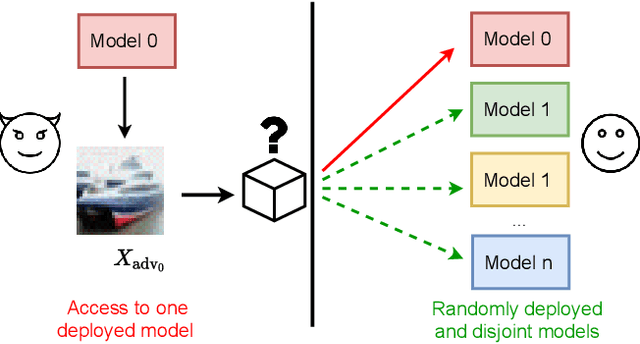
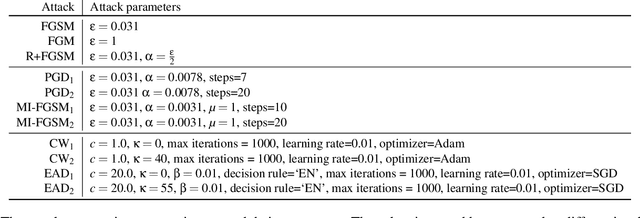
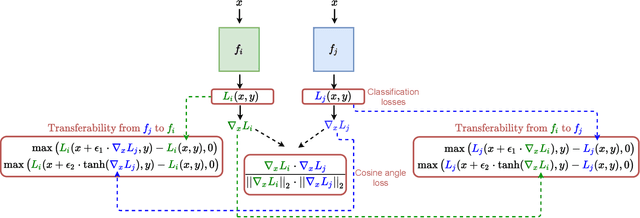
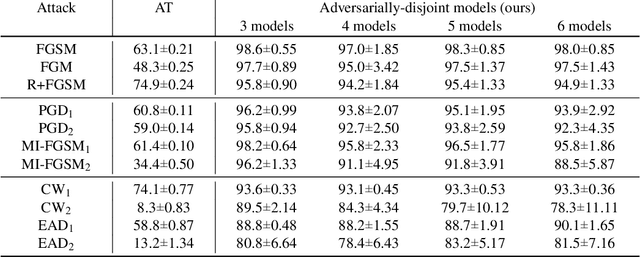
Machine learning models are now widely deployed in real-world applications. However, the existence of adversarial examples has been long considered a real threat to such models. While numerous defenses aiming to improve the robustness have been proposed, many have been shown ineffective. As these vulnerabilities are still nowhere near being eliminated, we propose an alternative deployment-based defense paradigm that goes beyond the traditional white-box and black-box threat models. Instead of training a single partially-robust model, one could train a set of same-functionality, yet, adversarially-disjoint models with minimal in-between attack transferability. These models could then be randomly and individually deployed, such that accessing one of them minimally affects the others. Our experiments on CIFAR-10 and a wide range of attacks show that we achieve a significantly lower attack transferability across our disjoint models compared to a baseline of ensemble diversity. In addition, compared to an adversarially trained set, we achieve a higher average robust accuracy while maintaining the accuracy of clean examples.