 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorfFlex: Handling Rich Morphology
Jun 23, 2026We present MorfFlex, a morphological dictionary architecture suitable for languages with extensive regularity in both inflection and derivation. As the primary example of MorfFlex in use we introduce MorfFlex CZ, a morphological dictionary of Czech. It is distributed as a simple, unstructured list of <wordform, lemma, tag> triplets, however, its manually maintained, unpublished source files and conversion scripts encode a sophisticated system of inflectional and derivational patterns. These patterns dramatically reduce the otherwise enormous size of the dictionary, which currently contains over 100 million wordforms and more than 1 million lemmas. The MorfFlex CZ dictionary serves as an essential resource for ensuring the consistency of manual morphological annotation in the Prague Dependency Treebanks and underpins state-of-the-art automatic tools such as MorphoDiTa. In this paper, we focus on: (i) presenting an effective method for managing the rich morphological system within the dictionary, and (ii) demonstrating the utility of such a language resource for maintaining annotation consistency in corpora and supporting the development of advanced NLP applications.
Meet UD_Czech-PDTC: A Large and Genre-Rich Treebank in Universal Dependencies
Jun 23, 2026Czech has been part of Universal Dependencies since its first release in 2015. It has also been one of the best represented languages, with the Prague Dependency Treebank being order of magnitude larger than most other UD treebanks. More recently, three other datasets from the Prague family were added and the annotations thoroughly revisited, forming the "Prague Dependency Treebank-Consolidated" (PDT-C). In comparison to the original PDT, PDT-C is more than twice as large, but it is also much more diverse in terms of genres and domains. In this paper, we describe the conversion of the new resource to Universal Dependencies. While the two annotation schemes are relatively similar at the first sight, there are numerous small differences in topology of the dependency structures and in granularity of the POS and relation type inventories. We demonstrate a selection of such differences on examples, discuss the diverging motivations, as well as ways to overcome the differences during conversion. We argue that while PDT is less "universal" and more tightly bound to one language, its multi-layer annotation is rich and provides all information needed for basic UD trees, and much more.
Prague Dependency Treebank -- Consolidated 2.0: Enriching a Complex Annotation Scheme
Jun 23, 2026The Prague Dependency Treebank framework is unique in its attempt to systematically include and link different layers of language, including a meaning representation with several types of inter-sentential phenomena, especially coreference and discourse relations. We present its second consolidated version (PDT-C 2.0), which concludes almost 30-years long project of sustained development of the resource to a uniformly and coherently annotated, genre-diversified, almost 4 million token language resource of Czech language, with accompanying fully compatible lexicons. In addition to continuous linguistic research, the richly linguistically annotated corpus is also widely used in international comparisons of the development of traditional and novel NLP tools as well as in conversions into other formalisms. The corpus and the trained parsers are available under the CC BY-NC-SA licence.
Quality and Efficiency of Manual Annotation: Pre-annotation Bias
Jun 15, 2023This paper presents an analysis of annotation using an automatic pre-annotation for a mid-level annotation complexity task -- dependency syntax annotation. It compares the annotation efforts made by annotators using a pre-annotated version (with a high-accuracy parser) and those made by fully manual annotation. The aim of the experiment is to judge the final annotation quality when pre-annotation is used. In addition, it evaluates the effect of automatic linguistically-based (rule-formulated) checks and another annotation on the same data available to the annotators, and their influence on annotation quality and efficiency. The experiment confirmed that the pre-annotation is an efficient tool for faster manual syntactic annotation which increases the consistency of the resulting annotation without reducing its quality.
Prague Dependency Treebank -- Consolidated 1.0
Jun 05, 2020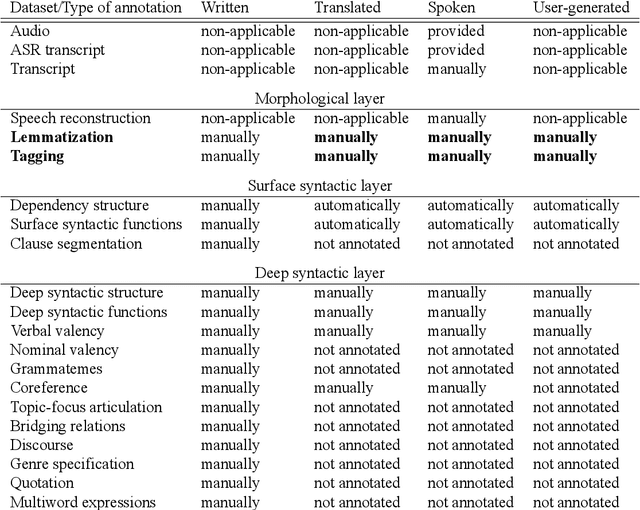
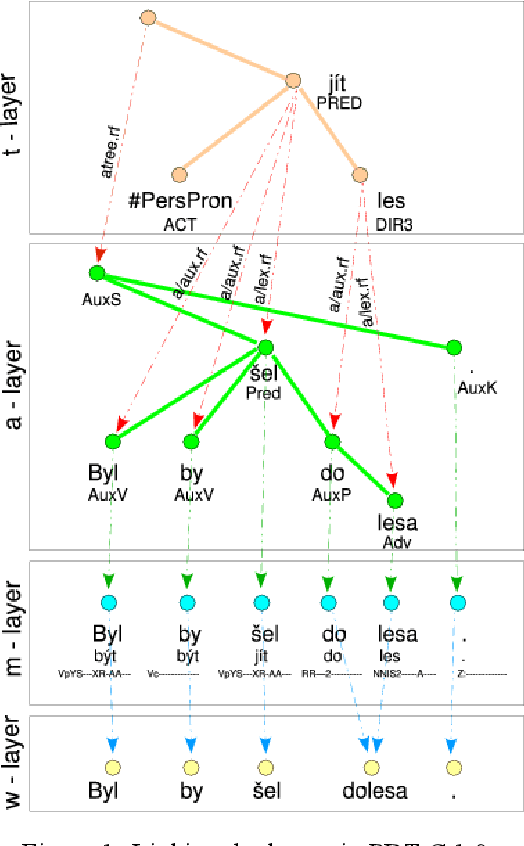


We present a richly annotated and genre-diversified language resource, the Prague Dependency Treebank-Consolidated 1.0 (PDT-C 1.0), the purpose of which is - as it always been the case for the family of the Prague Dependency Treebanks - to serve both as a training data for various types of NLP tasks as well as for linguistically-oriented research. PDT-C 1.0 contains four different datasets of Czech, uniformly annotated using the standard PDT scheme (albeit not everything is annotated manually, as we describe in detail here). The texts come from different sources: daily newspaper articles, Czech translation of the Wall Street Journal, transcribed dialogs and a small amount of user-generated, short, often non-standard language segments typed into a web translator. Altogether, the treebank contains around 180,000 sentences with their morphological, surface and deep syntactic annotation. The diversity of the texts and annotations should serve well the NLP applications as well as it is an invaluable resource for linguistic research, including comparative studies regarding texts of different genres. The corpus is publicly and freely available.