 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalorimetry with Deep Learning: Particle Simulation and Reconstruction for Collider Physics
Jan 08, 2020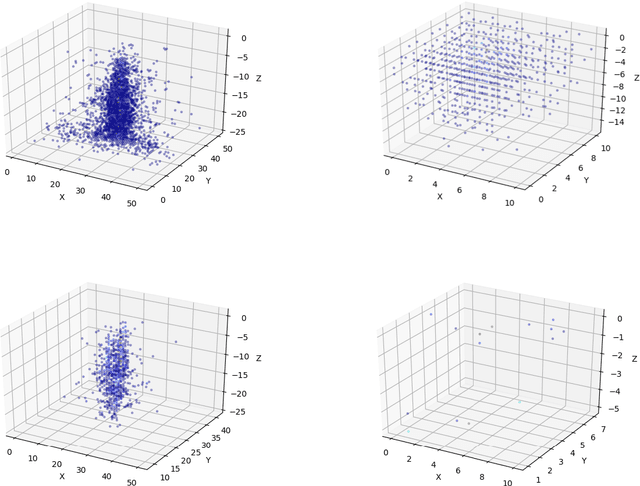
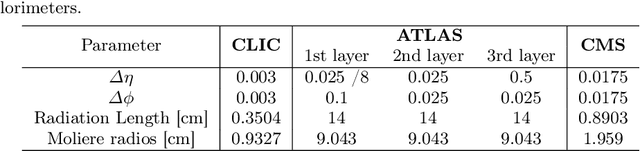
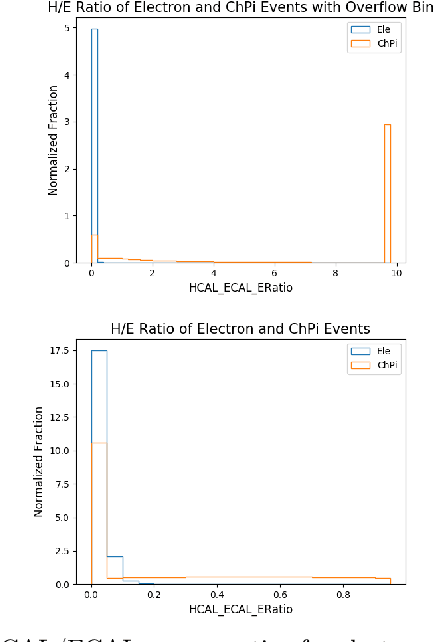
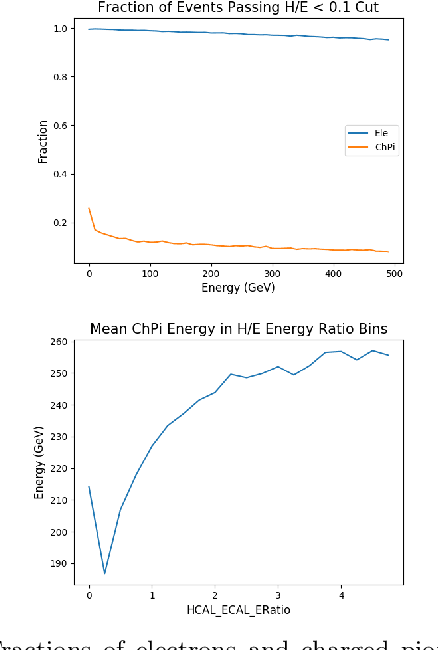
Using detailed simulations of calorimeter showers as training data, we investigate the use of deep learning algorithms for the simulation and reconstruction of particles produced in high-energy physics collisions. We train neural networks on shower data at the calorimeter-cell level, and show significant improvements for simulation and reconstruction when using these networks compared to methods which rely on currently-used state-of-the-art algorithms. We define two models: an end-to-end reconstruction network which performs simultaneous particle identification and energy regression of particles when given calorimeter shower data, and a generative network which can provide reasonable modeling of calorimeter showers for different particle types at specified angles and energies. We investigate the optimization of our models with hyperparameter scans. Furthermore, we demonstrate the applicability of the reconstruction model to shower inputs from other detector geometries, specifically ATLAS-like and CMS-like geometries. These networks can serve as fast and computationally light methods for particle shower simulation and reconstruction for current and future experiments at particle colliders.
Quantum adiabatic machine learning with zooming
Aug 13, 2019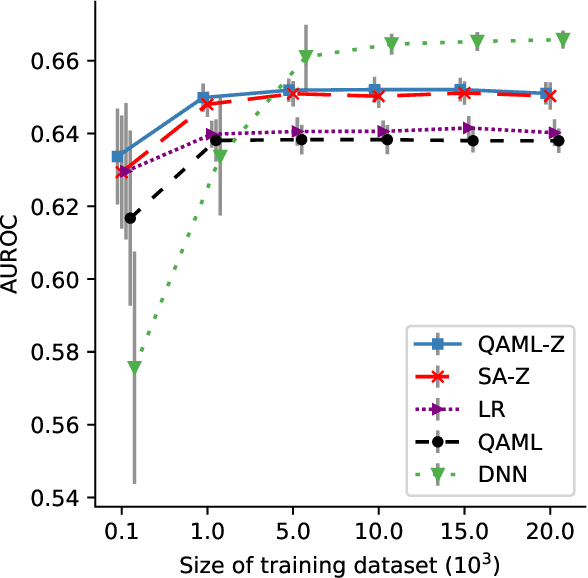
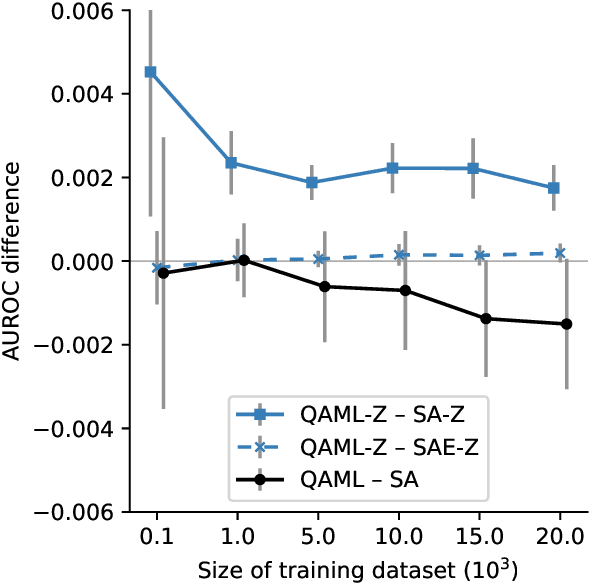
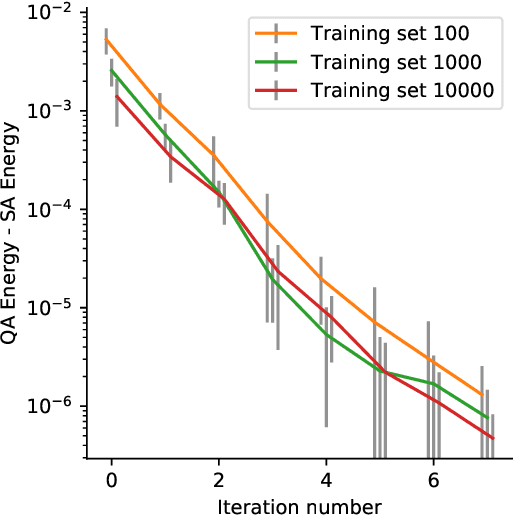
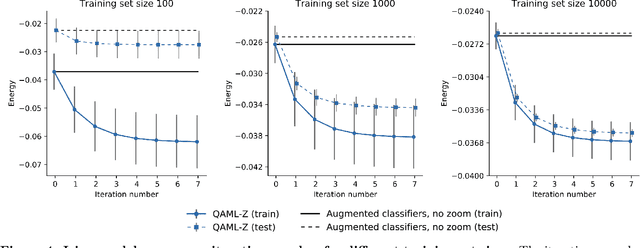
Recent work has shown that quantum annealing for machine learning (QAML) can perform comparably to state-of-the-art machine learning methods with a specific application to Higgs boson classification. We propose a variant algorithm (QAML-Z) that iteratively zooms in on a region of the energy surface by mapping the problem to a continuous space and sequentially applying quantum annealing to an augmented set of weak classifiers. Results on a programmable quantum annealer show that QAML-Z increases the performance difference between QAML and classical deep neural networks by over 40% as measured by area under the ROC curve for small training set sizes. Furthermore, QAML-Z reduces the advantage of deep neural networks over QAML for large training sets by around 50%, indicating that QAML-Z produces stronger classifiers that retain the robustness of the original QAML algorithm.
Charged particle tracking with quantum annealing-inspired optimization
Aug 13, 2019
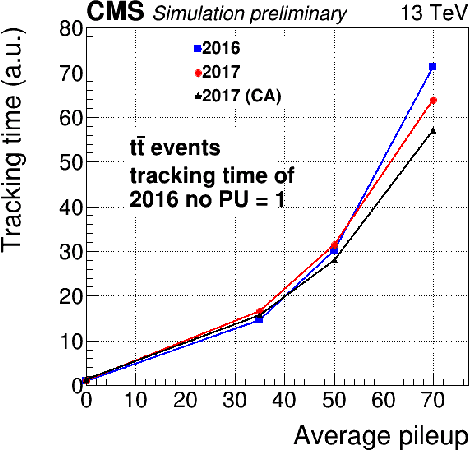
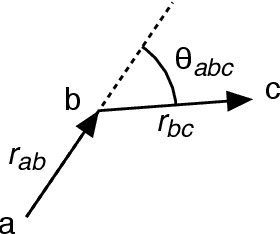
At the High Luminosity Large Hadron Collider (HL-LHC), traditional track reconstruction techniques that are critical for analysis are expected to face challenges due to scaling with track density. Quantum annealing has shown promise in its ability to solve combinatorial optimization problems amidst an ongoing effort to establish evidence of a quantum speedup. As a step towards exploiting such potential speedup, we investigate a track reconstruction approach by adapting the existing geometric Denby-Peterson (Hopfield) network method to the quantum annealing framework and to HL-LHC conditions. Furthermore, we develop additional techniques to embed the problem onto existing and near-term quantum annealing hardware. Results using simulated annealing and quantum annealing with the D-Wave 2X system on the TrackML dataset are presented, demonstrating the successful application of a quantum annealing-inspired algorithm to the track reconstruction challenge. We find that combinatorial optimization problems can effectively reconstruct tracks, suggesting possible applications for fast hardware-specific implementations at the LHC while leaving open the possibility of a quantum speedup for tracking.
Variational Autoencoders for New Physics Mining at the Large Hadron Collider
Dec 05, 2018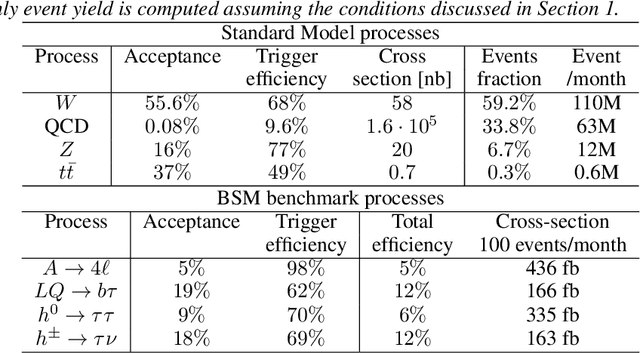
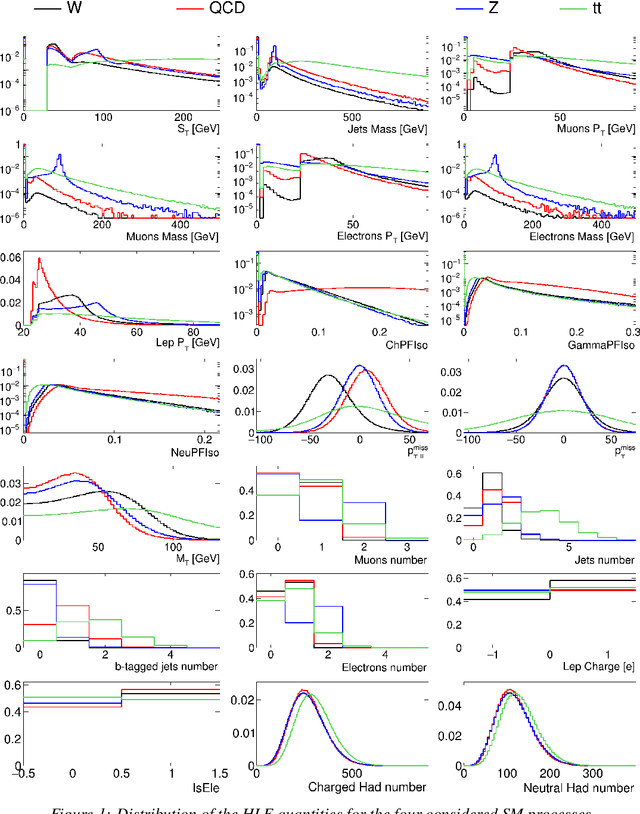
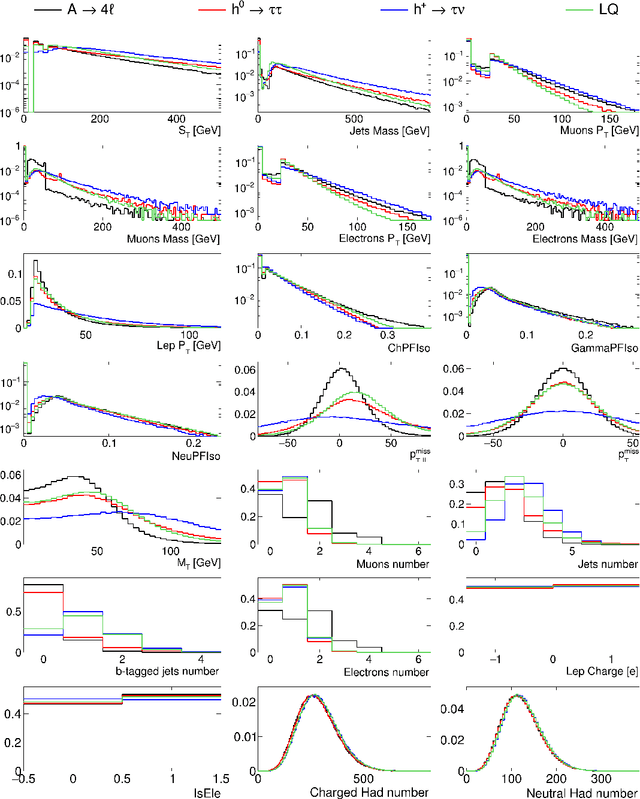
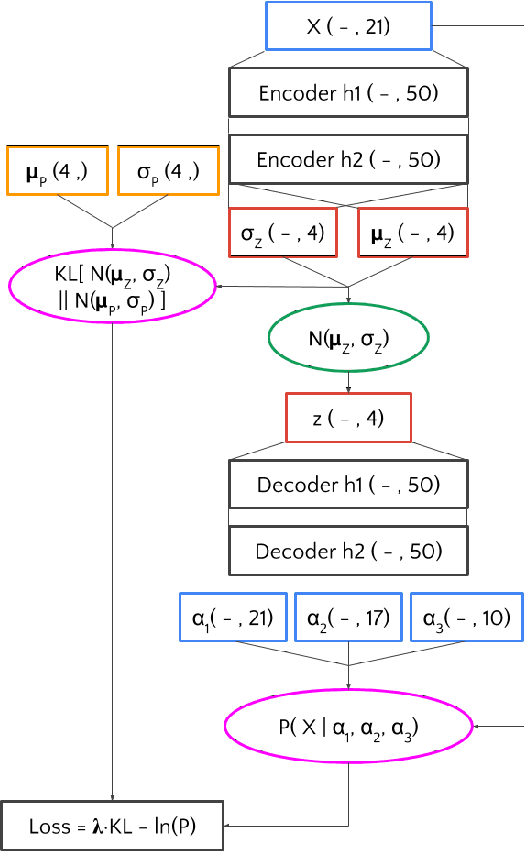
Using variational autoencoders trained on known physics processes, we develop a one-side p-value test to isolate previously unseen processes as outlier events. Since the autoencoder training does not depend on any specific new physics signature, the proposed procedure has a weak dependence on underlying assumptions about the nature of new physics. An event selection based on this algorithm would be complementary to classic LHC searches, typically based on model-dependent hypothesis testing. Such an algorithm would deliver a list of anomalous events, that the experimental collaborations could further scrutinize and even release as a catalog, similarly to what is typically done in other scientific domains. Repeated patterns in this dataset could motivate new scenarios for beyond-the-standard-model physics and inspire new searches, to be performed on future data with traditional supervised approaches. Running in the trigger system of the LHC experiments, such an application could identify anomalous events that would be otherwise lost, extending the scientific reach of the LHC.
Topology classification with deep learning to improve real-time event selection at the LHC
Aug 01, 2018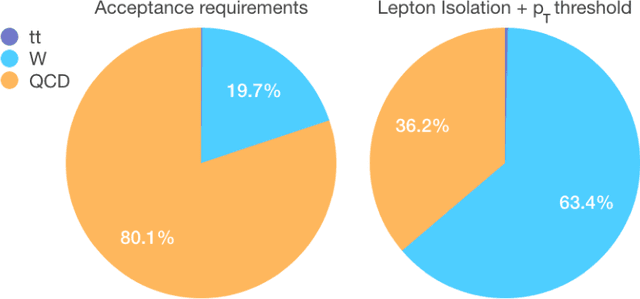
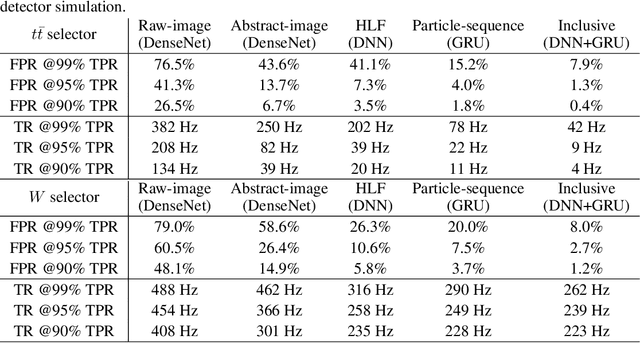
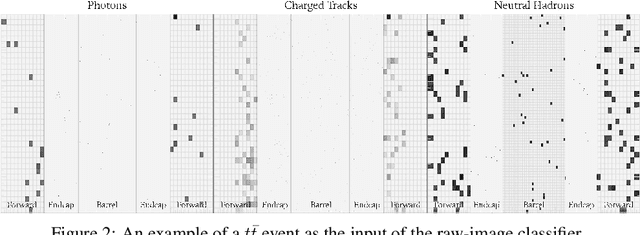
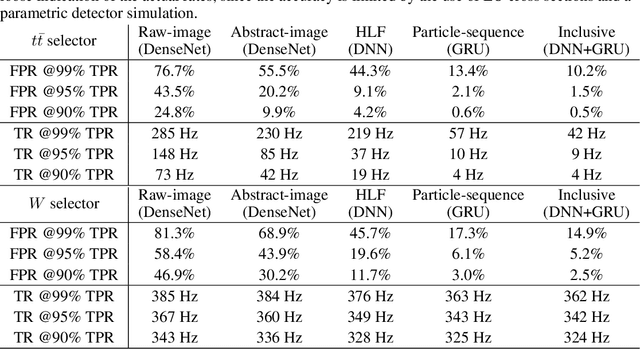
We show how event topology classification based on deep learning could be used to improve the purity of data samples selected in real time at at the Large Hadron Collider. We consider different data representations, on which different kinds of multi-class classifiers are trained. Both raw data and high-level features are utilized. In the considered examples, a filter based on the classifier's score can be trained to retain ~99% of the interesting events and reduce the false-positive rate by as much as one order of magnitude for certain background processes. By operating such a filter as part of the online event selection infrastructure of the LHC experiments, one could benefit from a more flexible and inclusive selection strategy while reducing the amount of downstream resources wasted in processing false positives. The saved resources could be translated into a reduction of the detector operation cost or into an effective increase of storage and processing capabilities, which could be reinvested to extend the physics reach of the LHC experiments.
An MPI-Based Python Framework for Distributed Training with Keras
Dec 16, 2017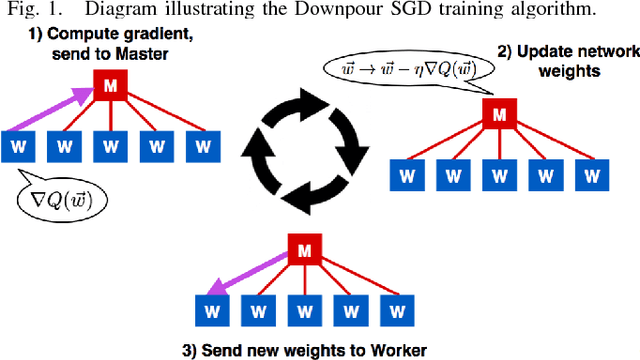
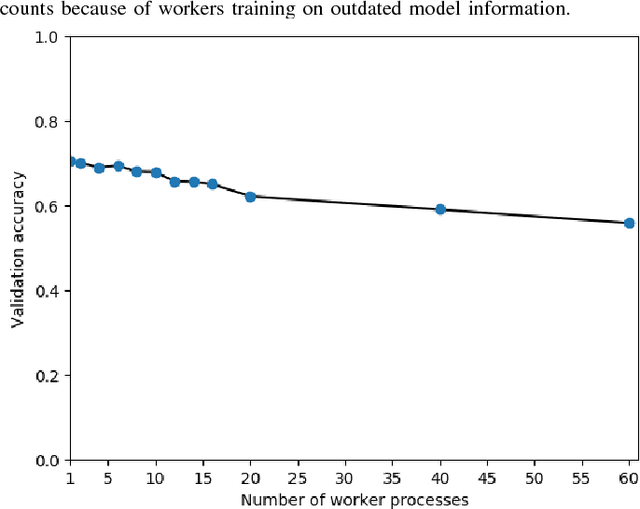
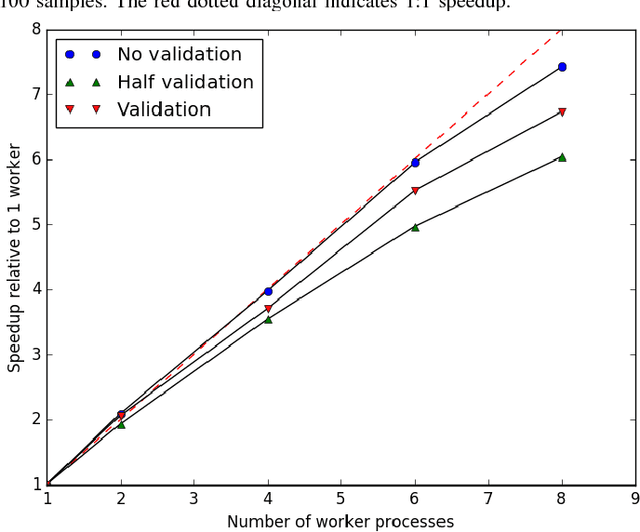
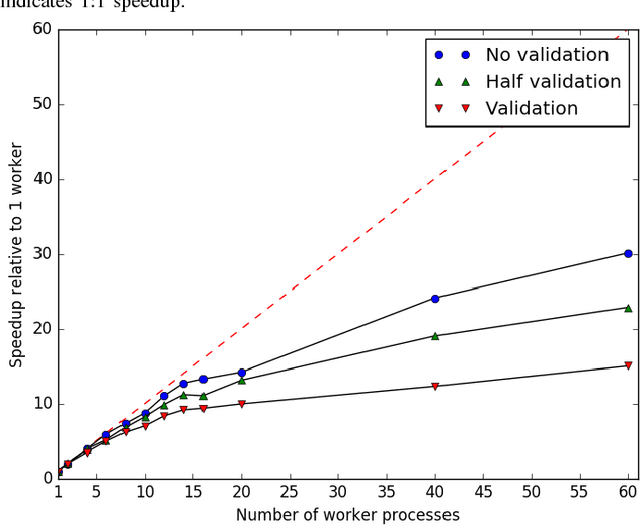
We present a lightweight Python framework for distributed training of neural networks on multiple GPUs or CPUs. The framework is built on the popular Keras machine learning library. The Message Passing Interface (MPI) protocol is used to coordinate the training process, and the system is well suited for job submission at supercomputing sites. We detail the software's features, describe its use, and demonstrate its performance on systems of varying sizes on a benchmark problem drawn from high-energy physics research.