 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Workflow to Efficiently Generate Dense Tissue Ground Truth Masks for Digital Breast Tomosynthesis
Apr 13, 2026Digital breast tomosynthesis (DBT) is now the standard of care for breast cancer screening in the USA. Accurate segmentation of fibroglandular tissue in DBT images is essential for personalized risk estimation, but algorithm development is limited by scarce human-delineated training data. In this study we introduce a time- and labor-saving framework to generate a human-annotated binary segmentation mask for dense tissue in DBT. Our framework enables a user to outline a rough region of interest (ROI) enclosing dense tissue on the central reconstructed slice of a DBT volume and select a segmentation threshold to generate the dense tissue mask. The algorithm then projects the ROI to the remaining slices and iteratively adjusts slice-specific thresholds to maintain consistent dense tissue delineation across the DBT volume. By requiring annotation only on the central slice, the framework substantially reduces annotation time and labor. We used 44 DBT volumes from the DBTex dataset for evaluation. Inter-reader agreement was assessed by computing patient-wise Dice similarity coefficients between segmentation masks produced by two radiologists, yielding a median of 0.84. Accuracy of the proposed method was evaluated by having a radiologist manually segment the 20th and 80th percentile slices from each volume (CC and MLO views; 176 slices total) and calculate Dice scores between the manual and proposed segmentations, yielding a median of 0.83.
$Δ$t-Mamba3D: A Time-Aware Spatio-Temporal State-Space Model for Breast Cancer Risk Prediction
Oct 21, 2025



Longitudinal analysis of sequential radiological images is hampered by a fundamental data challenge: how to effectively model a sequence of high-resolution images captured at irregular time intervals. This data structure contains indispensable spatial and temporal cues that current methods fail to fully exploit. Models often compromise by either collapsing spatial information into vectors or applying spatio-temporal models that are computationally inefficient and incompatible with non-uniform time steps. We address this challenge with Time-Aware $\Delta$t-Mamba3D, a novel state-space architecture adapted for longitudinal medical imaging. Our model simultaneously encodes irregular inter-visit intervals and rich spatio-temporal context while remaining computationally efficient. Its core innovation is a continuous-time selective scanning mechanism that explicitly integrates the true time difference between exams into its state transitions. This is complemented by a multi-scale 3D neighborhood fusion module that robustly captures spatio-temporal relationships. In a comprehensive breast cancer risk prediction benchmark using sequential screening mammogram exams, our model shows superior performance, improving the validation c-index by 2-5 percentage points and achieving higher 1-5 year AUC scores compared to established variants of recurrent, transformer, and state-space models. Thanks to its linear complexity, the model can efficiently process long and complex patient screening histories of mammograms, forming a new framework for longitudinal image analysis.
STA-Risk: A Deep Dive of Spatio-Temporal Asymmetries for Breast Cancer Risk Prediction
May 27, 2025Predicting the risk of developing breast cancer is an important clinical tool to guide early intervention and tailoring personalized screening strategies. Early risk models have limited performance and recently machine learning-based analysis of mammogram images showed encouraging risk prediction effects. These models however are limited to the use of a single exam or tend to overlook nuanced breast tissue evolvement in spatial and temporal details of longitudinal imaging exams that are indicative of breast cancer risk. In this paper, we propose STA-Risk (Spatial and Temporal Asymmetry-based Risk Prediction), a novel Transformer-based model that captures fine-grained mammographic imaging evolution simultaneously from bilateral and longitudinal asymmetries for breast cancer risk prediction. STA-Risk is innovative by the side encoding and temporal encoding to learn spatial-temporal asymmetries, regulated by a customized asymmetry loss. We performed extensive experiments with two independent mammogram datasets and achieved superior performance than four representative SOTA models for 1- to 5-year future risk prediction. Source codes will be released upon publishing of the paper.
Longitudinal Mammogram Exam-based Breast Cancer Diagnosis Models: Vulnerability to Adversarial Attacks
Oct 29, 2024



In breast cancer detection and diagnosis, the longitudinal analysis of mammogram images is crucial. Contemporary models excel in detecting temporal imaging feature changes, thus enhancing the learning process over sequential imaging exams. Yet, the resilience of these longitudinal models against adversarial attacks remains underexplored. In this study, we proposed a novel attack method that capitalizes on the feature-level relationship between two sequential mammogram exams of a longitudinal model, guided by both cross-entropy loss and distance metric learning, to achieve significant attack efficacy, as implemented using attack transferring in a black-box attacking manner. We performed experiments on a cohort of 590 breast cancer patients (each has two sequential mammogram exams) in a case-control setting. Results showed that our proposed method surpassed several state-of-the-art adversarial attacks in fooling the diagnosis models to give opposite outputs. Our method remained effective even if the model was trained with the common defending method of adversarial training.
Adversarially Robust Feature Learning for Breast Cancer Diagnosis
Feb 13, 2024



Adversarial data can lead to malfunction of deep learning applications. It is essential to develop deep learning models that are robust to adversarial data while accurate on standard, clean data. In this study, we proposed a novel adversarially robust feature learning (ARFL) method for a real-world application of breast cancer diagnosis. ARFL facilitates adversarial training using both standard data and adversarial data, where a feature correlation measure is incorporated as an objective function to encourage learning of robust features and restrain spurious features. To show the effects of ARFL in breast cancer diagnosis, we built and evaluated diagnosis models using two independent clinically collected breast imaging datasets, comprising a total of 9,548 mammogram images. We performed extensive experiments showing that our method outperformed several state-of-the-art methods and that our method can enhance safer breast cancer diagnosis against adversarial attacks in clinical settings.
Deep Curriculum Learning in Task Space for Multi-Class Based Mammography Diagnosis
Oct 21, 2021


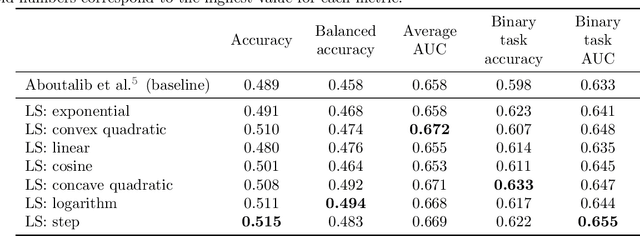
Mammography is used as a standard screening procedure for the potential patients of breast cancer. Over the past decade, it has been shown that deep learning techniques have succeeded in reaching near-human performance in a number of tasks, and its application in mammography is one of the topics that medical researchers most concentrate on. In this work, we propose an end-to-end Curriculum Learning (CL) strategy in task space for classifying the three categories of Full-Field Digital Mammography (FFDM), namely Malignant, Negative, and False recall. Specifically, our method treats this three-class classification as a "harder" task in terms of CL, and create an "easier" sub-task of classifying False recall against the combined group of Negative and Malignant. We introduce a loss scheduler to dynamically weight the contribution of the losses from the two tasks throughout the entire training process. We conduct experiments on an FFDM datasets of 1,709 images using 5-fold cross validation. The results show that our curriculum learning strategy can boost the performance for classifying the three categories of FFDM compared to the baseline strategies for model training.