 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWLV-RIT at HASOC-Dravidian-CodeMix-FIRE2020: Offensive Language Identification in Code-switched YouTube Comments
Nov 01, 2020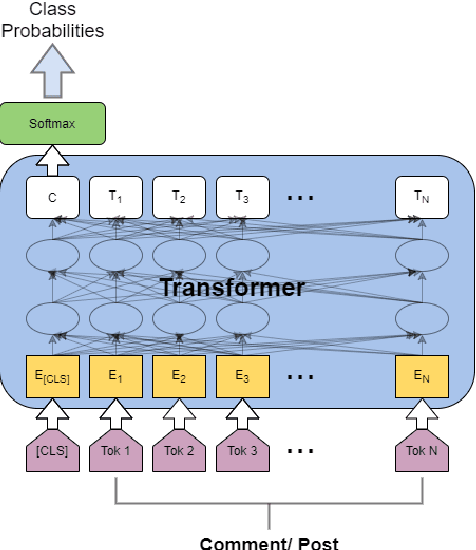
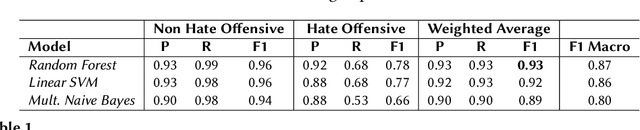
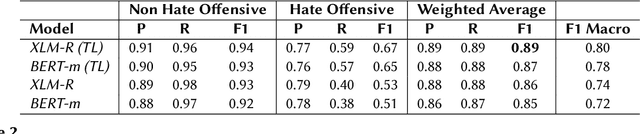
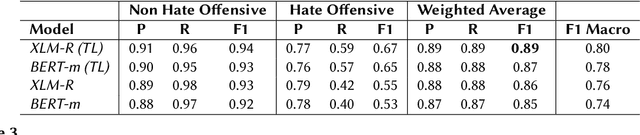
This paper describes the WLV-RIT entry to the Hate Speech and Offensive Content Identification in Indo-European Languages (HASOC) shared task 2020. The HASOC 2020 organizers provided participants with annotated datasets containing social media posts of code-mixed in Dravidian languages (Malayalam-English and Tamil-English). We participated in task 1: Offensive comment identification in Code-mixed Malayalam Youtube comments. In our methodology, we take advantage of available English data by applying cross-lingual contextual word embeddings and transfer learning to make predictions to Malayalam data. We further improve the results using various fine tuning strategies. Our system achieved 0.89 weighted average F1 score for the test set and it ranked 5th place out of 12 participants.
Multilingual Offensive Language Identification with Cross-lingual Embeddings
Oct 11, 2020
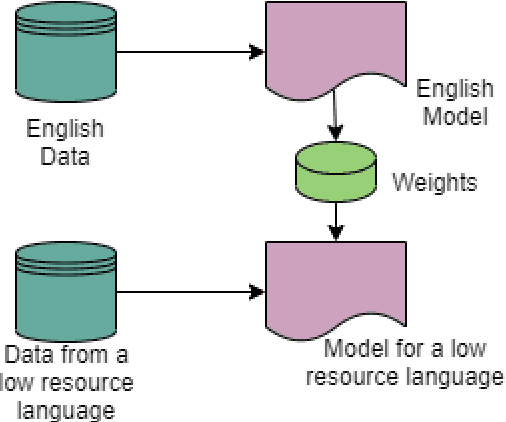
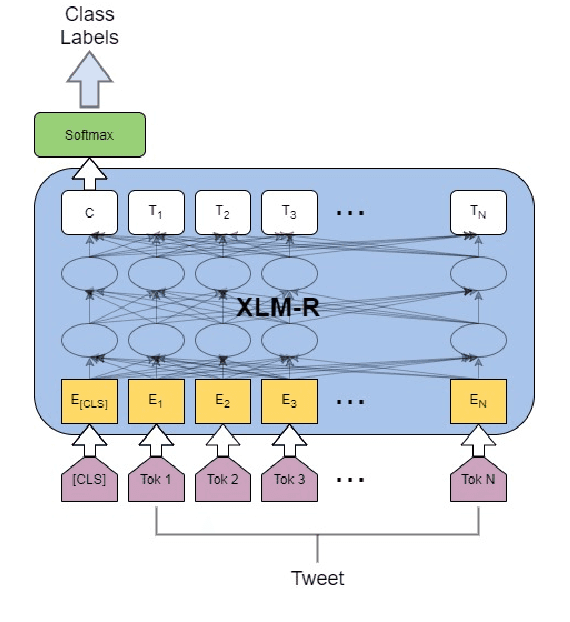
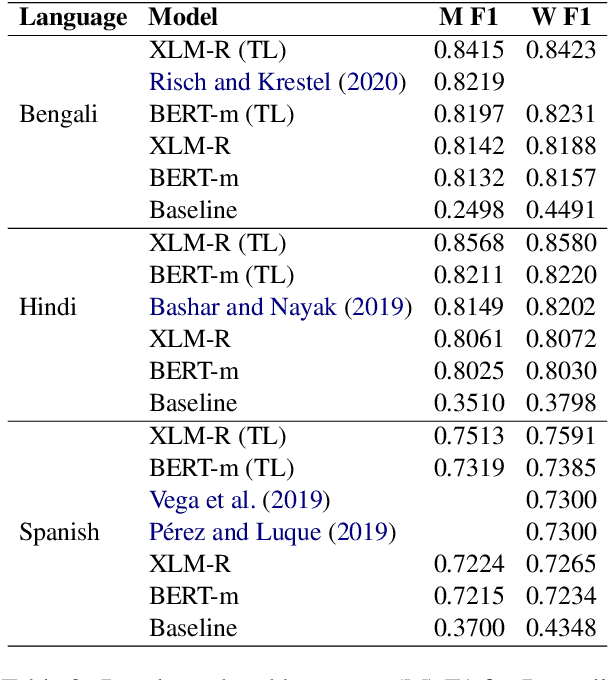
Offensive content is pervasive in social media and a reason for concern to companies and government organizations. Several studies have been recently published investigating methods to detect the various forms of such content (e.g. hate speech, cyberbulling, and cyberaggression). The clear majority of these studies deal with English partially because most annotated datasets available contain English data. In this paper, we take advantage of English data available by applying cross-lingual contextual word embeddings and transfer learning to make predictions in languages with less resources. We project predictions on comparable data in Bengali, Hindi, and Spanish and we report results of 0.8415 F1 macro for Bengali, 0.8568 F1 macro for Hindi, and 0.7513 F1 macro for Spanish. Finally, we show that our approach compares favorably to the best systems submitted to recent shared tasks on these three languages, confirming the robustness of cross-lingual contextual embeddings and transfer learning for this task.
SemEval-2020 Task 12: Multilingual Offensive Language Identification in Social Media (OffensEval 2020)
Jun 12, 2020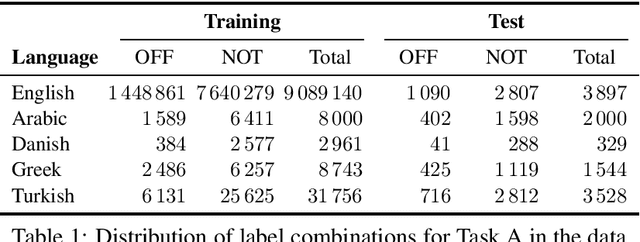
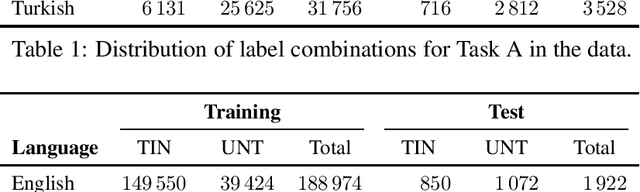
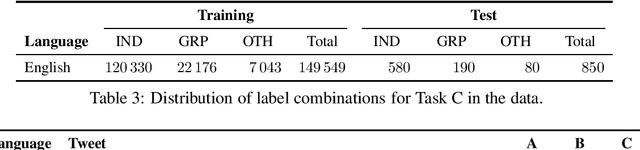

We present the results and main findings of SemEval-2020 Task 12 on Multilingual Offensive Language Identification in Social Media (OffensEval 2020). The task involves three subtasks corresponding to the hierarchical taxonomy of the OLID schema (Zampieri et al., 2019a) from OffensEval 2019. The task featured five languages: English, Arabic, Danish, Greek, and Turkish for Subtask A. In addition, English also featured Subtasks B and C. OffensEval 2020 was one of the most popular tasks at SemEval-2020 attracting a large number of participants across all subtasks and also across all languages. A total of 528 teams signed up to participate in the task, 145 teams submitted systems during the evaluation period, and 70 submitted system description papers.
MaintNet: A Collaborative Open-Source Library for Predictive Maintenance Language Resources
May 25, 2020
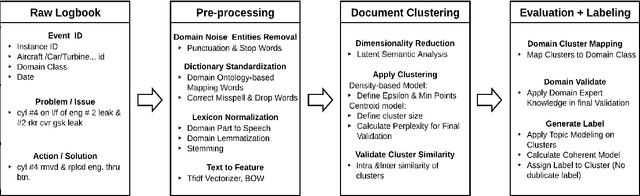

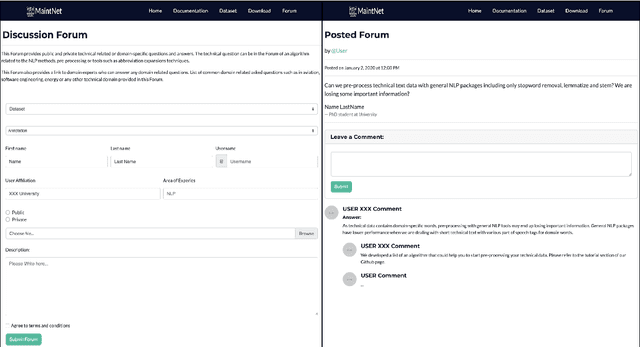
Maintenance record logbooks are an emerging text type in NLP. They typically consist of free text documents with many domain specific technical terms, abbreviations, as well as non-standard spelling and grammar, which poses difficulties to NLP pipelines trained on standard corpora. Analyzing and annotating such documents is of particular importance in the development of predictive maintenance systems, which aim to provide operational efficiencies, prevent accidents and save lives. In order to facilitate and encourage research in this area, we have developed MaintNet, a collaborative open-source library of technical and domain-specific language datasets. MaintNet provides novel logbook data from the aviation, automotive, and facilities domains along with tools to aid in their (pre-)processing and clustering. Furthermore, it provides a way to encourage discussion on and sharing of new datasets and tools for logbook data analysis.
A Large-Scale Semi-Supervised Dataset for Offensive Language Identification
Apr 29, 2020
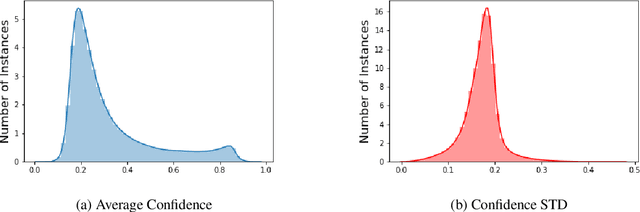
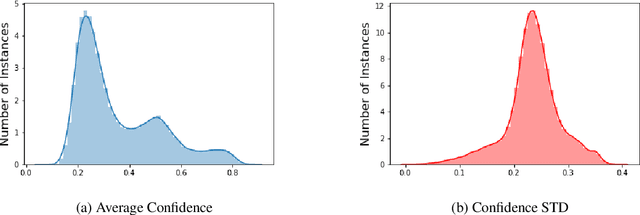
The use of offensive language is a major problem in social media which has led to an abundance of research in detecting content such as hate speech, cyberbulling, and cyber-aggression. There have been several attempts to consolidate and categorize these efforts. Recently, the OLID dataset used at SemEval-2019 proposed a hierarchical three-level annotation taxonomy which addresses different types of offensive language as well as important information such as the target of such content. The categorization provides meaningful and important information for understanding offensive language. However, the OLID dataset is limited in size, especially for some of the low-level categories, which included only a few hundred instances, thus making it challenging to train robust deep learning models. Here, we address this limitation by creating the largest available dataset for this task, SOLID. SOLID contains over nine million English tweets labeled in a semi-supervised manner. We further demonstrate experimentally that using SOLID along with OLID yields improved performance on the OLID test set for two different models, especially for the lower levels of the taxonomy. Finally, we perform analysis of the models' performance on easy and hard examples of offensive language using data annotated in a semi-supervised way.
Assessing Human Translations from French to Bambara for Machine Learning: a Pilot Study
Mar 31, 2020

We present novel methods for assessing the quality of human-translated aligned texts for learning machine translation models of under-resourced languages. Malian university students translated French texts, producing either written or oral translations to Bambara. Our results suggest that similar quality can be obtained from either written or spoken translations for certain kinds of texts. They also suggest specific instructions that human translators should be given in order to improve the quality of their work.
Offensive Language Identification in Greek
Mar 18, 2020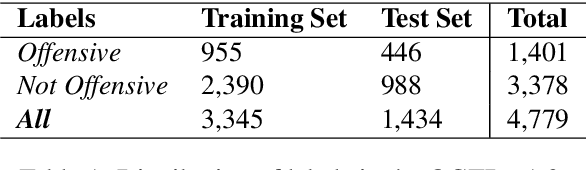
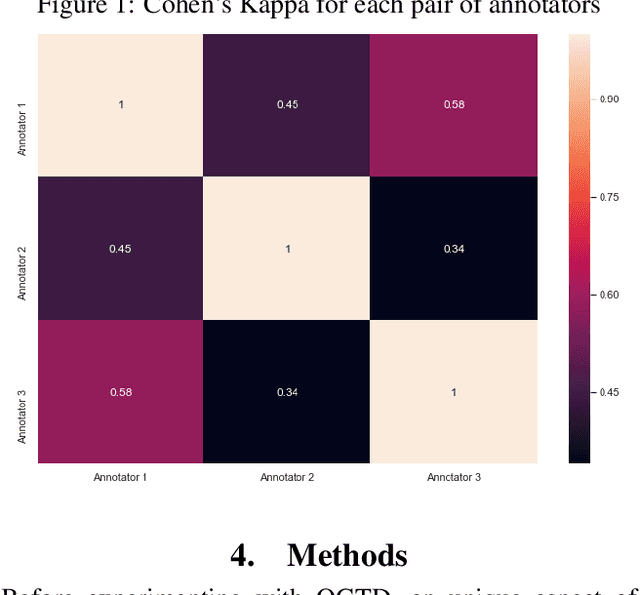
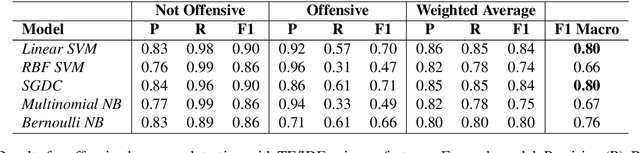
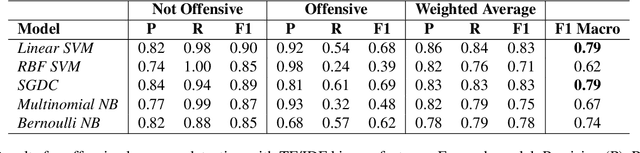
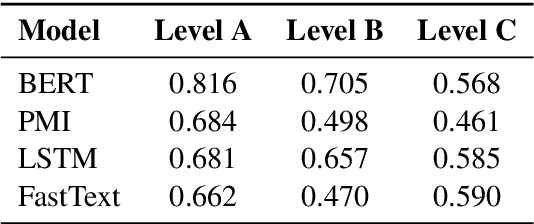
As offensive language has become a rising issue for online communities and social media platforms, researchers have been investigating ways of coping with abusive content and developing systems to detect its different types: cyberbullying, hate speech, aggression, etc. With a few notable exceptions, most research on this topic so far has dealt with English. This is mostly due to the availability of language resources for English. To address this shortcoming, this paper presents the first Greek annotated dataset for offensive language identification: the Offensive Greek Tweet Dataset (OGTD). OGTD is a manually annotated dataset containing 4,779 posts from Twitter annotated as offensive and not offensive. Along with a detailed description of the dataset, we evaluate several computational models trained and tested on this data.
CompLex --- A New Corpus for Lexical Complexity Predicition from Likert Scale Data
Mar 16, 2020
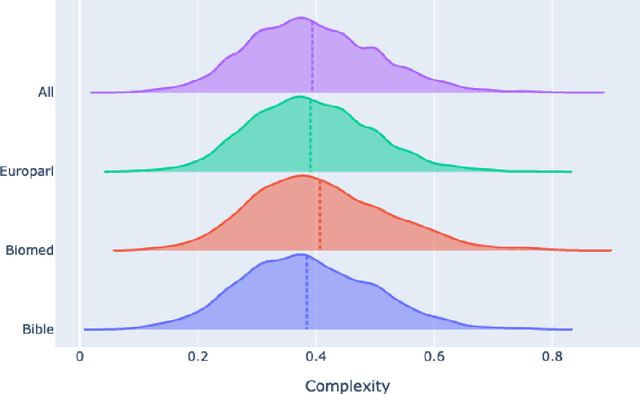
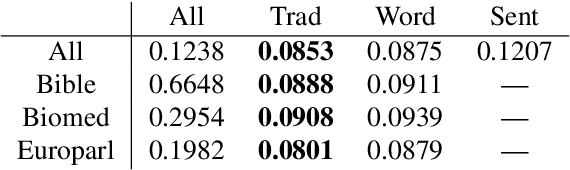
Predicting which words are considered hard to understand for a given target population is a vital step in many NLP applications such as text simplification. This task is commonly referred to as Complex Word Identification (CWI). With a few exceptions, previous studies have approached the task as a binary classification task in which systems predict a complexity value (complex vs. non-complex) for a set of target words in a text. This choice is motivated by the fact that all CWI datasets compiled so far have been annotated using a binary annotation scheme. Our paper addresses this limitation by presenting the first English dataset for continuous lexical complexity prediction. We use a 5-point Likert scale scheme to annotate complex words in texts from three sources/domains: the Bible, Europarl, and biomedical texts. This resulted in a corpus of 9,476 sentences each annotated by around 7 annotators.
Improving CAT Tools in the Translation Workflow: New Approaches and Evaluation
Aug 16, 2019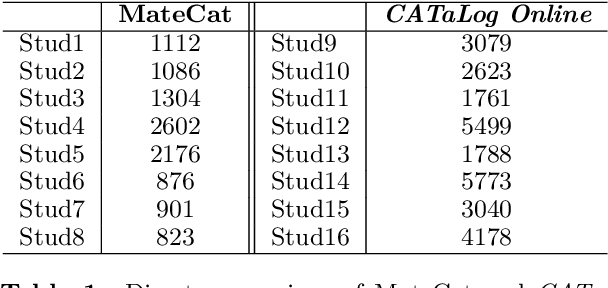
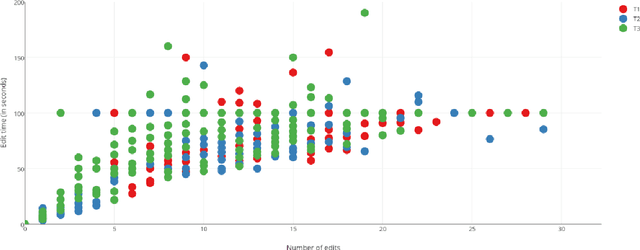
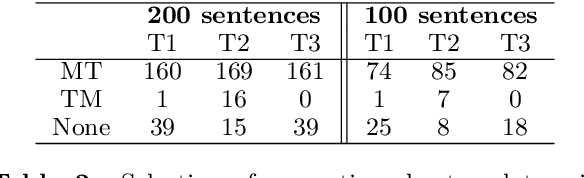

This paper describes strategies to improve an existing web-based computer-aided translation (CAT) tool entitled CATaLog Online. CATaLog Online provides a post-editing environment with simple yet helpful project management tools. It offers translation suggestions from translation memories (TM), machine translation (MT), and automatic post-editing (APE) and records detailed logs of post-editing activities. To test the new approaches proposed in this paper, we carried out a user study on an English--German translation task using CATaLog Online. User feedback revealed that the users preferred using CATaLog Online over existing CAT tools in some respects, especially by selecting the output of the MT system and taking advantage of the color scheme for TM suggestions.
UDS--DFKI Submission to the WMT2019 Similar Language Translation Shared Task
Aug 16, 2019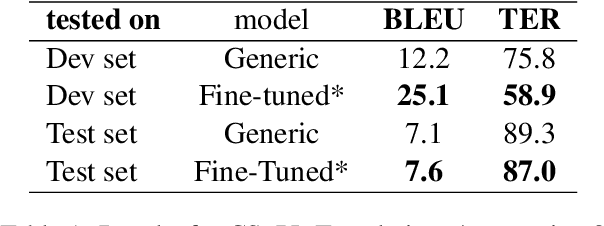
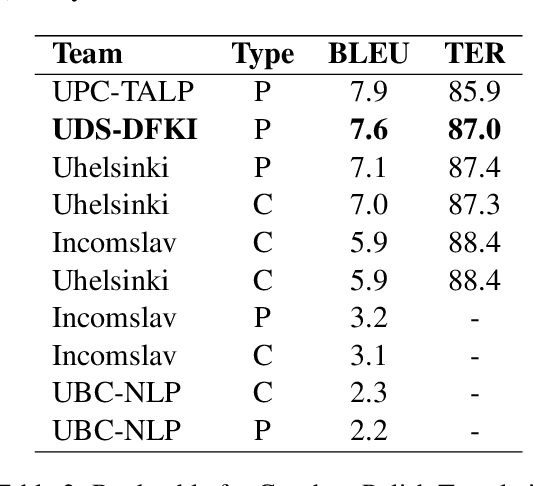
In this paper we present the UDS-DFKI system submitted to the Similar Language Translation shared task at WMT 2019. The first edition of this shared task featured data from three pairs of similar languages: Czech and Polish, Hindi and Nepali, and Portuguese and Spanish. Participants could choose to participate in any of these three tracks and submit system outputs in any translation direction. We report the results obtained by our system in translating from Czech to Polish and comment on the impact of out-of-domain test data in the performance of our system. UDS-DFKI achieved competitive performance ranking second among ten teams in Czech to Polish translation.