 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwistBytes -- Hierarchical Classification at GermEval 2019: walking the fine line (of recall and precision)
Aug 18, 2019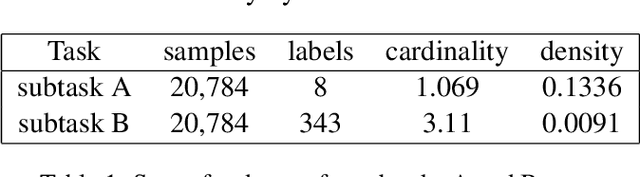
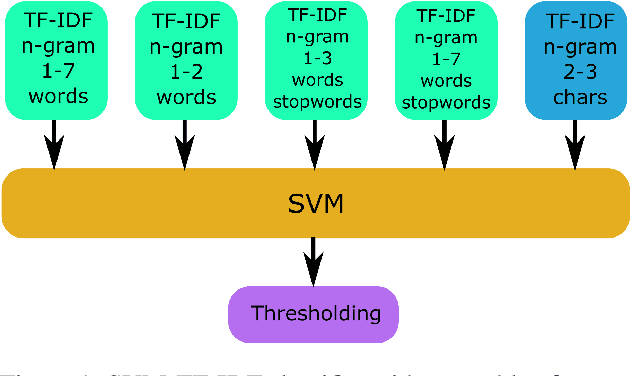
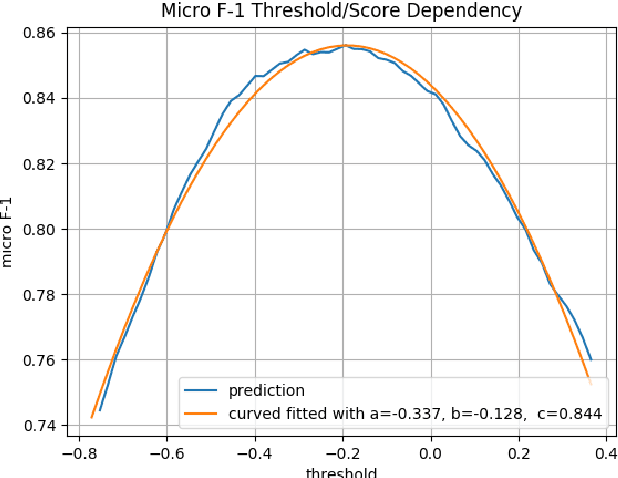
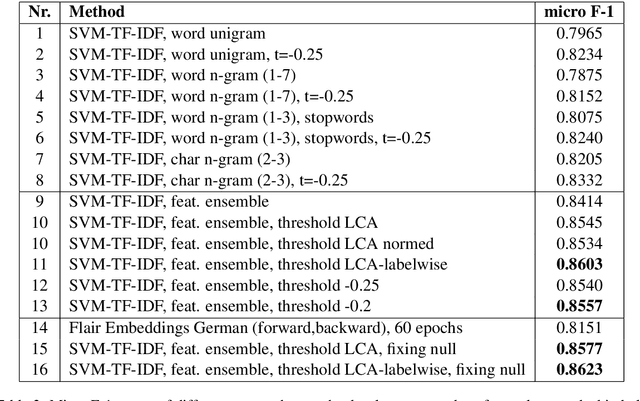
We present here our approach to the GermEval 2019 Task 1 - Shared Task on hierarchical classification of German blurbs. We achieved first place in the hierarchical subtask B and second place on the root node, flat classification subtask A. In subtask A, we applied a simple multi-feature TF-IDF extraction method using different n-gram range and stopword removal, on each feature extraction module. The classifier on top was a standard linear SVM. For the hierarchical classification, we used a local approach, which was more light-weighted but was similar to the one used in subtask A. The key point of our approach was the application of a post-processing to cope with the multi-label aspect of the task, increasing the recall but not surpassing the precision measure score.
Classifying Patent Applications with Ensemble Methods
Nov 12, 2018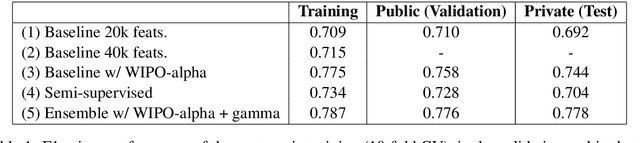
We present methods for the automatic classification of patent applications using an annotated dataset provided by the organizers of the ALTA 2018 shared task - Classifying Patent Applications. The goal of the task is to use computational methods to categorize patent applications according to a coarse-grained taxonomy of eight classes based on the International Patent Classification (IPC). We tested a variety of approaches for this task and the best results, 0.778 micro-averaged F1-Score, were achieved by SVM ensembles using a combination of words and characters as features. Our team, BMZ, was ranked first among 14 teams in the competition.